
Análise comparativa de 4 modelos de sobrevivência para pré-pagamento
Comparação de Cox, Weibull, Log-Normal e mistura Bernoulli–Beta para prever e calibrar o pré-pagamento em empréstimos bancários brasileiros.

Visão geral
O pré-pagamento de empréstimos — a quitação antecipada antes do vencimento — é um comportamento crucial no mercado de crédito, pois afeta diretamente o fluxo de caixa das instituições e a precificação dos produtos. Este estudo, documentado no repositório pq_prepayment_behavior, aplica modelos de análise de sobrevivência ao comportamento de pré-pagamento em empréstimos bancários brasileiros.
Tratamos o problema como um tempo-até-evento com censura: contratos que não pré-pagam dentro do horizonte de análise permanecem censurados. Adota-se, de forma deliberada, a simplificação de não modelar riscos competitivos (por exemplo, inadimplência). Essa decisão isola o pré-pagamento para comparar metodologias com mais nitidez, mas deve ser considerada em aplicações de produção. O gerador de dados sintéticos foi discutido em outro artigo; aqui, o foco é modelagem, ajuste e validação.
Avaliamos quatro abordagens de tempo-até-evento: um modelo semiparamétrico (Cox) e três paramétricos (Weibull, Log-Normal e um modelo de mistura Bernoulli-Beta). Todos foram ajustados e comparados em um conjunto sintético de empréstimos com características realistas (taxas de juros, renda, credit score etc.) e avaliados fora da amostra.
As covariáveis consideradas, usuais em crédito, foram sete: spread sobre a Selic, credit score, valor do empréstimo (log), prazo (meses), DTI, renda (log) e presença de colateral. O objetivo preditivo é estimar a probabilidade de pré-pagar em um horizonte fixo (por exemplo, 24 meses), gerando probabilidades calibradas para uso em precificação, gestão de portfólio e planejamento de liquidez.
Os quatro modelos
Cox semiparamétrico
O modelo de Cox assume que a taxa instantânea de evento (hazard) para um contrato com covariáveis X é
onde h₀(t) é a hazard de base (de forma não paramétrica) e β é o vetor de coeficientes. Assim, os efeitos das covariáveis entram multiplicativamente sobre a base e são proporcionais ao longo do tempo (COX, 1972). Não se impõe forma funcional para h₀(t), razão pela qual o modelo é semiparamétrico. Abaixo, a função de sobrevivência.
A baseline h₀(t) fica não paramétrica, e os efeitos das covariáveis entram multiplicativamente (COX, 1972). Em outras palavras, o modelo de Cox assume que as covariáveis têm efeitos proporcionais no hazard (daí o termo riscos proporcionais), mas não assume nada sobre a forma temporal de h₀(t), tornando-o semiparamétrico.
Hazard é a taxa instantânea de ocorrência do evento em um dado tempo, condicionada à sobrevivência até ali; indica quão iminente está o evento.
A estimação foca apenas em β, via verossimilhança parcial, que compara a ordem dos tempos de evento condicionada às covariáveis, sem precisar modelar h₀(t). Uma vez obtido β, estima-se a base para derivar a sobrevivência
A interpretação é direta: cada coeficiente β representa o log do hazard ratio associado à covariável xⱼ (mantidas as demais constantes). Logo, exp(βⱼ) é o fator pelo qual o hazard se multiplica quando xⱼ aumenta uma unidade — facilitando leitura de efeito e comunicação de resultado.
O modelo foi ajustado por verossimilhança parcial no conjunto de treino, usando um algoritmo quasi-Newton (BFGS/NR) com critérios de convergência em gradiente e variação da função objetivo. Aplicamos penalização L2 leve para estabilidade e redução de multicolinearidade. Empates nos tempos de evento foram tratados pela aproximação de Breslow; a hazard cumulativa de base foi estimada pelo estimador de Breslow e, a partir dela, derivamos a curva de sobrevivência de base para gerar predições. Erros-padrão vieram da informação observada, e as predições utilizadas nas métricas correspondem à probabilidade de pré-pagamento até o horizonte considerado (24 meses) calculado a partir da sobrevivência estimada.
