
O gado de Plymouth e os algoritmos quantitativos: a matemática da sabedoria das multidões
Como o concurso vitoriano de adivinhar o peso de um animal antecipou a decomposição de variância que sustenta Random Forests, portfólios de sinais fracos e ensembles de modelos de linguagem.

Plymouth, dezembro de 1906. Francis Galton, então com 84 anos, visita a West of England Fat Stock and Poultry Exhibition. Primo de Charles Darwin, Galton foi um dos arquitetos da estatística moderna (regressão à média, correlação, percentis) e também o fundador da eugenia. Tinha pouca simpatia por julgamentos populares. Em seus escritos, defendia abertamente que decisões importantes deveriam ficar a cargo de especialistas treinados. A multidão era, para ele, decoração no melhor dos casos e obstáculo no pior.
Naquela feira havia um concurso corriqueiro. Por seis pence, qualquer pessoa comprava um bilhete e palpitava o peso, em libras, de um animal já abatido e limpo. Açougueiros e fazendeiros participaram ao lado de balconistas, sapateiros e curiosos sem nenhum contato com gado. Galton viu ali a oportunidade perfeita para documentar, com números, a incompetência coletiva que pressupunha.
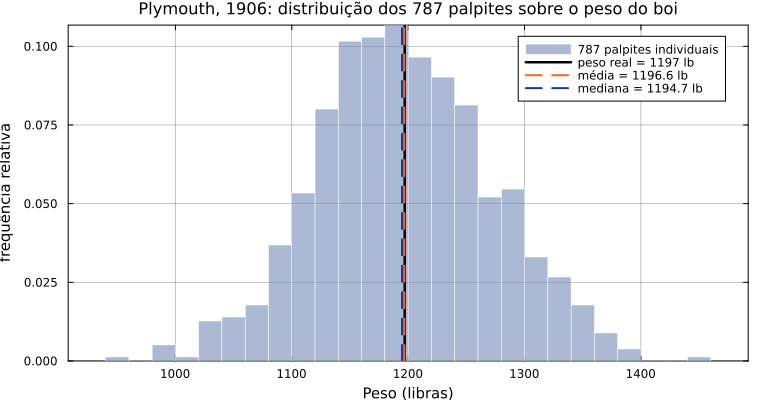
Após o concurso, ele obteve 787 bilhetes válidos (dos cerca de oitocentos emitidos, treze estavam ilegíveis) e calculou as estatísticas centrais da distribuição de palpites. O peso real do animal era 1.197 libras. A mediana dos palpites, segundo Galton, foi 1.207 libras, um erro de menos de 1%. Uma reanálise moderna das planilhas manuscritas, publicada por Wallis (2014), mostrou que a média aritmética dos 787 palpites coincide exatamente com as 1.197 libras do peso real. A multidão havia acertado com precisão microscópica, e o elitista Galton publicou a contragosto o artigo Vox Populi na Nature (GALTON, 1907).
O que Galton não tinha vocabulário para enunciar em 1907, mas sua amostra ilustrou, é uma identidade algébrica que hoje sustenta tradições aparentemente distintas de finanças quantitativas. Aparece em Random Forests treinadas para credit scoring, em portfólios sistemáticos de centenas de sinais fracos (weak alphas) e, mais recentemente, em arquiteturas Mixture of Experts usadas para processar texto financeiro em modelos de linguagem. Este artigo percorre o fio matemático comum e mostra, em Julia, por que o gado de Plymouth e um ensemble de 500 árvores de decisão são manifestações do mesmo princípio.
A identidade que Galton não escreveu
O concurso de Plymouth tinha 787 bilhetes, enquanto um modelo de credit scoring moderno tem milhões de árvores de decisão. Mesmo assim, a álgebra que liga os dois é a mesma, e cabe em duas linhas. Seja θ o valor verdadeiro da quantidade estimada (o peso do animal, o retorno futuro de uma ação, a probabilidade de default) e sejam c₁, c₂, …, cₙ as estimativas individuais dos n integrantes da multidão. A estimativa coletiva, por média simples, é c̄ = (1/n) Σ cᵢ.
Scott Page formalizou em 2007 o que chamou de Diversity Prediction Theorem (PAGE, 2007), uma identidade exata em erro quadrático:
Diversity Prediction Theorem (PAGE, 2007, paráfrase). O erro do coletivo, medido em desvio quadrático, é igual ao erro médio individual menos a diversidade preditiva do grupo (dispersão dos palpites em torno de sua média). A identidade é puramente algébrica, vale para qualquer amostra finita e independe de hipótese estatística sobre os palpiteiros.
O que essa identidade de duas linhas diz, lido com calma, é desconcertante. O erro coletivo nunca é maior que o erro individual médio, porque a diversidade é não-negativa e essa parcela só pode subtrair. E quando os palpites individuais se distribuem para os dois lados de θ com intensidades parecidas, a parcela de diversidade chega a absorver quase toda a parcela de erro, e o erro coletivo colapsa para perto de zero. O grupo não precisa de gênios, precisa de erros que se cancelam.
