
Predição conformal para quants: cobertura garantida sem premissas distribucionais
Como transformar qualquer modelo de aprendizado de máquina em previsor com garantia frequentista de cobertura, sob uma única premissa estatística de intercambialidade.

Um modelo de risco estima que a perda diária de uma carteira não deve ultrapassar -2,3% com 99% de confiança. O número parece objetivo, mas a decisão depende menos do ponto reportado do que da qualidade do intervalo que o sustenta. Mesmo quando se abandona a normalidade e se usa simulação histórica, bootstrap ou regressão quantílica, a pergunta continua a mesma: com que frequência o intervalo prometido cobre o resultado realizado? Métodos não paramétricos reduzem a dependência de uma forma distribucional específica, mas em geral não entregam garantia frequentista de cobertura em amostra finita. A inferência bayesiana entrega um intervalo de credibilidade com interpretação posterior, condicionado a um prior que nem sempre é defensável em problemas de risco.
A predição conformal (conformal prediction) é um arcabouço alternativo que parte de um ponto distinto. Em vez de fazer suposições sobre a forma da distribuição, parte da única premissa de intercambialidade (exchangeability) das observações, e a partir dela deriva uma garantia formal. A probabilidade de o valor verdadeiro Yn+1 cair dentro do conjunto de previsão C(Xn+1) é maior ou igual a 1 − α, sem qualquer suposição adicional sobre a distribuição dos dados.
O ponto que torna a predição conformal especialmente interessante para o quant é que ela é agnóstica ao modelo subjacente. Pode-se acoplá-la a uma regressão linear, a um random forest, a uma rede neural profunda ou a um gradient boosting sem alterar a garantia de cobertura. O modelo continua sendo um estimador de ponto, e a predição conformal o converte em previsor com cobertura garantida em amostra finita, sob a condição de intercambialidade.
Este artigo abre uma série dedicada a aplicações de predição conformal em finanças quantitativas. A questão central é distinguir o que a garantia conformal realmente promete do que ela não promete. Para o quant, isso significa olhar separadamente para cobertura marginal, eficiência do intervalo, diagnóstico condicional e quebra de intercambialidade em séries financeiras. A predição conformal não elimina risco de modelo, mas transforma parte da incerteza preditiva em uma afirmação testável de cobertura, com premissas explícitas e custo computacional controlado.
Origens na escola russa
A escola de pensamento que produziu a predição conformal tem raízes mais antigas, na tradição russa de Andrei Kolmogorov sobre complexidade algorítmica e aleatoriedade. Desde os anos 1960, essa linhagem priorizou garantias finitas e independentes da forma da distribuição, em contraste com o foco assintótico-paramétrico que dominou a estatística ocidental. Per Martin-Löf, aluno sueco de Kolmogorov, formalizou aleatoriedade via testes algorítmicos, e essa noção de “teste de tipicidade” é o ancestral direto do p-valor conformal. Vladimir Vapnik, da mesma escola, cunhou a teoria de Vapnik-Chervonenkis (VC) e o pensamento distribution-free em aprendizado. Sua migração para a Bell Labs nos anos 1990 levou a teoria VC para o Ocidente, mas o conformal não foi junto. Vovk e Gammerman emigraram para Royal Holloway, em Londres, e ali, com Shafer (Rutgers), formularam a predição conformal a partir do final dos anos 1990, em relativo isolamento do mainstream estatístico. O programa avançou em paralelo ao projeto Shafer-Vovk de probabilidade game-theoretic, que dá ao conformal um fundamento alternativo via teoria de jogos e apostas, e foi consolidado no livro Algorithmic Learning in a Random World (VOVK et al., 2022, com primeira edição em 2005).
Por mais de uma década o método circulou em comunidades restritas, sobretudo em diagnóstico médico, enquanto a estatística e o aprendizado de máquina ocidentais estavam ocupados com teoremas assintóticos, o boom bayesiano via Markov Chain Monte Carlo (MCMC) nos anos 1990, bootstrap à la Efron e, mais tarde, deep learning sem incerteza calibrada. A virada veio em 2018, com o trabalho de Lei, Wasserman e Tibshirani na Carnegie Mellon traduzindo o conformal para a linguagem da estatística aplicada de regressão (LEI et al., 2018), e na sequência com a popularização via tutoriais modernos (ANGELOPOULOS; BATES, 2023). O encontro com problemas de incerteza em modelos black-box tornou o conformal a peça que faltava no arsenal ocidental.
Intercambialidade como única premissa
A predição conformal só impõe uma premissa sobre os dados, e essa premissa é mais fraca que a tradicional hipótese de observações independentes e identicamente distribuídas. Uma sequência (Z1, Z2, ..., Zn+1) é dita intercambiável quando sua distribuição conjunta é invariante sob qualquer permutação dos índices. Toda sequência i.i.d. é intercambiável, mas a recíproca não vale.
Intercambialidade (paráfrase de Vovk et al., 2022).
Uma sequência (Z1, ..., Zn+1) é intercambiável se e somente se P(Zπ(1), ..., Zπ(n+1)) = P(Z1, ..., Zn+1) para toda permutação π dos índices {1, ..., n+1}. Independência implica intercambialidade, mas a recíproca não vale.