Weibull AFT
O modelo Weibull em forma AFT (Accelarated Failure Time) trata o logaritmo do tempo até o evento como uma combinação linear das covariáveis mais um termo de dispersão. Na prática, isso significa que as covariáveis aceleram ou desaceleram o relógio do contrato: valores positivos no preditor alongam o tempo típico até o pré-pagamento; negativos o encurtam. A distribuição Weibull impõe uma hazard monotônica ao longo do tempo — crescente quando o parâmetro de forma (shape) é maior que 1, decrescente quando é menor que 1 e constante no caso limite (exponencial). Essa característica o torna adequado quando o risco de pré-pagamento evolui de maneira simples (só aumenta ou só diminui) ao longo da vida do contrato.
No AFT, as covariáveis entram no preditor de log-tempo. Assim, um aumento unitário em uma covariável com coeficiente multiplica o tempo típico (por exemplo, a mediana) por exp(βⱼ). O parâmetro de forma (k) controla o formato da hazard e o de escala (exp β…) ajusta o nível do tempo. Essa leitura “em tempo” é especialmente útil para comunicação com áreas de negócio: “um aumento de X no spread prolonga (ou encurta) o tempo até o pré-pagamento em Y%”.
Estimamos os parâmetros por máxima verossimilhança com censura, usando otimização numérica (Nelder–Mead seguida de BFGS) e regularização L2 leve para estabilizar coeficientes em presença de multicolinearidade. Inicializamos os parâmetros com valores plausíveis (coeficientes próximos de zero e dispersão moderada) e impusemos limites simples para evitar soluções degeneradas. O procedimento convergiu de forma estável no split de treino, produzindo um modelo rápido de predição e com custo de treinamento baixo.
O Weibull AFT funciona bem quando há evidência de hazard monotônica (por exemplo, risco crescente à medida que o saldo cai e o cliente ganha opção de refinanciar). Se os dados sugerirem picos intermediários de risco, distribuições mais flexíveis (p.ex., Log-Normal) ou abordagens semiparamétricas (Cox) tendem a calibrar melhor. Como benchmark paramétrico, o Weibull é valioso pela simplicidade, interpretabilidade em termos de tempo e boa eficiência computacional — desde que suas suposições de forma não sejam claramente violadas.
Log-Normal AFT
O Log-Normal AFT modela o logaritmo do tempo até o evento como um preditor linear nas covariáveis somado a um erro Normal. Em termos práticos, as covariáveis estendem ou encurtam o tempo típico até o pré-pagamento (interpretação por time ratio), enquanto o parâmetro de dispersão controla a variabilidade dos tempos. Diferentemente do Weibull, o Log-Normal admite hazard não monotônica (em geral cresce até um pico e depois decai), o que é útil quando o risco de pré-pagamento tende a concentrar-se em períodos intermediários do ciclo de vida do contrato.
No AFT, cada coeficiente βⱼ é lido como um fator multiplicativo no tempo: exp(βⱼ) indica de quanto o tempo típico se multiplica quando xⱼ aumenta uma unidade (mantidas as demais variáveis). A mediana do tempo, por exemplo, cresce ou diminui proporcionalmente:
O parâmetro σ governa a dispersão logarítmica: valores maiores implicam caudas mais longas e maior heterogeneidade entre contratos.
Estimamos os parâmetros por máxima verossimilhança com censura, combinando a densidade Normal (para eventos) e a função de sobrevivência Normal (para censurados). Para melhorar a convergência, inicializamos β via OLS sobre ln T (ignorando a censura apenas para obter um chute) e σ pelo desvio-padrão residual; em seguida, otimizamos com métodos numéricos (Nelder–Mead seguido de BFGS), aplicando regularização L2 leve para estabilizar coeficientes em presença de multicolinearidade e impondo restrições simples em σ (positividade e faixas plausíveis). Também adotamos rotinas numericamente estáveis para calcular a sobrevivência Normal em caudas (evitando cancelamento numérico em 1−Φ(⋅)1. O resultado é um modelo rápido de treinar e barato de prever.
O Log-Normal AFT tende a calibrar melhor do que modelos de hazard monotônica quando há pico intermediário de risco; por outro lado, é mais sensível a outliers em ln T e à escolha de inicialização. Em termos de comunicação, a leitura por tempo (time ratio) costuma ser intuitiva para o negócio; porém, ao contrário do Cox, não há uma interpretação direta em hazard ratios, já que o Log-Normal não pertence à classe de riscos proporcionais.