O Teorema do Júri de Condorcet, de 1785, já apontava nessa direção em contexto binário: se cada juiz tem probabilidade p > 0,5 de acertar e os julgamentos são independentes, a probabilidade de a maioria acertar tende a 1 quando o júri cresce. Page formalizou a versão contínua. Breiman (1996), dois séculos após Condorcet, reescreveu o mesmo princípio no vocabulário da decomposição bias-variância em ensembles de preditores:
Aqui σ² é a variância de cada preditor individual, ρ é a correlação média entre preditores e M é o tamanho do ensemble. Com ρ = 0 (independência perfeita), a variância cai com 1/M e o limite é zero. Com ρ > 0, existe um piso irremovível em ρσ², de modo que por mais modelos que se agregue, a variância residual não desce abaixo dele. A correlação entre preditores é, portanto, o inimigo estrutural da agregação. A proeza de Galton só foi possível porque os 787 palpites, feitos sem conversa prévia, eram aproximadamente descorrelacionados.
Reproduzindo Plymouth em Julia
Para tornar a identidade de Page concreta antes de migrar para finanças, simulamos 787 palpites em torno do peso verdadeiro, com ruído gaussiano de desvio-padrão 75 libras (calibração consistente com a dispersão de ±10% que Galton observou na amostra original). O código completo está no repositório pq_galton_ensemble.
Os resultados da simulação, com semente fixa, reproduzem qualitativamente o achado de 1906.
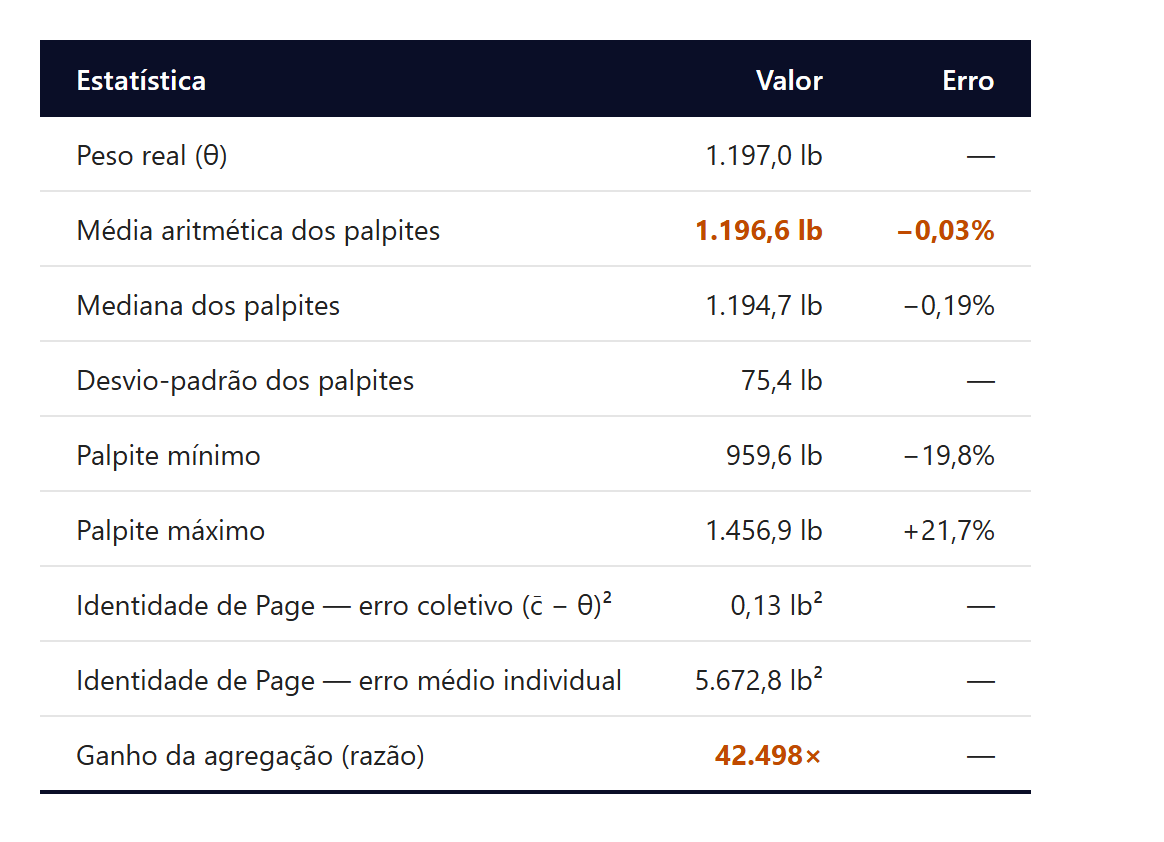
O erro coletivo (0,13 libras²) é 42 mil vezes menor que o erro médio individual (5.673 libras²). A diferença é absorvida pela diversidade preditiva, exatamente como a identidade de Page prevê. Note que nem a média nem a mediana precisam ser especialmente boas. O que importa é que os palpites individuais se distribuam de forma aproximadamente simétrica em torno de θ, com erros que se cancelam na agregação.