O exemplo canônico de sequência intercambiável e não i.i.d. é a amostragem sem reposição de uma urna finita. Considere uma urna com 2 bolas vermelhas e 2 azuis, da qual se retiram 2 bolas sem reposição. Na primeira extração, P(vermelha) = 1/2. Se a primeira bola foi vermelha, a probabilidade de vermelha na segunda cai para 1/3. Se a primeira foi azul, sobe para 2/3. As extrações, portanto, não são independentes. Ainda assim, a sequência é intercambiável, porque observar (vermelha, azul) tem a mesma probabilidade que observar (azul, vermelha): em ambos os casos, 1/3. A ordem carrega dependência, mas a distribuição conjunta não favorece uma posição específica. É essa distinção que permite usar predição conformal em alguns problemas não independentes, mas não em qualquer série financeira sem adaptação.
Retornos diários de um ativo não são i.i.d., porque a distribuição muda com o regime de volatilidade, liquidez e condições macrofinanceiras. Em vários cenários de risco de crédito, contudo, em que cada cliente é uma observação cross-section, intercambialidade é uma premissa razoável dentro de um grupo homogêneo. A mesma observação vale para classificação de imagens com dados independentes de um banco de fotos, ou para amostras de pesquisas de campo coletadas em uma janela temporal estreita.
Em séries temporais financeiras, intercambialidade falha sistematicamente, e parte da literatura recente em predição conformal trata de como recuperar garantias mesmo nesse cenário. Há propostas para redes neurais recorrentes sob intercambialidade mínima entre trajetórias independentes (STANKEVIČIŪTĖ et al., 2021), cobertura sob não intercambialidade com termo de erro proporcional à variação total entre distribuições de treino e teste (BARBER et al., 2023), e reponderação por razão de verossimilhanças em covariate shift (TIBSHIRANI et al., 2019). Esses resultados não são objeto deste artigo introdutório, mas delimitam a fronteira estatística que precisa ser respeitada em aplicações financeiras.
Para o caso intercambiável, a garantia é exata em amostra finita (finite-sample). Isso significa que ela vale para o tamanho de amostra observado, sem depender de aproximações assintóticas quando n tende ao infinito. Não se invocam grandes números, não se invocam teoremas centrais do limite, não se invocam expansões assintóticas.
Função de não conformidade e p-valor conformal
A construção de um previsor conformal começa pela definição de uma função de não conformidade (nonconformity score). É uma função simétrica A que recebe um conjunto de observações de calibração {z1, ..., zn} e um candidato zn+1, e retorna um valor αn+1 ∈ ℝ que mede o quão estranho o candidato parece em relação ao conjunto. Quanto maior αn+1, menos conforme.
O escore canônico em regressão é o resíduo absoluto. Dado um estimador f̂ ajustado em dados de treino, define-se
Em classificação, o escore canônico é um menos a probabilidade prevista para a classe verdadeira:
Outras funções são possíveis, e a escolha tem consequências sobre a eficiência do previsor (largura do intervalo), embora não sobre sua validade (cobertura). A partir dos escores de calibração α1, ..., αn e do escore hipotético αn+1 que o candidato teria se incluído no conjunto, define-se o p-valor conformal:
Se zn+1 vem da mesma distribuição do conjunto de calibração, sob intercambialidade o rank de αn+1 entre os demais escores é uniformemente distribuído em {1, 2, ..., n+1}. Daí pn+1 distribui-se de forma super-uniforme em {1/(n+1), ..., (n+1)/(n+1)}, atuando como p-valor genuíno para a hipótese de que o candidato pertence à mesma distribuição que os dados de calibração (SHAFER; VOVK, 2008; VOVK et al., 2022).
O conjunto de previsão conformal de nível 1 − α é definido como o conjunto de candidatos cujo p-valor excede α:
O p-valor conformal pode ser lido como uma regra de ranking. Primeiro se escolhe uma medida de não conformidade, como erro absoluto em regressão ou 1 menos a probabilidade atribuída à classe verdadeira em classificação. Depois se fixa α e se testa uma sequência de candidatos y. Cada candidato entra no conjunto se seu p-valor conformal for maior que α. O conjunto final é apenas a coleção dos candidatos aceitos.
Considere um exemplo unidimensional com previsão pontual igual a zero, escore s(y) = |y − 0|, α = 0,10 e nove escores de calibração: 0,02, 0,03, 0,04, 0,05, 0,06, 0,07, 0,08, 0,09 e 0,10. O candidato y = 0,10 tem escore 0,10. Dois dos dez escores no conjunto aumentado são pelo menos tão extremos quanto ele, o próprio candidato e o ponto de calibração 0,10, então p(y) = 2/10 = 0,20 e o candidato entra. Já y = 0,125 tem escore 0,125. Só o próprio candidato é tão extremo quanto ele, então p(y) = 1/10 = 0,10. Como a regra usa p(y) > α, esse candidato fica fora. Repetindo essa comparação para uma grade de valores, forma-se o conjunto conformal.
