
LLMs como pesquisadores: uma abordagem estruturada para ciência de dados automatizada
Como a separação entre definição do problema e motor de pesquisa transforma modelos de linguagem em cientistas de dados iterativos

Em março de 2026, Andrej Karpathy publicou o autoresearch, um script Python de 630 linhas capaz de rodar centenas de experimentos de aprendizado de máquina em um único fim de semana, sem intervenção humana. Em dois dias sobre uma base de código já otimizada, o agente executou cerca de 700 experimentos, encontrou 20 melhorias genuínas e transferiu um ganho de 11% em velocidade de treinamento para modelos maiores. O CEO da Shopify replicou o processo e obteve 19% de ganho durante uma noite (KARPATHY, 2026). A reação foi imediata: mais de 21 mil estrelas no GitHub em dias, e a frase de Karpathy no X, “todos os laboratórios de fronteira farão isso”, circulou como profecia inevitável.
Quase ao mesmo tempo, a Sakana AI publicou a segunda versão do AI Scientist (LU et al., 2024; YAMADA et al., 2025), um pipeline que percorre o ciclo completo da pesquisa científica, da geração de ideias à redação de artigos, incluindo execução de experimentos e revisão simulada por pares. O AIDE, da Weco AI, demonstrou que um agente baseado em busca em árvore no espaço de código podia alcançar quatro vezes a taxa de medalhas do melhor agente autônomo seguinte em 75 competições Kaggle (JIANG et al., 2025). O MLAgentBench propôs um benchmark sistemático para avaliar agentes de linguagem no ciclo completo de experimentação em aprendizado de máquina (HUANG et al., 2024).
Essas iniciativas compartilham uma ambição comum: substituir o ciclo manual hipótese-experimento-análise por um laço autônomo. Mas todas operam com uma limitação estrutural que raramente é discutida. O autoresearch de Karpathy modifica iterativamente o arquivo train.py de um problema já definido e instrumentado. O AI Scientist gera artigos dentro de subáreas estreitas de aprendizado de máquina, e seus revisores automatizados classificaram apenas um trabalho como aceitável para workshop (LU et al., 2024). O AIDE busca soluções em competições Kaggle cujo formato é padronizado. Em todos os casos, a definição do problema, a construção do target, os critérios de validade e o significado do resultado ficam de fora do laço automatizado. O LLM executa bem a busca dentro de um espaço já delimitado, mas a delimitação permanece humana.
Este artigo propõe uma abordagem diferente, desenvolvida pelo autor e testada em um problema real de finanças quantitativas. Em vez de automatizar apenas o código de treinamento, a proposta separa o problema em dois documentos com responsabilidades distintas, PROBLEM.md e PROGRAM.md, e entrega ao LLM um contrato de pesquisa completo: definição formal do target, regras de validação, critérios de promoção, restrições causais e política de parada. O resultado é um agente que não apenas treina modelos, mas formula hipóteses, registra aprendizados, critica seus próprios resultados e sabe quando parar. Para demonstrar a abordagem, aplicamos esse processo ao IRCC, um índice de risco comportamental do cotista para fundos multimercado brasileiros. O foco aqui, porém, não está no problema financeiro em si, mas no método que permitiu a um LLM conduzi-lo do zero até uma solução operacional em seis waves de experimentação.
A arquitetura: separar o que do como
A abordagem proposta se materializa em quatro componentes, todos de autoria do analista humano, que juntos formam o contrato entre quem define o problema e o agente que o investiga.
O primeiro componente é o PROBLEM.md. Esse documento funciona como um contrato de tarefa que define, com precisão, o que está sendo otimizado. Ele especifica o target e sua construção, as fontes de dados permitidas e proibidas, o protocolo de validação, as métricas primárias e secundárias, os guardrails, os riscos de vazamento (leakage), os riscos de variáveis proxy e pós-tratamento, e, quando aplicável, um contrato causal completo com perguntas prioritárias, escopo de DAG (grafo acíclico direcionado, a ferramenta padrão para representar relações de causa e efeito entre variáveis) e regras de interpretação. O PROBLEM.md do IRCC, por exemplo, contém 189 linhas e 52 campos contratuais, desde TASK_TYPE: classification até COUNTERFACTUAL_REQUIREMENT. O humano escreve esse documento antes do primeiro experimento. O LLM não pode alterá-lo.