Bagging em finanças quantitativas
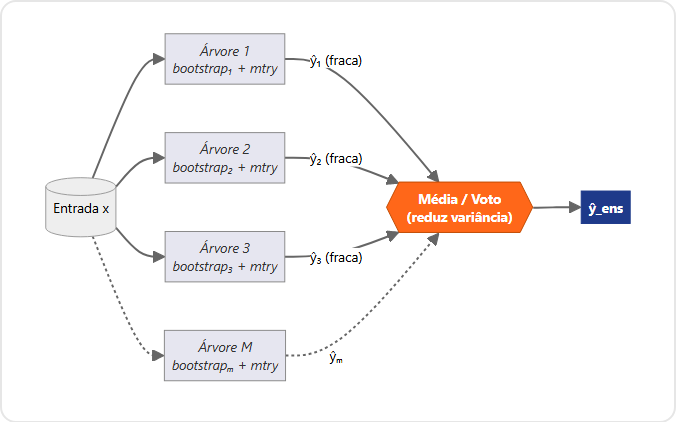
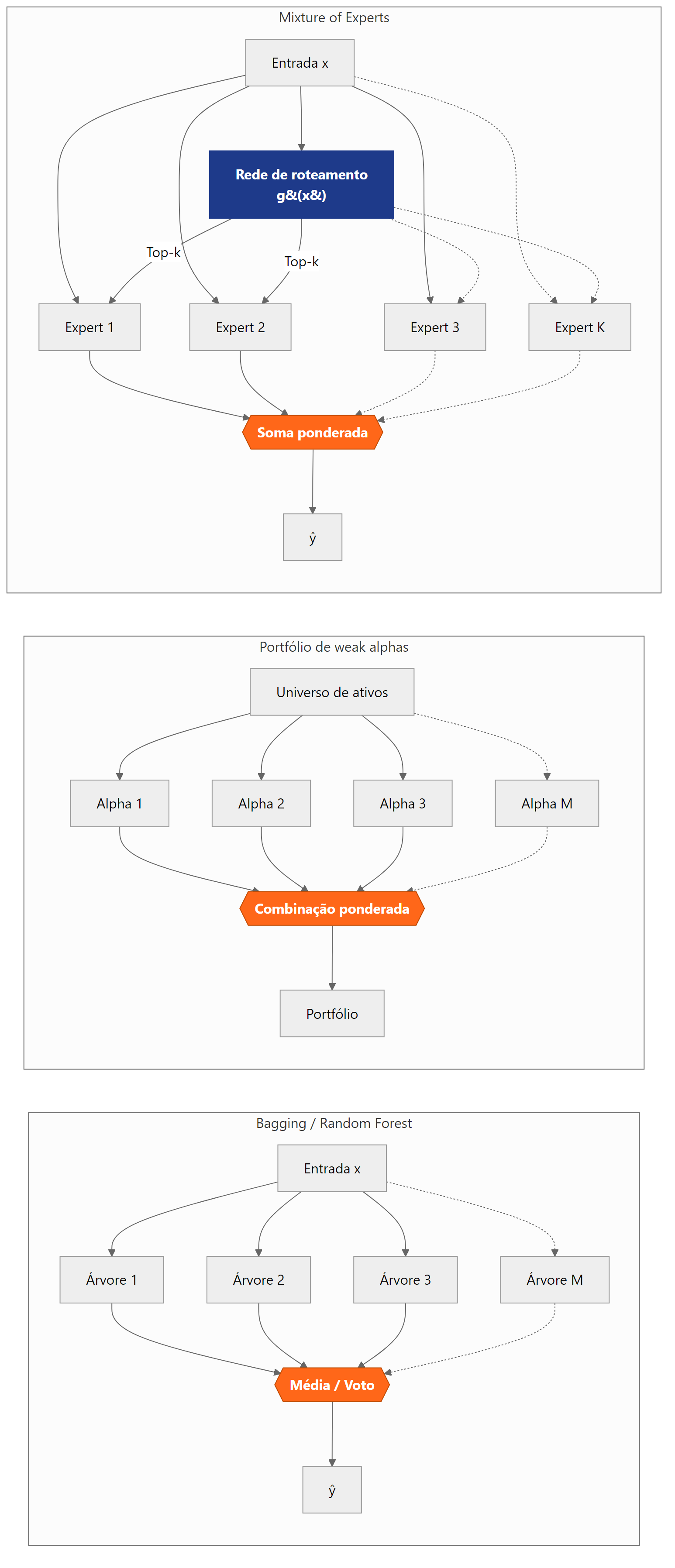
O leitor que conhece machine learning já viu para onde isso vai. Leo Breiman publicou em 2001 o artigo que batizou os Random Forests (BREIMAN, 2001), combinando duas ideias simples: o bagging de 1996 (que constrói cada árvore sobre uma réplica bootstrap do conjunto de treino) e a amostragem aleatória de atributos em cada split. Individualmente, cada árvore é um preditor fraco, tipicamente com viés baixo e variância alta. Coletivamente, agregadas por média (regressão) ou voto (classificação), tornam-se um dos benchmarks mais robustos da literatura empírica em aprendizado de máquina.
O bound de generalização que Breiman deriva captura o princípio de Page em forma operativa:
Onde s é a força média das árvores (margem esperada entre a classe correta e a mais próxima competidora) e ρ̄ é a correlação média entre as funções margem. Reduzir ρ̄, mesmo à custa de piorar marginalmente s, derruba o limite superior do erro. A amostragem aleatória de atributos (mtry) existe precisamente para forçar ρ̄ para baixo: sem ela, todas as árvores convergiriam à mesma estrutura greedy dominada pelos atributos mais fortes, e o ensemble não ganharia sobre uma árvore solitária.