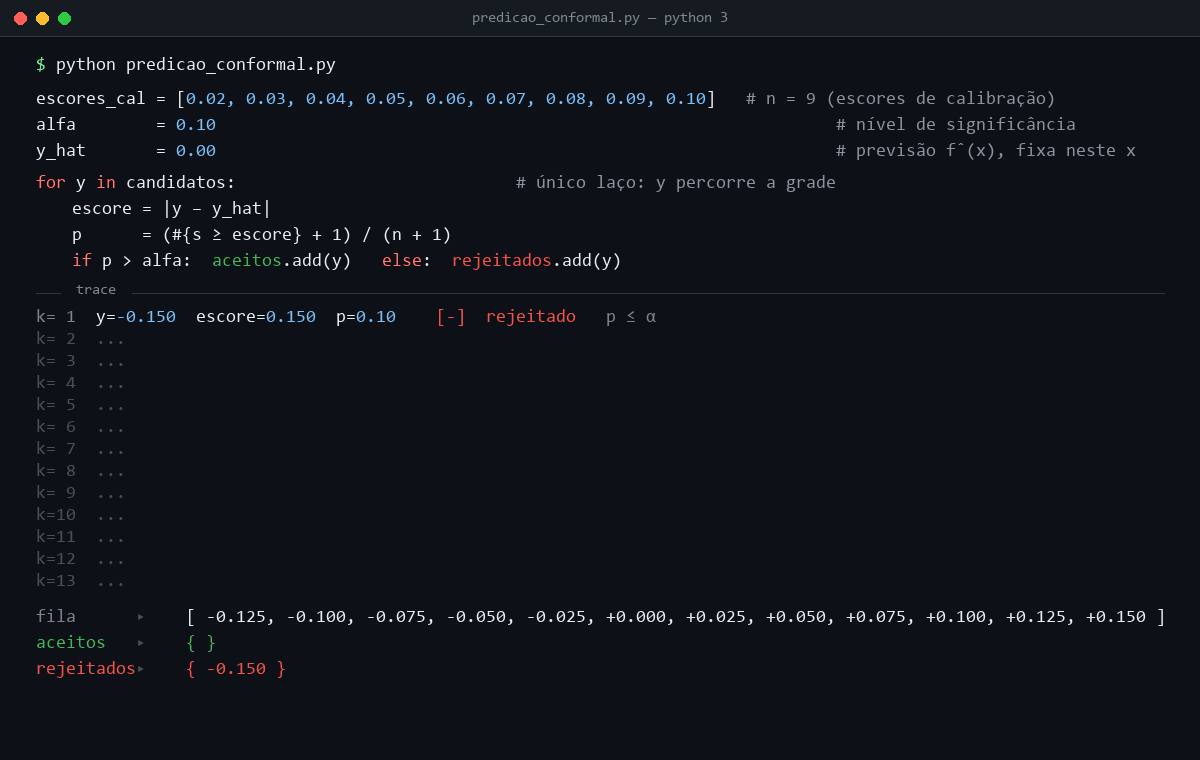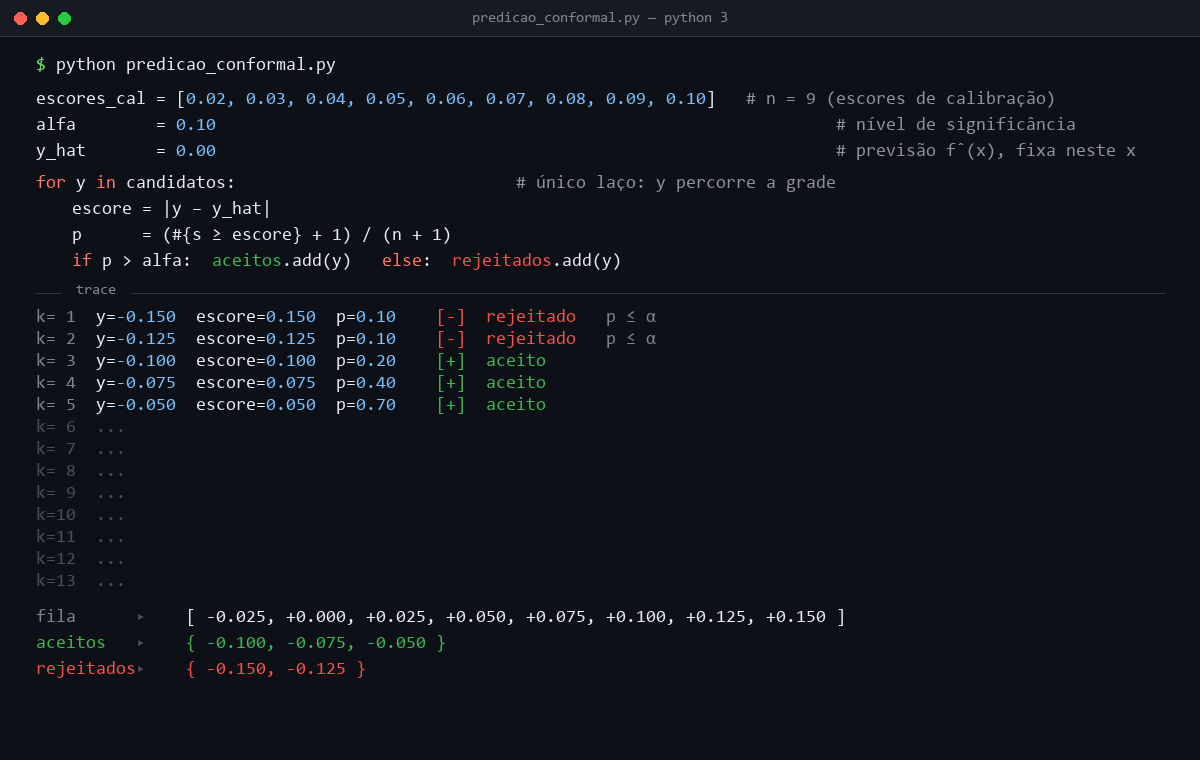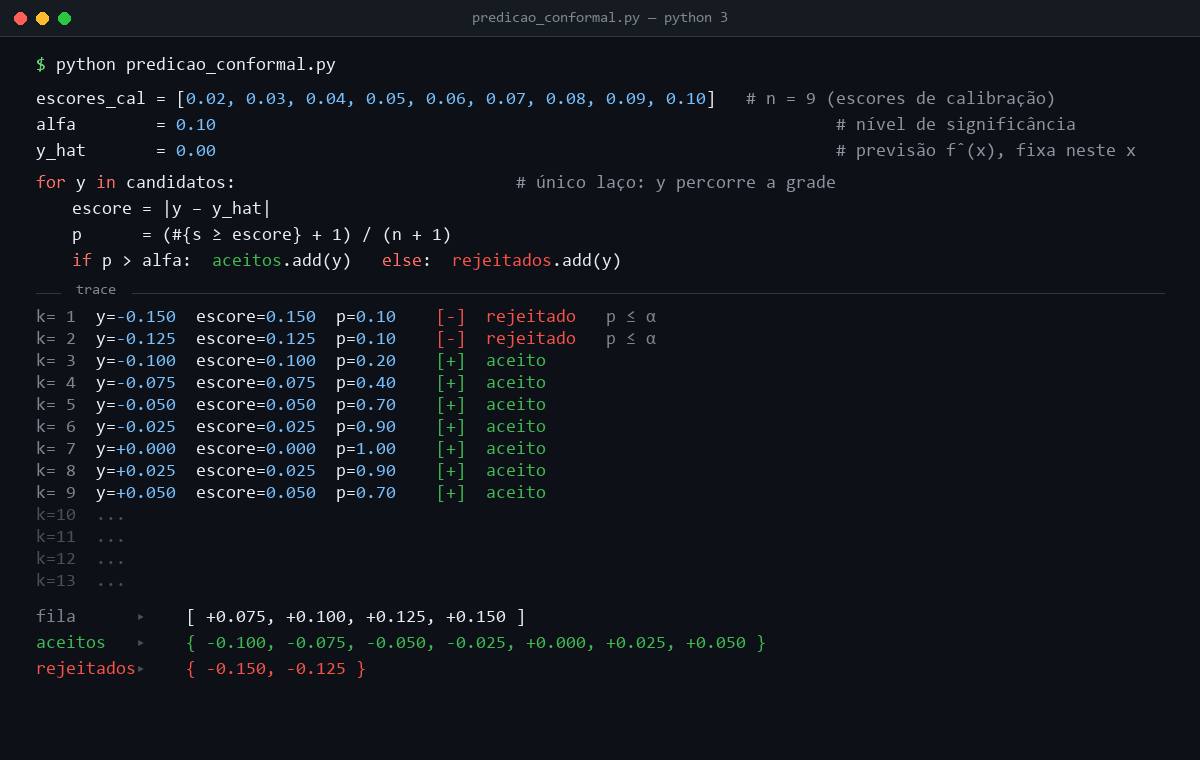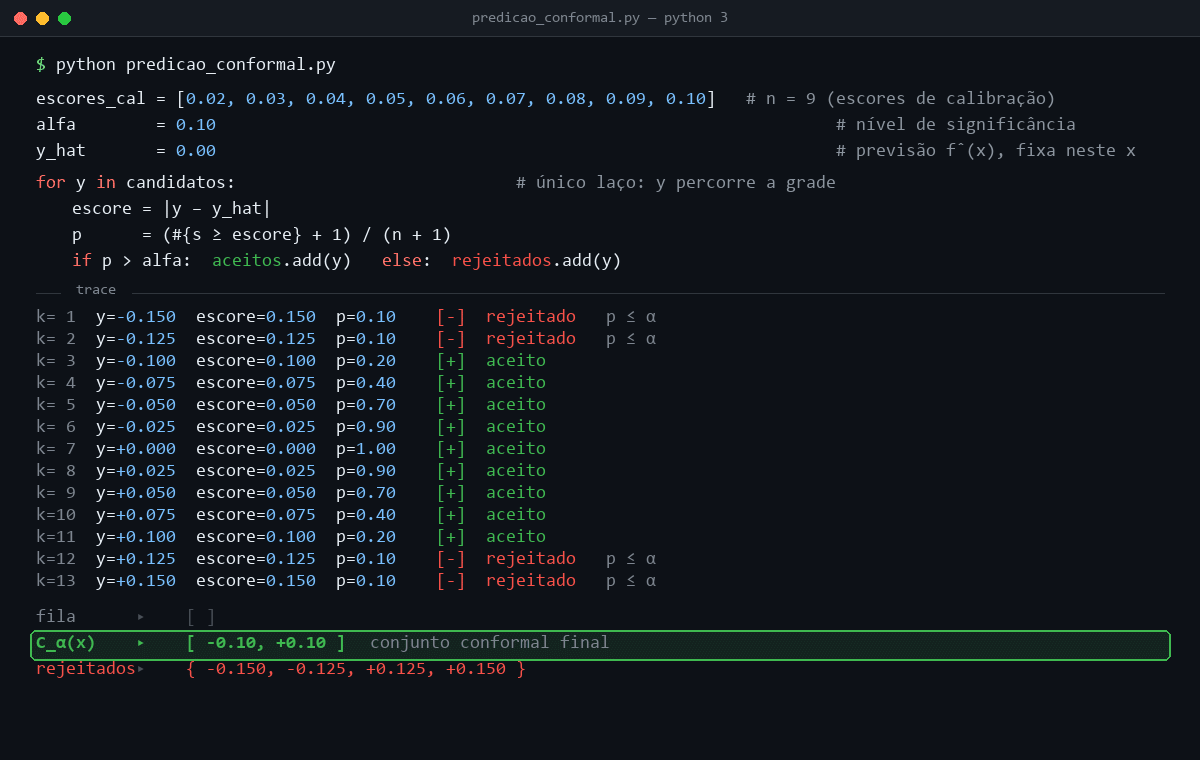
Ao longo do laço, apenas o candidato y varia. A previsão pontual ŷ = f̂(x), o nível α e os escores de calibração permanecem fixos durante toda a construção do conjunto. Como o escore s(y) = |y − ŷ| cresce monotonicamente com a distância de y a ŷ, p(y) decresce no mesmo movimento. Atinge o máximo p(ŷ) = 1,00 no ponto em que todos os escores de calibração são pelo menos tão extremos quanto o do candidato, e cai ao piso 1/(n + 1) = 0,10 quando o escore do candidato excede o maior escore de calibração. A regra p(y) > α corta o conjunto exatamente nesse limiar. Entram os candidatos com escore menor ou igual ao maior escore de calibração, e os demais ficam fora.