O segundo componente é o PROGRAM.md. Esse documento define como a pesquisa é conduzida: fases do laço iterativo, regras de planejamento de waves, papéis internos do agente (cientista, engenheiro, crítico e auditor de validade), formato dos registros, critérios de promoção de candidatos a champion e condições de parada. O PROGRAM.md é genérico. Ele não menciona fundos de investimento, fluxo de caixa nem mercado financeiro. Poderia ser aplicado a qualquer problema supervisionado, desde previsão de churn até detecção de fraude ou classificação de imagens médicas, bastando trocar o PROBLEM.md.
O terceiro componente é o train.py, um script de baseline obrigatório. Antes de qualquer exploração, o agente executa esse script para estabelecer um piso reproduzível de desempenho. No caso do IRCC, o baseline é uma regressão logística com pesos balanceados sobre todas as features numéricas brutas, avaliada por purged K-Fold expanding window com cinco folds e purga de 44 dias úteis. O baseline ancora todas as comparações subsequentes e impede que o agente declare progresso sem referência concreta.
O quarto componente é o diretório data/, que contém os dados e o dicionário de dados (DATA_DICTIONARY.md). O dicionário lista cada variável com tipo, fonte e descrição, servindo como contrato de interface entre o problema e a implementação.
O PROGRAM.md é o componente que impede o agente de se comportar como otimizador cego, porque exige quatro papéis internos a cada iteração: o Scientist lê o registro de experimentos e formula hipóteses explícitas; o Engineer implementa o menor experimento capaz de testá-las; o Critic separa sinal de ruído e classifica cada hipótese como suportada, refutada ou inconclusiva; o Validity Critic audita vazamento, variáveis proxy, pós-tratamento e fragilidade temporal. Nenhum experimento pode existir sem hipótese prévia, e nenhuma wave pode terminar sem síntese.
Comparação com abordagens existentes
A diferença em relação ao autoresearch de Karpathy não está na sofisticação do modelo, mas na amplitude do contrato. O autoresearch opera como um laço de otimização sobre um único arquivo: modifica train.py, treina por cinco minutos, verifica se a métrica de validação melhorou, faz commit das boas mudanças e reverte as ruins (KARPATHY, 2026). O problema já está resolvido no sentido de que a métrica, o dataset e o protocolo de validação são dados. Aqui, o LLM recebe também a responsabilidade de entender por que uma hipótese falhou, de classificar blocos de features por papel causal, de decidir se o champion é promovível mesmo quando seu score é o melhor, e de justificar a parada pelo registro de aprendizados, não por impressão subjetiva.
A diferença em relação ao AI Scientist (LU et al., 2024) é de escopo e veracidade. O AI Scientist produz artigos completos, mas seus revisores automatizados não conseguem distinguir gráficos malformados de resultados válidos, e a qualidade do raciocínio experimental foi descrita como “míope” na versão original. A abordagem aqui proposta não tenta redigir o artigo: ela entrega evidência estruturada, hipóteses classificadas e artefatos causais verificáveis para que o humano interprete. O LLM faz a pesquisa; o humano faz o julgamento final.
O AIDE (JIANG et al., 2025) usa busca em árvore no espaço de código para competições Kaggle e maximiza uma métrica. O PROGRAM.md exige que a maximização passe por quatro portas antes de promover um candidato: desempenho, estabilidade, validade e custo. Um modelo que vence em score mas depende de variáveis com alto risco de pós-tratamento não pode ser promovido.
O problema demonstrativo: IRCC
Para ilustrar como essa arquitetura funciona, o problema escolhido foi a construção de um indicador antecedente de estresse de passivo em fundos de investimento brasileiros da classe Multimercado. A escolha não é arbitrária: o estresse de passivo é um dos riscos menos instrumentados na gestão de fundos, apesar de sua relevância. Quando cotistas resgatam em volume, o gestor precisa desmontar posições, às vezes em mercados ilíquidos, gerando perdas que retroalimentam novos resgates (COVAL; STAFFORD, 2007). A literatura documenta amplamente a assimetria da relação fluxo-desempenho: saídas são muito mais sensíveis a retornos negativos do que entradas a retornos positivos (CHEVALIER; ELLISON, 1997; SIRRI; TUFANO, 1998), e a fragilidade é especialmente aguda em fundos com ativos ilíquidos e base concentrada de cotistas (CHEN; GOLDSTEIN; JIANG, 2010; GOLDSTEIN; JIANG; NG, 2017).