Em finanças, podemos comentar algumas evidências. Gu, Kelly e Xiu (2020) conduziram o estudo mais completo de machine learning em asset pricing até então, com 60 anos de dados mensais (1957–2016), cerca de 30 mil ações e 94 características firm-wide expandidas em 920 covariáveis após interação com indicadores macroeconômicos. No painel completo, Random Forests entregaram R² fora-de-amostra mensal de 0,0033, contra −0,0346 do OLS sem regularização.
O sinal negativo do OLS não é erro de digitação. O R² fora-de-amostra mede o ganho do modelo sobre o benchmark trivial de prever zero retorno excedente em todos os meses, e cai abaixo de zero quando o modelo erra mais que essa previsão nula. O OLS, ajustando 920 coeficientes no treino, produz previsões enviesadas no teste, e seu R² mensal de −0,0346 indica que ele prevê pior que a constante zero. O Random Forest mal supera o benchmark com R² de 0,0033, mas é justamente essa fração minúscula que, espalhada por milhares de decisões cross-section, vira Sharpe institucionalmente competitivo pela lei de Grinold tratada na próxima seção.
Gradient Boosted Trees e redes neurais rasas foram marginalmente superiores às florestas, mas a distância grande do estudo está entre métodos de ensemble e métodos sem agregação, não entre variantes de ensemble. É o gado de Plymouth aparecendo onde menos se esperaria, em séries temporais de retornos ruidosas, não-lineares, com 60 anos de regimes diferentes empilhados. A mesma ordenação reaparece em credit scoring desbalanceado e em previsão de default, onde florestas e boosting superam consistentemente regressão logística e análise discriminante.
A demonstração em Julia usa um data generating process sintético com oito atributos, dos quais seis têm relação não-linear com a direção binária do retorno (sinais, interações, saturações) e dois são ruído puro. Amostra de 2.000 observações para treino e 1.000 para teste. O limite de Bayes, computado pelo conhecimento do processo gerador, é de 0,755.
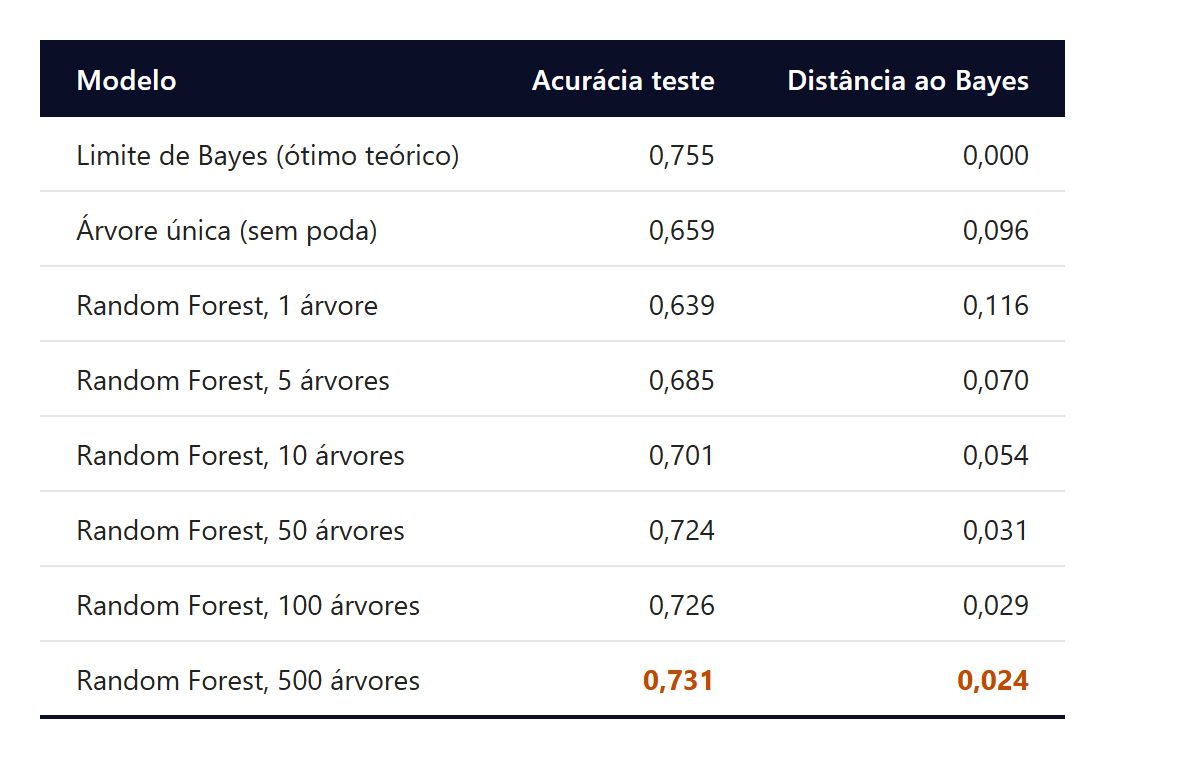
Uma árvore solitária sem poda, otimizando cada split em todas as features, atinge 0,659 no conjunto de teste, substancialmente pior que o limite de Bayes por overfitting. Quinhentas árvores com mtry=3 chegam a 0,731, fechando 75% da distância até o limite teórico.