O intervalo [-0,10, 0,10] formado pelos candidatos aceitos é o conjunto conformal Cα(x) deste exemplo. Reúne todos os valores de y compatíveis com os escores de calibração ao nível α = 0,10, e é a saída efetiva do procedimento para o ponto de teste x. A garantia de cobertura formaliza essa intuição.
A garantia de cobertura segue diretamente:
Por intercambialidade, o rank de αn+1 entre α1, ..., αn+1 é uniforme em {1, ..., n+1}, então a probabilidade de αn+1 exceder o quantil 1 − α dos demais é no máximo α (ANGELOPOULOS; BATES, 2023). Com escores quase certamente distintos, a cobertura também tem cota superior P(·) ≤ 1 − α + 1/(n+1), de modo que a garantia é apertada.
O α conformal e o α de teste de hipótese são notações idênticas com objetos diferentes. Na inferência clássica, α é a probabilidade de cometer erro tipo I, ou seja, rejeitar uma hipótese nula quando ela é verdadeira. Na predição conformal, α é a taxa de erro preditivo marginal, ou seja, a restrição de que a probabilidade de o conjunto Cα(x) não conter a verdadeira resposta Yn+1 fique limitada a α. A garantia P(Yn+1 ∈ Cα(Xn+1)) ≥ 1 − α é, portanto, uma cota sobre a frequência com que o conjunto preditivo erra, não sobre a frequência com que rejeitamos uma hipótese verdadeira sobre um parâmetro.
O mesmo descompasso aparece no p-valor. Em testes clássicos, ele mede evidência contra uma afirmação sobre um parâmetro populacional fixo, sob amostragem repetida da distribuição que se hipotetiza. O p-valor conformal testa hipótese diferente, a de que o par candidato (Xn+1, y) é intercambiável com as observações do conjunto de calibração. A estatística de teste é o ranqueamento da estranheza do candidato, medida por um escore de não-conformidade, em relação aos demais (SHAFER; VOVK, 2008). Sob intercambialidade e quando o candidato vem da mesma distribuição que os dados, esse p-valor é super-uniforme em [0, 1] e, portanto, válido em sentido frequentista. Um p-valor clássico pequeno empurra para rejeitar uma teoria sobre o mundo, enquanto um p-valor conformal pequeno empurra para excluir um valor candidato do conjunto de previsão.
A confusão de maior consequência, contudo, é entre o conjunto Cα(x) e os intervalos clássicos de inferência. Intervalos de confiança (frequentistas) e intervalos de credibilidade (bayesianos) quantificam incerteza sobre estimativas de parâmetros inobserváveis de uma distribuição, como a média μ, os coeficientes β de uma regressão ou a volatilidade σ de um modelo. O IC tem interpretação no procedimento, que cobre o parâmetro desconhecido com frequência ≥ 1 − α em amostragem repetida. O intervalo de credibilidade tem interpretação direta como probabilidade posterior sobre o parâmetro, dado o que foi observado. O conjunto conformal Cα(x) é objeto de natureza diferente, um conjunto de predição, com garantia de cobertura sobre uma variável aleatória observável futura Yn+1. IC e credibilidade falam sobre quantidades inerentes à distribuição, que não serão observadas diretamente e apenas inferidas, enquanto Cα(x) fala sobre uma realização futura da própria variável aleatória, que se materializa amanhã. Confundir os três é o erro mais comum de primeira leitura. Relatar um intervalo de credibilidade no lugar de um conjunto de previsão muda a tese sobre a qual o número se sustenta.
Predição transdutiva e indutiva
A formulação acima descreve o que se chama predição conformal transdutiva (Transductive Conformal Prediction, TCP), também conhecida como full conformal prediction. Para cada candidato y a ser testado, é necessário recalcular os escores de todo o conjunto incluindo (xn+1, y), o que em muitos casos exige reajustar o modelo. Em regressão com candidatos contínuos, a inclusão é tipicamente conduzida sobre uma grade de valores, e o custo escala como O(n × |grade|) ajustes do modelo subjacente. Para gradient boosting ou redes neurais profundas, o custo torna-se proibitivo.