Mistura Bernoulli–Beta (fração “curada”)
Em muitas carteiras, uma parcela dos contratos simplesmente não pré-paga dentro do horizonte analisado. O modelo de “cura por mistura” incorpora explicitamente essa heterogeneidade: em vez de forçar todos os contratos a terem um tempo de evento, ele separa a propensão a ocorrer o evento do momento em que ele ocorre, caso ocorra (BOAG, 1949; FAREWELL, 1982).
Operacionalmente, estimamos uma probabilidade individual pᵢ de “pré-pagamento eventual” por meio de uma regressão logística com preditor γ⊤xᵢ. Esse componente captura “quem” tende a pré-pagar, permitindo que (1−pᵢ) represente, de forma clara, a “fração curada” — contratos que não pré-pagarão no horizonte.
Condicionalmente à ocorrência do evento, modelamos quando ele acontece usando o tempo relativo Yᵢ=Tᵢ/prazoᵢ ∈ (0,1). Escolhemos uma distribuição Beta para Yᵢ porque ela é flexível o bastante para descrever riscos concentrados no início, meio ou fim do prazo. Os seus parâmetros variam com as covariáveis por ligações logarítmicas, por exemplo ln αᵢ = η⊤xᵢ e ln βᵢ = ζ⊤xᵢ, o que permite que perfis distintos de clientes alterem tanto a média quanto a concentração do tempo relativo de pré-pagamento. Em termos de verossimilhança, cada observação que pré-paga contribui com
; já as censuradas, que completam o prazo sem evento, contribuem com
Esse desenho é parcimonioso e interpreta-se bem: o primeiro termo decide “se”, o segundo detalha “quando”.
O ajuste é feito por máxima verossimilhança com BFGS, combinando inicializações informadas para acelerar e estabilizar a convergência. Para o componente logístico, iniciamos pelo intercepto estimado a partir da frequência empírica de eventos e coeficientes próximos de zero; para a Beta, usamos momentos de Y observados para chutar α e β (ou, alternativamente, uma parametrização média–precisão (μ,ϕ)). Aplicamos regularização L2 leve nos vetores γ,η,ζ (preservando interceptos) para reduzir variância e mitigar multicolinearidade, e impusemos salvaguardas numéricas usuais: restrição de positividade para α,β, clamping de y em [ε,1−ε] quando necessário e rotinas estáveis para CDF e densidade da Beta em caudas.
A predição em um horizonte h (em meses) deriva de forma direta:
para 0 < h < prazoᵢ. Essa expressão sintetiza o ganho prático do modelo: probabilidades absolutas e calibráveis que reconhecem a existência de uma massa de contratos que não pré-pagará, ao mesmo tempo em que informam o timing esperado entre aqueles que o farão. Isso é particularmente útil para precificação (cálculo do prazo efetivo e do valor esperado), retenção (acionar ofertas nos períodos de maior risco previsto) e planejamento de liquidez. Abaixo, a função de sobrevivência.
Como todo modelo mais flexível, a mistura Bernoulli–Beta exige validação out-of-sample rigorosa e alguma parcimônia para evitar sobreajuste. É recomendável inspecionar calibração por faixas e comparar com alternativas (Cox, Weibull, Log-Normal) em splits fora-da-amostra e, idealmente, out-of-time. Em aplicações de produção, a extensão natural é combiná-lo com um tratamento de riscos competitivos (por exemplo, default), seja por um modelo conjunto de causas, seja por pipelines coordenados, para que as projeções de fluxo e preço reflitam de forma completa o ecossistema de eventos que encerram contratos.
Ajustes, validação, métricas e resultados
Como já especificado, utilizamos covariáveis, isso quer dizer que para as características dos contratos são levadas em consideração em vez de adotar um simplificação do comportamente médio, isso é importante, por exemplo, para fazer uma precificação mais condizente de que acordo com cada contrato ou para prever o as consequências de determinado desbalanceamento nos perfis dos contratos.
Outro aspecto importante é que sensibilidade aos juros foi representada pela covariável spread_over_selic — o custo do contrato acima da Selic na originação — incluída em todos os modelos como principal proxy do incentivo ao refinanciamento. Escolheu-se o spread (e não a taxa nominal) para evitar multicolinearidade e manter interpretabilidade; aplicou-se ainda regularização L2 leve nos ajustes. No Cox, o coeficiente do spread multiplica a hazard (β>0 ⇒ maior spread ⇒ maior risco de pré-pagamento mais cedo); nos AFT (Weibull e Log-Normal), ele atua como time ratio (exp(β) alonga/encurta o tempo típico até o evento); e, na Bernoulli–Beta, entra tanto na propensão a pré-pagar (logística) quanto no timing (parâmetros da Beta), afetando “quem” pré-paga e “quando”. Deve-se notar que o efeito foi tratado estaticamente (na originação), não como covariável tempo-variante; para capturar choques de Selic ao longo do ciclo, seria preciso modelar spread(t)/ΔSelic(t) como variante no tempo ou rodar cenários recalculando o spread e atualizando as predições.