O IRCC (Índice de Risco Comportamental do Cotista) é formulado como um problema de classificação binária supervisionada. O target não é o estado de estresse, mas o seu início (onset): o primeiro dia de um episódio de saída líquida relevante, definido como um drawdown de passivo superior a 1% do patrimônio líquido em 14 dias corridos. Cada observação é um par (CNPJ do fundo, data da decisão de resgate), com a data ajustada pelo prazo total de conversão e pagamento, de modo que o modelo prevê quando o cotista decidiu resgatar, não quando o dinheiro aparece no informe diário da CVM.
O target é construído em três camadas. A primeira calcula o drawdown de 14 dias normalizado pelo patrimônio líquido:
A segunda define o estado de estresse: raw_stress(t) = 1 se drawdown_14d(t) < −1%. A terceira identifica o início de cada episódio, com uma janela de ±2 dias úteis e um período de silêncio (cooldown) de 14 dias úteis entre episódios. O resultado é um target binário esparso, com prevalência entre 1% e 5%, que captura o momento em que um novo episódio de estresse começa a se formar.
O dataset utiliza exclusivamente dados públicos da CVM e fontes de mercado abertas, totalizando 5,8 milhões de observações e 82 variáveis antes da engenharia de features. O código completo, incluindo PROBLEM.md, PROGRAM.md, ledger e artefatos causais, está disponível em github.com/andrecamatta/pq_ircc. As famílias de sinal incluem fluxo histórico do fundo, performance recente da cota, composição da carteira, perfil do cotista, características estruturais de resgate, dados de mercado exógeno e sentimento sistêmico (incluindo Google Trends e dispersão das projeções Focus). A validação segue um purged K-Fold expanding window com cinco folds e purga de 44 dias úteis, e a métrica primária é o PR-AUC (área sob a curva precisão-recall), com ponderação exponencial entre folds, dando mais peso aos períodos recentes. A escolha dessa métrica, em vez da ROC-AUC mais comum, reflete a natureza do problema: quando a classe positiva representa menos de 5% das observações, a ROC-AUC pode parecer alta mesmo com modelos que acertam poucos eventos reais, porque o grande volume de negativos verdadeiros infla a taxa de verdadeiros negativos. A PR-AUC ignora os negativos verdadeiros e avalia apenas o quanto o modelo consegue encontrar os positivos sem inundar o gestor de alarmes falsos.
Como o LLM progrediu: seis waves de aprendizado
O LLM não recebeu instruções sobre qual modelo usar, quais features criar nem como calibrar hiperparâmetros. Recebeu quatro arquivos e um dataset. É o equivalente computacional de entregar a um consultor sênior o escopo do projeto, o dicionário de dados e a frase “nos vemos na sexta com os resultados”, com a diferença de que esse consultor não cobra por hora, não dorme e documenta cada decisão que toma. Em seis waves, rodou 25 experimentos, registrou cada hipótese em um ledger central e, ao final, sabia explicar por que parou. A tabela a seguir resume a conclusão de cada wave.