A solução padrão é a predição conformal indutiva (Inductive Conformal Prediction, ICP), também chamada split conformal prediction. Os dados são particionados em três conjuntos disjuntos, em que Dtrain é usado para ajustar f̂ uma única vez, Dcal para calcular os escores de calibração αi = s(xi, yi, f̂), e Dtest fica reservado para avaliação. O quantil empírico
é então usado para construir o conjunto de previsão para qualquer ponto de teste:
A garantia P(Yn+1 ∈ Cα(Xn+1)) ≥ 1 − α permanece válida pelo mesmo argumento de intercambialidade do regime transdutivo, agora condicionado a f̂: como o modelo é estimado apenas em Dtrain, os escores em Dcal ∪ {teste} permanecem intercambiáveis condicionalmente a f̂, e o rank de αn+1 é uniforme em {1, ..., ncal + 1}. A formulação original do método indutivo está em PAPADOPOULOS et al. (2002), com extensão para regressão e prova explícita em LEI et al. (2018), e exposição didática em ANGELOPOULOS; BATES (2023). A inferência custa apenas um forward pass do modelo por ponto de teste. Em conjuntos de dados grandes, a perda de eficiência face ao TCP é desprezível, e em troca obtém-se um custo computacional que não escala com o tamanho do conjunto de treino. O regime ICP é o que se usa em praticamente toda a literatura aplicada de predição conformal pós-2018, incluindo regressão quantílica conformalizada (Conformalized Quantile Regression, CQR), intervalos conformais por ensemble (Ensemble Batch Prediction Intervals, EnbPI), inferência conformal adaptativa (Adaptive Conformal Inference, ACI), conjuntos preditivos adaptativos (Adaptive Prediction Sets, APS) e conjuntos preditivos adaptativos regularizados (Regularized Adaptive Prediction Sets, RAPS).

Validade marginal e validade condicional
A garantia conformal é forte porque independe da forma da distribuição, mas é mais estreita do que parece à primeira leitura. Ela controla cobertura média, não cobertura ponto a ponto nem estabilidade temporal. A garantia P(Y ∈ Cα(X)) ≥ 1 − α é uma afirmação sobre a média da cobertura ao longo da distribuição conjunta de (X, Y). É chamada cobertura marginal, e não é equivalente a cobertura condicional, que exigiria P(Y ∈ Cα(X) | X = x) ≥ 1 − α para todo x no suporte. Um previsor com cobertura marginal de 90% pode subcobrir gravemente em subgrupos minoritários e supercobrir em grupos abundantes, mantendo a média correta.
Em risco de crédito, um modelo de probabilidade de default (PD) calibrado conformalmente pode ter cobertura marginal correta, e ainda assim subcobrir clientes de uma faixa específica de escore ou de uma região geográfica subrepresentada. Em gestão de risco regulatório, em que a tese é justamente a confiabilidade da incerteza, isso não é detalhe. A pergunta natural é se há um caminho construtivo para cobertura condicional exata sem premissas adicionais, e a resposta é negativa.
Impossibilidade de cobertura condicional exata sem premissas distribucionais (paráfrase de Barber et al., 2021, generalizando Lei e Wasserman, 2014).
Qualquer método que entregue cobertura condicional P(Y ∈ C(x) | X = x) ≥ 1 − α uniforme sobre toda distribuição P contínua produz intervalos de comprimento esperado infinito em pontos não atômicos do suporte. Em ambiente sem premissas distribucionais (distribution-free), cobertura condicional exata e largura finita são incompatíveis.
A saída pragmática é abandonar a exigência uniforme e impor cobertura condicional apenas em uma partição predefinida do espaço de atributos. Essa é a ideia do Mondrian conformal predictor, proposta por Vovk no início dos anos 2000 e tratada em detalhe no livro de 2022. Em vez de calibrar com um único quantil sobre Dcal, calibram-se quantis separados para cada bloco da taxonomia, de modo que se obtém cobertura ≥ 1 − α por bloco, à custa de exigir calibração suficiente dentro de cada um. Em risco de crédito, a partição natural é por faixa de rating, ao passo que em séries temporais ela pode ser por regime de volatilidade e em classificação por classe.
A literatura recente vem refinando o equilíbrio entre cobertura marginal e cobertura condicional. Romano, Barber, Sabatti e Candès (2020) propõem equalized coverage como extensão do Mondrian sob restrições de imparcialidade algorítmica. O ponto que importa para o quant é menos a sofisticação do método e mais o reconhecimento de que reportar apenas a cobertura marginal não basta. É necessário diagnosticar a cobertura empírica em subgrupos críticos antes de declarar o modelo apto para decisão.
Eficiência e a escolha do escore
A garantia de cobertura é robusta no sentido de valer para qualquer função de escore válida. Mas isso não significa que toda escolha produza intervalos úteis. A largura média do intervalo, a chamada eficiência, depende fortemente da função adotada.
Considere o caso de regressão com resíduo absoluto αi = |yi − f̂(xi)|. Se a variância condicional Var(Y | X = x) é aproximadamente constante, esse escore funciona bem. Em finanças, contudo, a heterocedasticidade é regra. A volatilidade depende do nível de mercado, do regime e da liquidez. Um escore baseado em resíduo absoluto produz intervalos de largura constante, que serão excessivamente largos em períodos calmos e estreitos demais em períodos turbulentos. A cobertura marginal de 1 − α é mantida por construção, mas a cobertura condicional varia com o regime.
A solução proposta por Romano, Patterson e Candès é a CQR. Em vez de usar resíduo absoluto, a função de escore é construída a partir de quantis condicionais q̂α/2(x) e q̂1−α/2(x) estimados por regressão quantílica (ROMANO et al., 2019):
A construção mantém a validade marginal, porque o escore é simétrico nos dados de calibração, e adapta a largura do intervalo localmente. Empiricamente, em benchmarks de Romano, Patterson e Candès, a largura média cai cerca de 30 a 40% em problemas heterocedásticos sem perda de cobertura (ROMANO et al., 2019). Essa família de métodos é uma das extensões naturais quando a aplicação exige intervalos menos rígidos que os produzidos por resíduos absolutos.