O interessante não é a curva, é a anatomia do voto. Treinando 300 árvores em bootstraps disjuntos para medir as correlações, encontram-se os números abaixo.
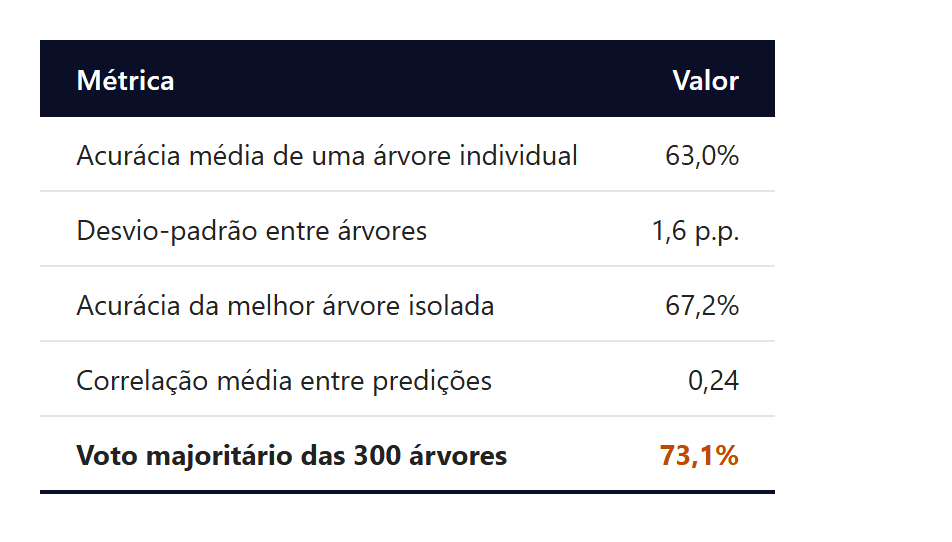
É literalmente o gado de Plymouth em forma algorítmica. Agregar muitos palpites ruins e fracamente correlacionados produz uma estimativa melhor que cada um dos palpites individuais, inclusive melhor que o melhor deles. A correlação média de 0,24 é fabricada pelo próprio algoritmo, via bootstrap + mtry, dois mecanismos artificiais que forçam diversidade onde a estrutura do problema, deixada em paz, não a teria.
O retrato acima exige disciplina metodológica em séries temporais financeiras, e o ponto crítico é o temporal leakage. Folds de validação cruzada iid violam a dependência temporal dos retornos, e amostragem bootstrap clássica embaralha passado e futuro, inflando o R² fora-de-amostra com vazamento que não corresponde a habilidade preditiva. O problema é solucionável no próprio pipeline, e López de Prado (2018) documentou as duas correções que se tornaram padrão. Substitui-se o k-fold iid por purged k-fold cross-validation com embargo entre treino e teste adjacentes, e a amostragem bootstrap clássica por block bootstrap, que preserva a dependência local dos retornos. Com essas adaptações, o efeito ensemble continua válido em séries financeiras. Sem elas, o R² OOS reportado superestima sistematicamente a habilidade real do modelo.
A lei fundamental de Grinold
Em mesa de fundo sistemático, a mesma identidade vem no idioma de Sharpe e é, na verdade, mais antiga que Breiman. Richard Grinold publicou em 1989 a Fundamental Law of Active Management (GRINOLD, 1989), reescrita por Grinold e Kahn em forma canônica:
Fundamental Law of Active Management (GRINOLD, 1989, paráfrase). O information ratio (IR, razão entre excesso de retorno e risco ativo anualizados) decompõe-se em dois fatores, o information coefficient (IC, correlação entre previsão e retorno realizado) e a breadth (BR, número de decisões ativas independentes por ano).
A fórmula é desconcertante na primeira leitura, porque afirma que habilidade modesta pode produzir IR alto se a largura for suficiente. Um analista com IC de 0,05 (correlação de 5% entre previsão e realização, valor modesto pelos padrões de equity research) e 1.000 decisões independentes por ano atinge IR teórico de 1,58, comparável a fundos macro top-decil.
A conexão com Galton é automática, pois cada decisão de compra ou venda é um palpite fraco sobre retornos futuros. A diversificação sobre muitas decisões independentes reduz a variância do retorno da carteira pela mesma álgebra de Breiman. Escrita em termos do Sharpe do ensemble de M sinais com Sharpe individual s e correlação média ρ:
Duas assíntotas governam esse ganho. Quando ρ → 0, o Sharpe cresce com √M sem limite. Quando M → ∞, o Sharpe satura em s/√ρ. Um quant que pretende construir carteira sobre 500 sinais com Sharpe individual de 0,30 e correlação média de 0,15 não está mirando Sharpe 6,7. Está mirando, no melhor cenário, 0,77. A correlação entre alphas é o teto estrutural do portfólio, e documentar que ρ permanece baixo sob stress é parte essencial do trabalho de construção de books quantitativos.
A tabela abaixo, produzida pela simulação Julia, é o retrato quantitativo dessa tensão entre M e ρ.