Treinamos todos os modelos no mesmo particionamento de dados (2.100 contratos para treino e 900 para teste), usando otimização numérica — uma etapa inicial com Nelder–Mead para localizar bons pontos e, em seguida, BFGS para refinar — com checagens de convergência e regularização leve quando apropriado.
As predições avaliadas correspondem à probabilidade de pré-pagar em 24 meses, que é o horizonte de negócio adotado. A qualidade preditiva foi medida por três critérios complementares. O C-Index captura a discriminação (quão bem o modelo ordena quem pré-paga antes de quem não pré-paga), servindo como análogo da AUC em horizonte fixo (HARRELL et al., 1982); quanto maior, melhor. O Brier Score é o erro quadrático médio das probabilidades previstas, refletindo simultaneamente acurácia e calibração (BRIER, 1950); quanto menor, melhor. Por fim, o erro de calibração resume, em média por faixas de probabilidade, o desalinhamento entre o que foi previsto e o que ocorreu; também aqui, menor é melhor.
Como precificação depende de probabilidades absolutas bem calibradas (e não apenas do ranking relativo), adotamos um critério composto que pondera Brier (50%), calibração (30%) e C-Index (20%), priorizando, portanto, métricas que afetam diretamente o valor esperado dos fluxos (STEYERBERG et al., 2010).
No conjunto de teste (900 contratos), os resultados foram os seguintes.
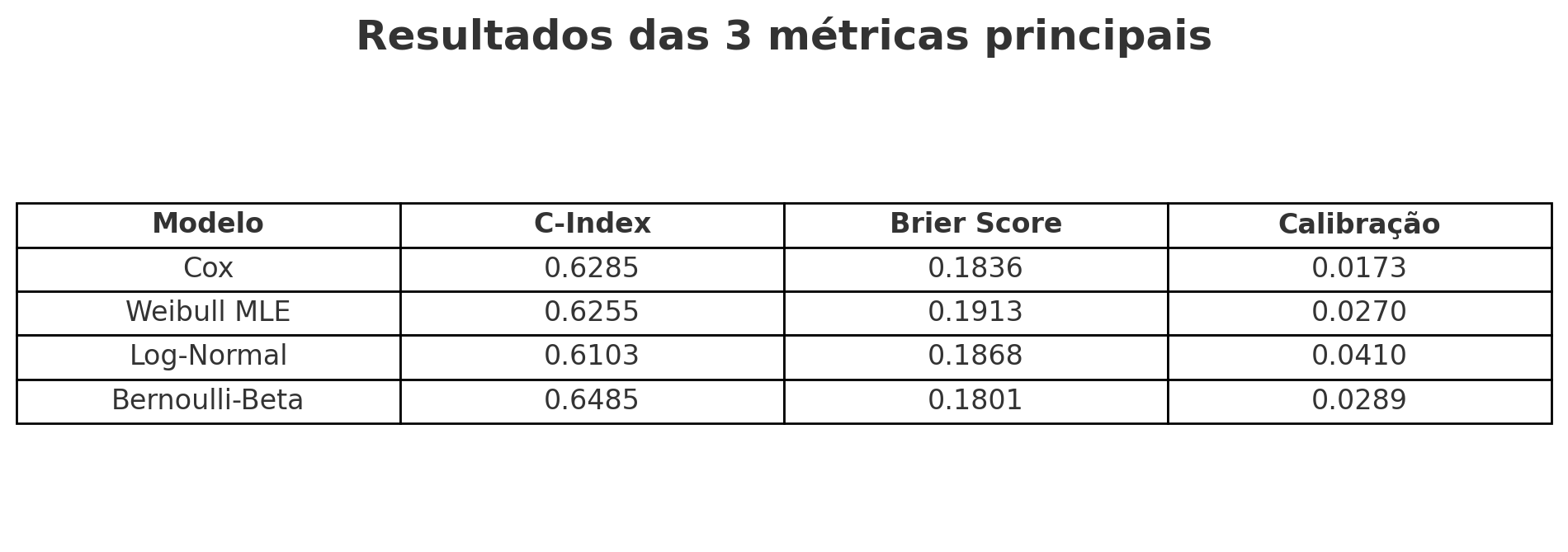
Em discriminação, a Bernoulli-Beta lidera, seguida por Cox e Weibull muito próximos, com Log-Normal atrás. Em acurácia global (Brier), a Bernoulli-Beta novamente é a melhor, com o Cox logo em seguida; o Weibull apresenta o pior desempenho. Em calibração, o destaque é o Cox, bastante alinhado às frequências observadas; Weibull e Bernoulli-Beta vêm na sequência, enquanto o Log-Normal exibe o maior desvio.