A validade vem da intercambialidade, mas a eficiência exige cuidado na escolha do escore. Um previsor conformal mal especificado entrega cobertura correta com intervalos largos demais para serem informativos. Em finanças quantitativas, em que decisões de risco se traduzem em alocação de capital regulatório e em precificação, a largura do intervalo importa tanto quanto a cobertura.
Onde a predição conformal encaixa no arsenal do quant
A predição conformal não substitui modelos paramétricos, bootstrap, regressão quantílica ou inferência bayesiana. Ocupa um espaço distinto no arcabouço estatístico do quant. A tabela abaixo sumariza as quatro alternativas dominantes para construção de intervalos de previsão e suas propriedades teóricas.
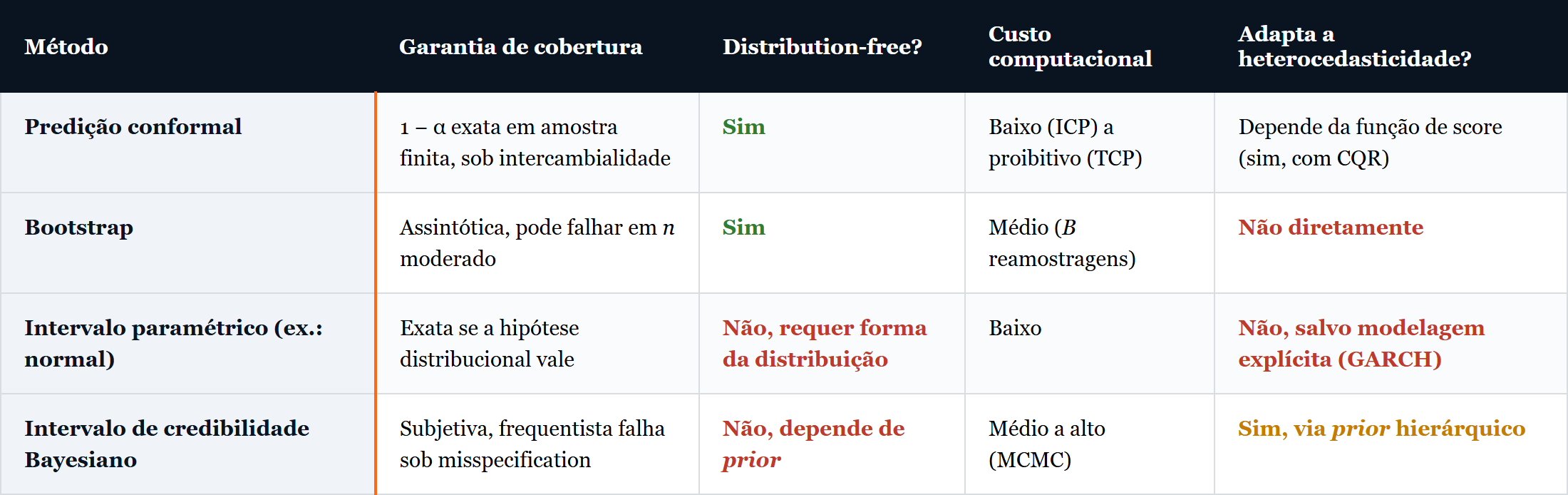
A complementaridade entre predição conformal e inferência bayesiana é particularmente interessante. Trabalhos recentes usam o arcabouço conformal para calibrar conjuntos de credibilidade bayesianos ex post, recuperando validade frequentista quando o modelo está mal especificado. Predição conformal funciona como diagnóstico e como correção, e não como concorrente direto da abordagem bayesiana.
Em aplicações em finanças quantitativas, alguns pontos de apoio na literatura merecem registro. Em risco de crédito, a linha de Venn-ABERS predictors estabelece base metodológica para calibração probabilística de PD com garantia de validade. Em séries temporais financeiras, ACI foi aplicado à volatilidade do mercado de ações com robustez à crise de 2008 (GIBBS; CANDÈS, 2021). EnbPI combina ensemble bootstrap conformal sem partição dos dados para previsão de séries dinâmicas (XU; XIE, 2021). Em mercados de energia, intervalos conformais foram aplicados a preços de eletricidade no mercado day-ahead, em comparação com Quantile Regression Averaging tradicional (KATH; ZIEL, 2021).
A aplicação de predição conformal em risco regulatório, sobretudo no contexto de IFRS 9 (PD prospectiva para expected credit loss), Basileia III/IV (validação de modelos) e stress tests, ainda parece menos consolidada que os usos em regressão, classificação e séries temporais. O melhor enquadramento, nesse estágio, é tratar CP como ferramenta de validação, diagnóstico e construção de intervalos, não como padrão regulatório estabelecido.
Conclusão
A predição conformal entrega uma proposição peculiar dentro do arsenal estatístico do quant. Cobertura 1 − α exata em amostra finita, sem assumir nada sobre a distribuição dos dados além de intercambialidade. A garantia é robusta no sentido matemático estrito, e o método é indiferente ao modelo subjacente. Random forest, gradient boosting, rede neural profunda, regressão linear ou regressão quantílica recebem todos o mesmo tratamento. O custo computacional, no regime ICP que dominou a literatura aplicada pós-2018, é equivalente a um forward pass adicional por ponto de teste.