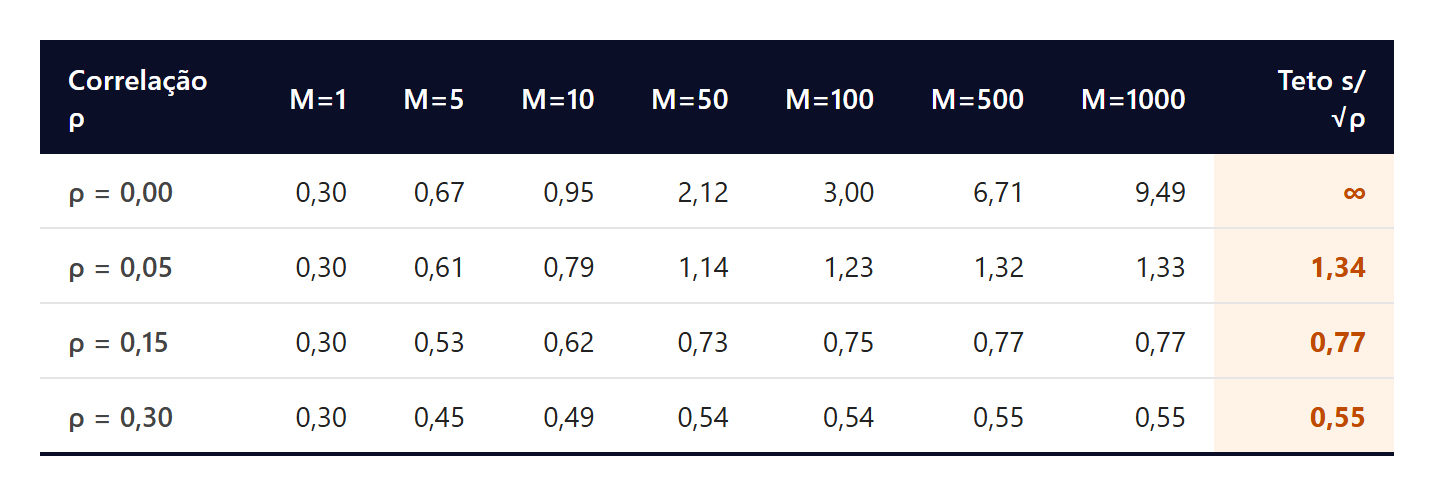
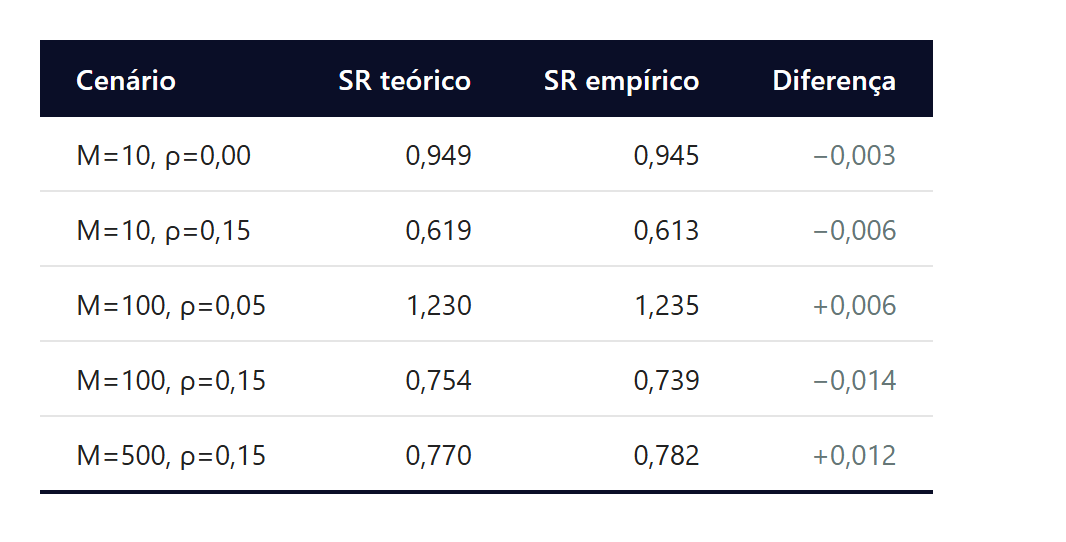
O Monte Carlo com 2.520 dias úteis e 400 caminhos confirma a fórmula analítica em terceira casa decimal, fechando a ligação entre teoria e simulação.
Kakushadze (2016) publicou um catálogo público de 101 alphas formulaicos derivados do sistema da WorldQuant, documentando correlação média par-a-par de 15,9% e holding periods de menos de uma semana. O ponto não é que cada fórmula seja genial, porque a maioria é combinação banal de retornos, volumes e volatilidades. O ponto é que o agregado dessas fórmulas, sob o teto s/√ρ, empurra o Sharpe do livro para faixas institucionalmente competitivas. A busca do “único sinal mágico” cede lugar, nesse regime, ao trabalho sistemático de gerar, testar e combinar centenas de sinais modestos e descorrelacionados.