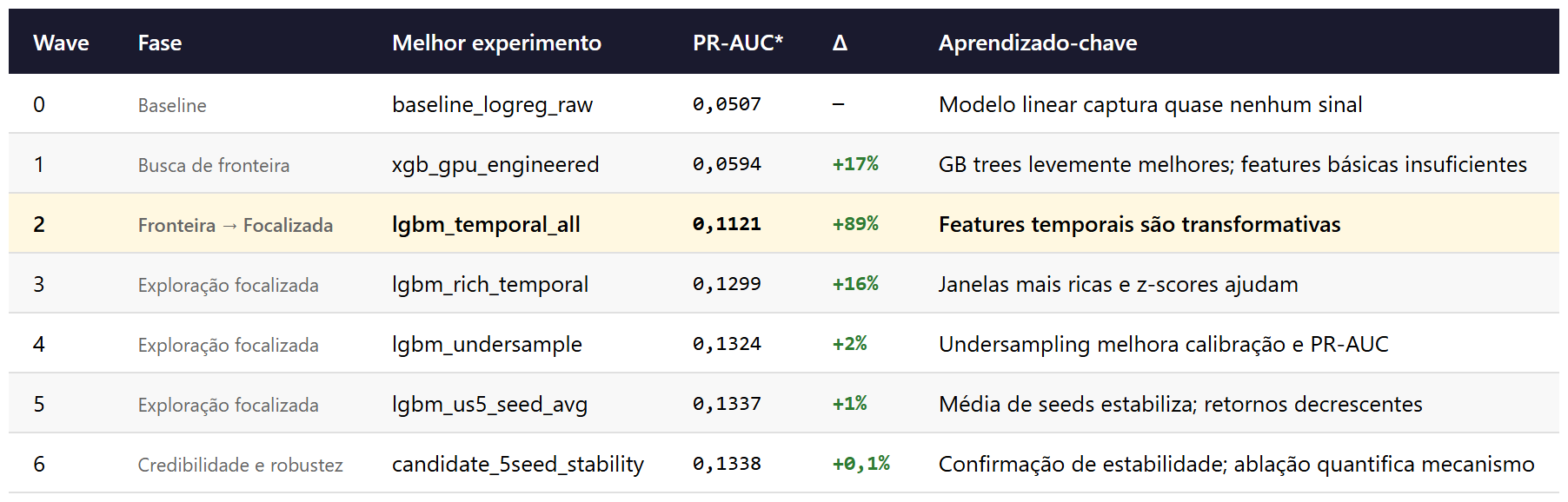
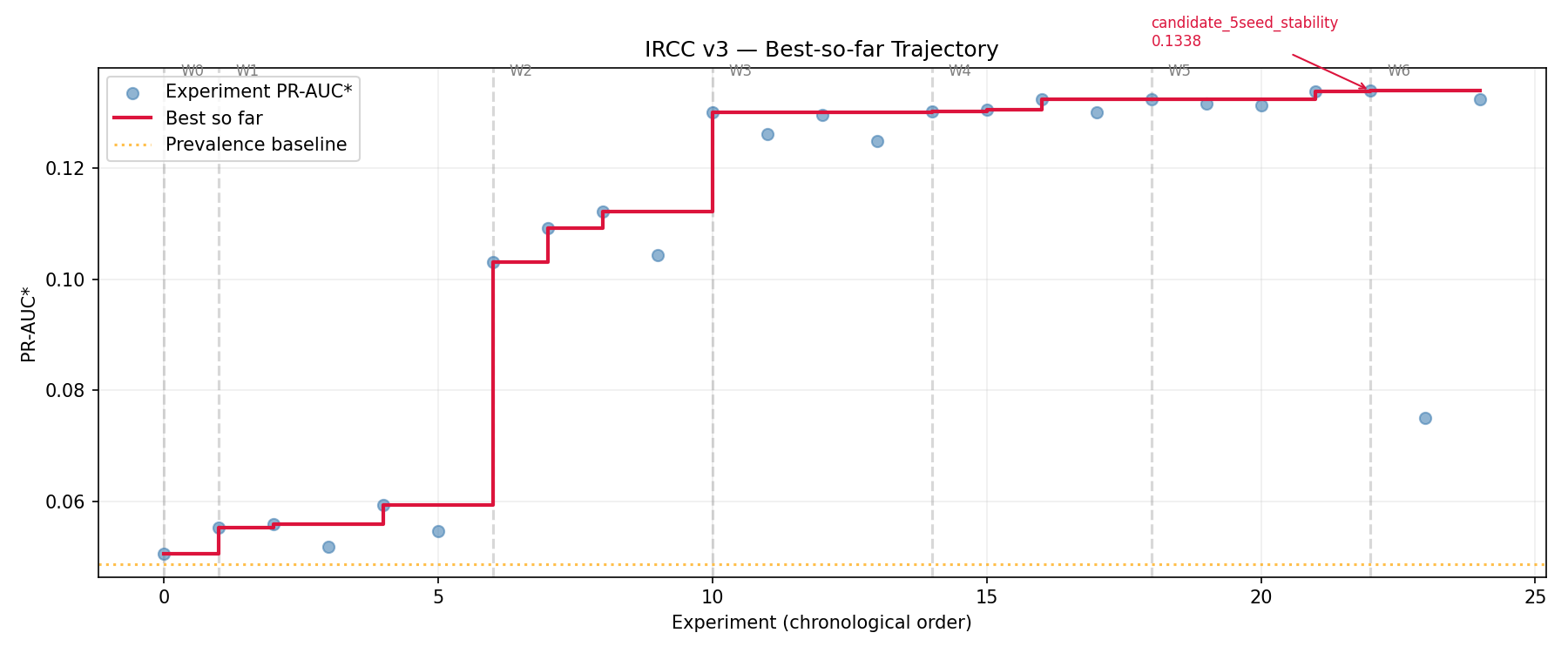
O ponto de inflexão ocorreu na wave 2. Até ali, o agente havia testado regressão logística, XGBoost e LightGBM sobre features de snapshot (brutas e engenheiradas) e concluído que gradient boosting era superior, mas que as variáveis disponíveis eram quase inúteis: o melhor PR-AUC* estava em 0,0594, próximo da prevalência. A decisão registrada na síntese da wave 1, “priorizar representação temporal, não variedade de modelos”, levou o agente a criar médias móveis de fluxo, acelerações de resgate, retornos acumulados, z-scores de performance e variações de mercado em múltiplas janelas. O PR-AUC* saltou para 0,1121 (+89%). Uma ablação mostrou que o fluxo sozinho carregava 92% do ganho.
As waves 3 a 5 exploraram três eixos sobre essa direção: representação (janelas mais ricas, z-scores de fluxo, interações), regime de treino (undersampling 5:1, que melhorou simultaneamente score e calibração) e capacidade (média de sementes, ensemble). A wave 4 merece nota porque o undersampling não apenas elevou o PR-AUC* para 0,1324, mas reduziu o Brier score de 0,16-0,20 para 0,06, um ganho de calibração relevante para o uso. O ensemble LightGBM + XGBoost, testado na wave 5, não superou o melhor individual.
A wave 6 confirmou a estabilidade do candidato (0,1338 contra 0,1337 da wave anterior), quantificou por ablação que 78% do sinal vem de features de fluxo, e reproduziu o baseline de undersampling com resultado idêntico. Com o platô confirmado, o agente declarou o critério de parada e passou à análise causal e de validade dos sinais que sustentam o modelo.