A premissa de intercambialidade é mais fraca que i.i.d., mas continua sendo uma hipótese, e quebrá-la em séries temporais ou sob covariate shift exige extensões metodológicas como predição conformal sob não intercambialidade (Non-Exchangeable Conformal Prediction, NEx-CP), ACI, EnbPI e predição conformal ponderada (weighted CP). Para o quant brasileiro, o ponto crítico é o uso da predição conformal como instrumento de diagnóstico de risco de modelo. Há vários problemas em que a estrutura conformal entrega algo que o arsenal anterior não entregava com a mesma simplicidade, como calibração honesta de PD sob IFRS 9, intervalos de VaR que não dependam de normalidade dos retornos e conjuntos de previsão para classificação de regime que sinalizem dúvida do modelo em vez de mascará-la.
Cobertura marginal não basta. A literatura é unânime em recomendar o reporte do histograma de coberturas condicionais por subgrupo, e o uso de Mondrian CP quando a partição relevante for conhecida. O tratamento conjunto de validade marginal e diagnóstico condicional é o que separa um uso ingênuo do método de um uso defensável em ambiente regulatório.
Os próximos artigos desta série levarão essa estrutura para problemas concretos de finanças quantitativas, mantendo a mesma pergunta de fundo. Quando a garantia é útil, quando ela se degrada, que diagnóstico empírico revela a degradação e como a escolha do escore muda a utilidade do intervalo ou do conjunto de previsão. O caminho natural passa por regressão, séries temporais, calibração probabilística e classificação, mas a ordem e o recorte de cada aplicação dependem do problema empírico que se mostrar mais informativo. Para o leitor que quiser uma referência aplicada estendida em paralelo, o livro de Manokhin é o ponto de partida natural (MANOKHIN, 2023).
A predição conformal não resolve o problema de modelagem em finanças quantitativas, e nenhum método estatístico resolve. O que ela faz é colocar a quantificação de incerteza sobre fundação rigorosa, com garantia formal e custo computacional baixo. Para quem precisa entregar um número de risco com a defesa de uma cobertura garantida sob premissas explícitas, isso é base sólida.
Referências
ANGELOPOULOS, A. N.; BATES, S. Conformal Prediction: A Gentle Introduction. Foundations and Trends in Machine Learning, v. 16, n. 4, p. 494-591, 2023. DOI: 10.1561/2200000101.
BARBER, R. F.; CANDÈS, E. J.; RAMDAS, A.; TIBSHIRANI, R. J. The limits of distribution-free conditional predictive inference. Information and Inference: A Journal of the IMA, v. 10, n. 2, p. 455-482, 2021.
BARBER, R. F.; CANDÈS, E. J.; RAMDAS, A.; TIBSHIRANI, R. J. Conformal prediction beyond exchangeability. The Annals of Statistics, v. 51, n. 2, p. 816-845, 2023.
GIBBS, I.; CANDÈS, E. J. Adaptive Conformal Inference Under Distribution Shift. In: Advances in Neural Information Processing Systems 34 (NeurIPS 2021). 2021. p. 1660-1672.
KATH, C.; ZIEL, F. Conformal prediction interval estimation and applications to day-ahead and intraday power markets. International Journal of Forecasting, v. 37, n. 2, p. 777-799, 2021.
LEI, J.; G’SELL, M.; RINALDO, A.; TIBSHIRANI, R. J.; WASSERMAN, L. Distribution-Free Predictive Inference for Regression. Journal of the American Statistical Association, v. 113, n. 523, p. 1094-1111, 2018.
LEI, J.; WASSERMAN, L. Distribution-free prediction bands for non-parametric regression. Journal of the Royal Statistical Society: Series B, v. 76, n. 1, p. 71-96, 2014.
MANOKHIN, V. Practical Guide to Applied Conformal Prediction in Python. Birmingham: Packt Publishing, 2023. ISBN 978-1-80512-276-0.
PAPADOPOULOS, H.; PROEDROU, K.; VOVK, V.; GAMMERMAN, A. Inductive Confidence Machines for Regression. In: Machine Learning: ECML 2002. Lecture Notes in Computer Science, v. 2430. Berlin: Springer, 2002. p. 345-356.
ROMANO, Y.; BARBER, R. F.; SABATTI, C.; CANDÈS, E. J. With malice toward none: Assessing uncertainty via equalized coverage. Harvard Data Science Review, v. 2, n. 2, 2020.
ROMANO, Y.; PATTERSON, E.; CANDÈS, E. J. Conformalized Quantile Regression. In: Advances in Neural Information Processing Systems 32 (NeurIPS 2019). 2019.
SHAFER, G.; VOVK, V. A Tutorial on Conformal Prediction. Journal of Machine Learning Research, v. 9, p. 371-421, 2008.
STANKEVIČIŪTĖ, K.; ALAA, A. M.; VAN DER SCHAAR, M. Conformal Time-series Forecasting. In: Advances in Neural Information Processing Systems 34 (NeurIPS 2021). 2021.
TIBSHIRANI, R. J.; FOYGEL BARBER, R.; CANDÈS, E. J.; RAMDAS, A. Conformal Prediction Under Covariate Shift. In: Advances in Neural Information Processing Systems 32 (NeurIPS 2019). 2019. p. 2526-2536.
VOVK, V.; GAMMERMAN, A.; SHAFER, G. Algorithmic Learning in a Random World. 2. ed. Cham: Springer, 2022. ISBN 978-3-031-06648-1.
XU, C.; XIE, Y. Conformal Prediction Interval for Dynamic Time-Series. In: Proceedings of the 38th International Conference on Machine Learning (ICML 2021). PMLR, v. 139, 2021. p. 11559-11569.