Essa estratégia tem um predador natural, o overfitting. Harvey, Liu e Zhu (2016) examinaram 316 fatores publicados em revistas acadêmicas até 2014 e argumentaram que, dado o volume de testes múltiplos, o t-estatístico crítico para alegar descoberta genuína deve subir de 2,0 para ao menos 3,0 (ajustes Bonferroni, Holm, BHY). Sem essa correção, a diversidade aparente do livro de alphas é em parte ilusão de p-hacking, e o teto s/√ρ colapsa porque o s verdadeiro é zero para boa parte dos sinais catalogados.
Mixture of Experts
O passo seguinte requer um deslocamento menos confortável, para modelos de linguagem de grande porte aplicados a textos financeiros. A arquitetura Mixture of Experts (MoE), proposta originalmente por Jacobs, Jordan, Nowlan e Hinton (1991), substitui uma única rede neural densa por múltiplos subespecialistas coordenados por uma rede de roteamento (gating). Formalmente:
Onde eₖ são os E experts, g é a rede de roteamento e TopK zera todos os logits exceto os k maiores. Shazeer et al. (2017) mostraram que essa ativação esparsa permite escalar para milhares de experts sem explodir o custo computacional, e variantes posteriores (Switch Transformer, Mixtral) chegaram a modelos de centenas de bilhões a um trilhão de parâmetros com apenas uma fração sendo ativada em cada passo de inferência.
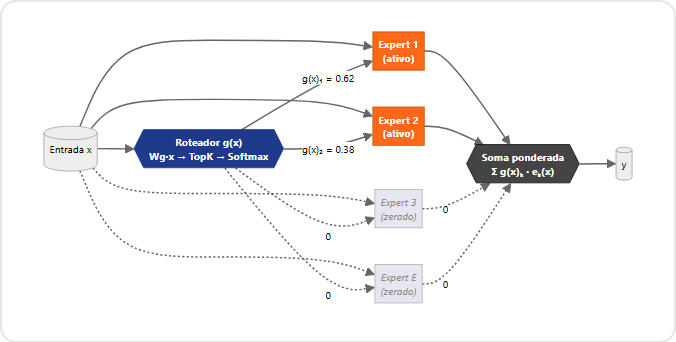
O leitor que chama isso de “apenas uma média ponderada com pesos esparsos” não está totalmente errado. À primeira vista, MoE parece uma generalização direta de ensembles. Em um Random Forest ou em uma carteira de weak alphas, todas as árvores ou todos os sinais contribuem para cada previsão, e a força vem do cancelamento de erros por média, na lógica de redundância independente. Em MoE, a rede de roteamento seleciona um subconjunto esparso de experts para cada entrada, e a força vem da especialização por subregião do espaço de features, na lógica de dividir e conquistar. São dois mecanismos diferentes apoiados no mesmo princípio mais geral, o de que combinar estimadores cujos erros são estruturalmente diferentes produz estimadores melhores que cada um.
O diagrama abaixo contrasta as três arquiteturas.
Em finanças, MoE ainda está em fase inicial, mas a pressão para usá-lo é crescente. BloombergGPT (WU et al., 2023), modelo de 50 bilhões de parâmetros treinado em 363 bilhões de tokens financeiros, é o exemplar canônico do modelo único denso especializado em um domínio inteiro. O passo natural da literatura é particionar esse domínio entre especialistas, um afinado em transcrições de teleconferências de resultados, outro em relatórios regulatórios, outro em notícias macroeconômicas, todos coordenados por uma rede de roteamento que decide qual consultar para cada texto de entrada. Ensembles adaptativos desse tipo são, conceitualmente, o princípio de Galton posto a operar dentro da arquitetura do modelo, e não apenas sobre as saídas de modelos independentes.
Quando a multidão erra
A mesma álgebra que explica por que a multidão de Plymouth acertou o peso do animal explica também por que as multidões financeiras erram, e erram de forma sistemática. A identidade de Page é uma igualdade, não uma garantia. O erro coletivo só é pequeno quando a diversidade preditiva é grande. Duas condições precisam valer simultaneamente para isso acontecer, e ambas podem falhar em mercados financeiros.
A primeira condição é a independência dos palpites. Lorenz, Rauhut, Schweitzer e Helbing (2011) conduziram experimento com 144 participantes estimando quantidades factuais (densidade populacional, comprimento da fronteira suíço-italiana) em seis rodadas sucessivas. Quando os participantes viam o palpite médio ou os palpites individuais dos outros entre rodadas, a diversidade desmoronava e a estimativa coletiva, embora mais confiante, convergia para valores enviesados. Em mercados financeiros, feeds de preços em tempo real, chats de Bloomberg, relatórios de sell-side e redes sociais financeiras (FinTwit, Reddit) funcionam exatamente como o feedback que colapsa a diversidade no experimento de Lorenz. O efeito Galton exige que os palpites sejam produzidos em isolamento informacional. O mercado moderno opera no regime oposto.
A segunda condição é que os erros individuais não tenham viés sistemático. Bikhchandani, Hirshleifer e Welch (1992) formalizaram cascatas informacionais. Quando agentes sequenciais observam a ação dos anteriores, mesmo um sinal privado forte pode ser racionalmente descartado em favor da inferência sobre o que os demais parecem saber. O resultado é herding racional, diversidade nula e erros coletivos gigantes, manifestos em bolhas, runs bancários e fire sales. A crise financeira de 2008 e o colapso do Silicon Valley Bank em 2023 ilustram o padrão: milhares de atores tomando decisões “informadas” que se referenciavam mutuamente, sem diversidade real de julgamento.