O PR-AUC* saiu de 0,0507 para 0,1338, uma melhoria de 164% sobre o baseline. Mas o valor da wave 6 não está no ganho marginal de 0,1% em score: está nos artefatos de validade que ela produziu, e que a seção seguinte examina.
Insights obtidos: o que o treinamento revelou sobre o IRCC
A análise de validade da wave 6 formalizou em um DAG com 11 nós conceituais os papéis causais de cada bloco de features, classificando-os por risco de proxy, risco de pós-tratamento e elegibilidade para a narrativa. Embora o foco deste artigo seja a abordagem metodológica, esses achados ilustram o tipo de evidência que o processo produz.
O achado dominante, já antecipado pela ablação da wave 6, é que features temporais de fluxo carregam cerca de 78% do sinal preditivo. Médias móveis de fluxo líquido em janelas de 3, 5, 10, 21, 63 e 126 dias, acelerações de resgate e z-scores de fluxo normalizado são, coletivamente, o motor do modelo. Sem essas variáveis, o PR-AUC* cai de 0,1338 para 0,075, perdendo a maior parte do poder discriminativo. Performance recente da cota contribui com cerca de 10% do sinal, dados de mercado e sentimento com 5%, e variáveis estruturais e de perfil do cotista com outros 5%.
O DAG da wave 6 classificou cada bloco por papel causal, robustez e elegibilidade para o uso.