Aplicando o critério composto de precificação, a hierarquia fica clara: Bernoulli-Beta 0,853, Cox 0,841, Log-Normal 0,391 e Weibull 0,369. Assim, a recomendação para precificação no caso analisado é a Bernoulli-Beta, com o Cox como alternativa robusta e simples de operacionalizar.
A leitura de negócio por trás dessas escolhas é direta. Calibração e Brier governam o valor esperado dos contratos: se o modelo subestima a probabilidade de pré-pagamento, superestima o prazo efetivo e subprecifica; se superestima o pré-pagamento, o preço tende a ficar acima do necessário, reduzindo competitividade.
O C-Index é especialmente útil para segmentação e retenção (identificar perfis mais propensos a pré-pagar) e pode apoiar diferenciação de preço; porém, sem boa calibração, essa diferenciação erra no nível.
A vantagem da Bernoulli-Beta decorre da flexibilidade: ao permitir uma fração curada e modelar o timing via distribuição Beta, ela evita vieses estruturais de modelos que, na prática, “forçam” todos a pré-pagar em algum momento.
O Cox atinge excelente calibração graças à baseline livre, mas não representa explicitamente a massa que nunca pré-paga.
Weibull e Log-Normal são benchmarks úteis e computacionalmente econômicos; contudo, suas suposições de forma da hazard (monotônica no Weibull; não monotônica específica no Log-Normal) limitaram o ajuste e a calibração nos dados avaliados.
Limitações, próximos passos e conclusão
A principal limitação deste estudo é não tratar riscos competitivos: em produção, o pré-pagamento deve ser modelado em conjunto com default — seja por um Cox de causas competitivas ou por modelos paramétricos multicausa —, ou ainda por dois modelos coordenados (um para pré-pagamento, outro para default) com acoplamento consistente nos fluxos e perdas.
Outros avanços naturais incluem incorporar covariáveis tempo-variantes, aplicar recalibração pós-treino (isotônica/Platt) para manter o nível probabilístico em linha com novas coortes, realizar validações out-of-time e comparar com métodos de ML para sobrevivência (survival forests, gradient boosting adaptado).
Em carteiras reais, a escolha entre Bernoulli-Beta e Cox deve equilibrar ganho preditivo, simplicidade e explicabilidade. Nos dados analisados, a Bernoulli-Beta entregou o melhor compromisso entre discriminação, acurácia e calibração para precificação, com o Cox muito próximo e líder em calibração. A mensagem prática é direta: para precificar corretamente, probabilidades bem calibradas importam tanto quanto — ou mais do que — a capacidade de ranquear contratos. Modelos que reconhecem explicitamente uma fração que não pré-paga e descrevem o timing do evento geram projeções de fluxo mais fiéis e preços mais adequados.
Referências
BOAG, J. W. (1949). Maximum likelihood estimates of the proportion of patients cured by cancer therapy. JRSS B, 11, 15–44.
BRIER, G. W. (1950). Verification of forecasts expressed in terms of probability. Monthly Weather Review, 78(1), 1–3.
COX, D. R. (1972). Regression models and life-tables. JRSS B, 34(2), 187–220.
FAREWELL, V. T. (1982). The use of mixture models for the analysis of survival data with long-term survivors. Biometrics, 38(4), 1041–1046.
HARRELL, F. E. Jr. et al. (1982). Evaluating the yield of medical tests. JAMA, 247(18), 2543–2546.
KALBFLEISCH, J. D.; PRENTICE, R. L. (2002). The Statistical Analysis of Failure Time Data (2ª ed.). Wiley.
STEYERBERG, E. W. et al. (2010). Assessing the performance of prediction models. Epidemiology, 21(1), 128–138.