Para o quant que constrói modelos de ensemble, essas duas falhas têm contrapartes diretas. A correlação entre árvores de um Random Forest salta em períodos de stress, quando os atributos mais informativos passam a dominar todos os splits. A correlação entre weak alphas aumenta em crises, porque quase todos os sinais acabam reduzindo-se a variantes de beta, value ou momentum. Um portfólio otimizado em regime de ρ = 0,15 pode operar em ρ = 0,60 durante um flash crash, e o Sharpe ex-ante deixa de ser preditor útil do Sharpe realizado. López de Prado (2018) apelida esse fenômeno de structural break in correlations e argumenta que monitorar a estabilidade de ρ é parte do trabalho de risco, não só da construção.
Plymouth não é o mercado
Galton não elaborou a teoria da sabedoria das multidões. Coletou 787 bilhetes e relatou o que encontrou. A formalização veio em várias etapas: Condorcet no juízo binário, Page na identidade algébrica, Breiman no bagging, Grinold na versão financeira do Sharpe agregado, Jacobs e coautores no gating. O fio comum é que a qualidade de uma estimativa coletiva depende de palpites individualmente melhores que o aleatório (s > 0, IC > 0), baixa correlação entre eles (ρ̄ pequeno) e erros que não compartilham viés sistemático. Quando essas condições se mantêm, agregar centenas de modelos fracos ou de sinais modestos produz um preditor que bate o melhor especialista individual. Quando alguma falha (como em Lorenz ou em Bikhchandani), o ensemble pode ficar pior que um único preditor, porque a diversidade virou correlação e o viés virou consenso.
O concurso de Plymouth foi um laboratório ideal, com bilhetes escritos em isolamento, 787 palpites independentes e público heterogêneo. Mercados financeiros operam em condições opostas, com feeds em tempo real, chats, relatórios sell-side e FinTwit que colapsam diversidade em horas. Construir um Random Forest, um livro de alphas ou um sistema MoE sobre relatórios corporativos é, no fundo, tentar recriar artificialmente as condições de Plymouth: bootstrap e mtry no lugar do isolamento entre palpiteiros, ortogonalização explícita no lugar de heterogeneidade espontânea, monitoramento ativo de ρ no lugar da independência presumida.
Plymouth foi um único concurso, num único dia, com um único animal, e Galton publicou a contragosto sem nunca mais voltar ao tema. O que sobrou foi a planilha, e ela continua dizendo, 119 anos depois, o que dizia em 1907. A multidão acerta quando ninguém combina antes, e toda a engenharia de ensembles construída desde então foi uma sequência de tentativas, em domínios cada vez mais hostis, de fingir que ninguém combinou.
Referências
BIKHCHANDANI, Sushil; HIRSHLEIFER, David; WELCH, Ivo. A theory of fads, fashion, custom, and cultural change in informational cascades. Journal of Political Economy, v. 100, n. 5, p. 992-1026, 1992.
BREIMAN, Leo. Bagging predictors. Machine Learning, v. 24, n. 2, p. 123-140, 1996.
BREIMAN, Leo. Random forests. Machine Learning, v. 45, n. 1, p. 5-32, 2001.
GALTON, Francis. Vox populi. Nature, v. 75, n. 1949, p. 450-451, 1907.
GRINOLD, Richard C. The fundamental law of active management. The Journal of Portfolio Management, v. 15, n. 3, p. 30-37, 1989.
GU, Shihao; KELLY, Bryan; XIU, Dacheng. Empirical asset pricing via machine learning. The Review of Financial Studies, v. 33, n. 5, p. 2223-2273, 2020.
HARVEY, Campbell R.; LIU, Yan; ZHU, Heqing. … and the cross-section of expected returns. The Review of Financial Studies, v. 29, n. 1, p. 5-68, 2016.
JACOBS, Robert A.; JORDAN, Michael I.; NOWLAN, Steven J.; HINTON, Geoffrey E. Adaptive mixtures of local experts. Neural Computation, v. 3, n. 1, p. 79-87, 1991.
KAKUSHADZE, Zura. 101 formulaic alphas. Wilmott, n. 84, p. 72-81, 2016.
LORENZ, Jan; RAUHUT, Heiko; SCHWEITZER, Frank; HELBING, Dirk. How social influence can undermine the wisdom of crowd effect. Proceedings of the National Academy of Sciences, v. 108, n. 22, p. 9020-9025, 2011.
LÓPEZ DE PRADO, Marcos. Advances in financial machine learning. Hoboken: Wiley, 2018.
PAGE, Scott E. The difference: how the power of diversity creates better groups, firms, schools, and societies. Princeton: Princeton University Press, 2007.
SHAZEER, Noam et al. Outrageously large neural networks: the sparsely-gated mixture-of-experts layer. In: International Conference on Learning Representations (ICLR), 2017.
WALLIS, Kenneth F. Revisiting Francis Galton’s forecasting competition. Statistical Science, v. 29, n. 3, p. 420-424, 2014.
WU, Shijie et al. BloombergGPT: a large language model for finance. arXiv preprint, arXiv:2303.17564, 2023.