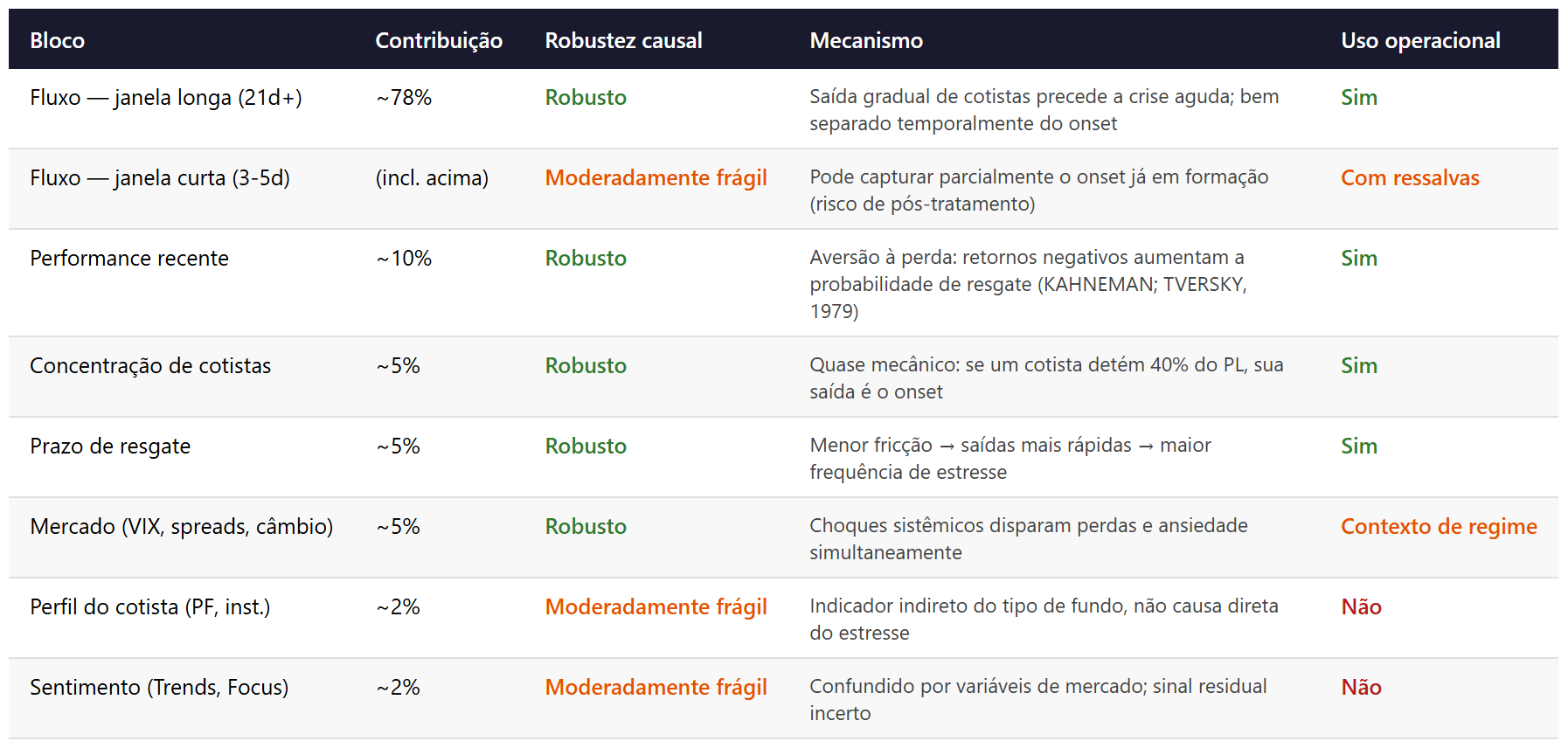
Fluxo de curto prazo (3 a 5 dias) é o caso mais delicado na tabela: embora preditivamente poderoso, pode capturar parcialmente o onset já em formação, configurando risco de pós-tratamento. A construção do dt_pedido (data ajustada pelo prazo de conversão e pagamento) mitiga, mas não elimina, esse risco em fundos com prazos de resgate muito curtos. O perfil do cotista (proporção de pessoa física, institucional, previdência) funciona como indicador indireto do tipo de fundo, não como causa do estresse: um fundo com 80% de cotistas pessoa física não sofre resgates por causa desse perfil, mas porque fundos assim tendem a ter menor prazo, maior sensibilidade a perdas e distribuição por plataformas de varejo. A variável é preditivamente útil, mas o mecanismo real está em outro lugar. Por fim, sentimento (Google Trends, dispersão Focus) é fortemente confundido por variáveis de mercado. Esses dois últimos blocos permanecem no modelo por valor preditivo, mas o processo explicitamente proíbe que sustentem narrativas isoladas.
Os guardrails definidos no PROBLEM.md também produziram aprendizado. A meta de precisão ≥ 30% em recall ≥ 50% não foi atingida (precisão observada de ~13% nesse ponto). Contudo, no topo de 3% das predições, o lift alcança 7-8 vezes a prevalência, indicando que o modelo é mais útil como ferramenta de priorização (quais fundos monitorar) do que como classificador binário rígido. A calibração por Brier score (0,056-0,068) é boa para ranking, mas os diagramas de confiabilidade mostram que o modelo superestima a probabilidade de onset nos bins superiores, sugerindo necessidade de recalibração (Platt ou isotônica) antes de usar probabilidades absolutas.
O que a abordagem muda para o cientista de dados
A mudança mais visível que a separação entre PROBLEM.md e PROGRAM.md produz é a inversão da alocação de tempo. No fluxo tradicional de ciência de dados, a maior parte do esforço humano concentra-se na implementação: escrever código de pré-processamento, treinar modelos, ajustar hiperparâmetros, iterar sobre features. A definição do problema, frequentemente, ocupa uma fração menor do tempo e fica implícita em decisões espalhadas pelo código. Com essa abordagem, o esforço humano concentra-se inteiramente na redação do PROBLEM.md: definir o target com precisão, especificar regras de validação, declarar riscos de validade e formular o contrato causal. A implementação é delegada ao LLM. O cientista de dados se torna, na prática, um especificador de contratos de pesquisa.
A segunda mudança é a formalização de restrições que normalmente ficam tácitas. Em projetos tradicionais, a distinção entre variáveis causais e proxies estruturais costuma residir na cabeça do analista sênior. Riscos de pós-tratamento são discutidos em reuniões, mas raramente codificados. Critérios de parada são subjetivos. O PROBLEM.md força a escrita explícita de todas essas restrições antes do primeiro experimento. O efeito colateral é que o documento serve como memória institucional: qualquer pessoa que leia o PROBLEM.md do IRCC entende exatamente o que o target captura, quais variáveis carregam quais riscos e por que certas features não podem sustentar as decisões.
A terceira mudança é a rastreabilidade do raciocínio. O ledger de 25 experimentos, com hipóteses, mecanismos esperados, sinais de falha, vereditos do crítico e notas de validade, constitui um registro completo da evolução do conhecimento ao longo do projeto. Em um fluxo tradicional, essa informação existe em cadernos Jupyter parcialmente comentados, em mensagens de Slack e na memória dos analistas. Aqui, ela é um artefato estruturado, auditável e reutilizável.
Essa rastreabilidade também impõe disciplina ao agente. O PROGRAM.md lista explicitamente antipadrões proibidos: tratar o laço como busca em grade, disparar waves sem análise intermediária, repetir ideias equivalentes sem nova justificativa, promover candidatos apenas por média agregada ignorando o fold crítico, declarar platô por intuição. Cada um desses antipadrões corresponde a um erro comum em projetos de ciência de dados conduzidos manualmente. A diferença é que, ao codificá-los como regras do motor de pesquisa, eles se tornam violações verificáveis, não apenas boas práticas que podem ou não ser seguidas.
Generalidade e limitações
A abordagem foi projetada para ser genérica. O PROGRAM.md não contém referências ao domínio financeiro, a fundos de investimento nem a variáveis específicas. Sua aplicabilidade depende de dois pré-requisitos: o problema precisa ser formulável como aprendizado supervisionado (classificação ou regressão) e o humano precisa ser capaz de escrever um PROBLEM.md suficientemente completo. A segunda condição é a mais restritiva. Um PROBLEM.md mal especificado, com target ambíguo, riscos de vazamento não declarados ou critérios de sucesso vagos, produzirá uma pesquisa automatizada igualmente vaga. A qualidade do processo é limitada pela qualidade do contrato.
A abordagem também herda limitações dos LLMs atuais. O agente não possui intuição genuína sobre o domínio: sua capacidade de formular hipóteses depende da combinação entre o PROBLEM.md e o conhecimento geral absorvido durante o pré-treinamento. Em domínios muito especializados ou com convenções não documentadas na literatura pública, o agente pode formular hipóteses superficiais ou perder oportunidades que um especialista identificaria. A wave 2 do IRCC ilustra tanto o potencial quanto a limitação: o agente “descobriu” que features temporais são transformativas, mas um especialista em risco de liquidez provavelmente teria começado por aí.
Outra limitação é computacional. O PROGRAM.md exige orçamento de 30 minutos por experimento e limita as waves a 3-6 experimentos, mas o custo total do laço inclui o tempo de inferência do LLM para formular hipóteses, escrever código, interpretar resultados e produzir sínteses. Em problemas com datasets grandes e modelos lentos, o custo acumulado pode ser significativo.
Há também uma tensão entre generalidade e profundidade causal. O PROGRAM.md inclui suporte para análise causal (DAG, conjuntos de ajuste, sensibilidade, contrafactuais), mas essa análise é qualitativa e baseada em argumentos de plausibilidade, não em identificação causal formal com limites de Rosenbaum ou E-valores. Para problemas onde a interpretação causal é o objetivo principal, a camada causal do processo serve como filtro de interpretações ruins, não como substituta para métodos quase-experimentais rigorosos.
Considerações finais
Que LLMs conseguem treinar modelos de aprendizado de máquina já está demonstrado em múltiplos contextos. A questão que importa é outra: a forma como o problema é apresentado ao LLM determina a qualidade da pesquisa resultante. Um LLM com acesso a train.py e uma métrica otimiza código. Um LLM com acesso a um contrato de pesquisa completo, com definição formal do target, restrições de validade, papéis internos de crítica e política de parada justificada, conduz algo mais próximo de ciência de dados.
O IRCC serviu como caso de teste, e os resultados são úteis: um modelo que melhora 164% sobre o baseline, com sinais primários causalmente robustos, calibração razoável e limitações explicitamente documentadas. Mas o artefato mais valioso do projeto não é o modelo final, é o ledger de 25 experimentos com hipóteses classificadas, o DAG causal com elegibilidade por bloco e a síntese por wave que permite a qualquer auditor reconstruir o raciocínio do processo.
O tempo investido em escrever um PROBLEM.md preciso, com riscos explícitos e critérios formais, retorna multiplicado pela capacidade do LLM de explorar o espaço de soluções com disciplina. O gargalo deixa de ser a implementação e passa a ser a especificação. E, como qualquer engenheiro sabe, especificações boas produzem sistemas melhores do que implementações heroicas sobre especificações vagas.
Referências
CHEN, Q.; GOLDSTEIN, I.; JIANG, W. Payoff complementarities and financial fragility: evidence from mutual fund outflows. Journal of Financial Economics, v. 97, n. 2, p. 239-262, 2010.
CHEVALIER, J.; ELLISON, G. Risk taking by mutual funds as a response to incentives. Journal of Political Economy, v. 105, n. 6, p. 1167-1200, 1997.
COVAL, J.; STAFFORD, E. Asset fire sales (and purchases) in equity markets. Journal of Financial Economics, v. 86, n. 2, p. 479-512, 2007.
GOLDSTEIN, I.; JIANG, H.; NG, D. T. Investor flows and fragility in corporate bond funds. Journal of Financial Economics, v. 126, n. 3, p. 592-613, 2017.
HUANG, Q. et al. MLAgentBench: evaluating language agents on machine learning experimentation. In: INTERNATIONAL CONFERENCE ON MACHINE LEARNING (ICML), 41., 2024. Proceedings [...]. PMLR 235, 2024.
JIANG, Z. et al. AIDE: AI-driven exploration in the space of code. arXiv:2502.13138, 2025.
KAHNEMAN, D.; TVERSKY, A. Prospect theory: an analysis of decision under risk. Econometrica, v. 47, n. 2, p. 263-291, 1979.
KARPATHY, A. autoresearch. GitHub, 2026. Disponível em: https://github.com/karpathy/autoresearch.
LU, C. et al. The AI Scientist: towards fully automated open-ended scientific discovery. arXiv:2408.06292, 2024.
YAMADA, Y. et al. The AI Scientist-v2: workshop-level automated scientific discovery via agentic tree search. arXiv:2504.08066, 2025.
SIRRI, E. R.; TUFANO, P. Costly search and mutual fund flows. The Journal of Finance, v. 53, n. 5, p. 1589-1622, 1998.