
Prevenção de overfitting e data snooping em backtests
Protocolo de validação temporal (walk-forward) com purging/embargo e métricas deflacionadas (Sharpe-NW, DSR etc) para evidência out-of-sample robusta

Introdução
No desenvolvimento de estratégias quantitativas, é comum que modelos apresentem ótimo desempenho em testes históricos, mas fracassem ao serem aplicados em novos dados. Isso ocorre, muitas vezes, devido a overfitting (sobreajuste) aos dados passados ou a data snooping – quando escolhas de modelo ou parâmetros “vazam” informações do conjunto de teste, inflando indevidamente os resultados. Para construir backtests “inquebráveis” – ou seja, verdadeiramente robustos e confiáveis – é essencial adotar técnicas rigorosas de validação que previnam esses vieses.
Este artigo explora metodologias avançadas para validação temporal de estratégias financeiras e discute métricas estatísticas robustas para avaliação de performance, com foco na aplicação prática em três estratégias: momentum, pairs trading e sazonalidade. O objetivo é apresentar uma abordagem coesa para evitar ilusões de desempenho, garantindo que os resultados obtidos sejam consistentes e resistentes a sobreajustes e falsos positivos. Todo o código está disponível em PQ Backtests 1.
Validação temporal e otimização walk-forward
Uma forma fundamental de evitar sobreajuste em séries temporais é utilizar validação walk-forward, também conhecida como rolling ou expanding window backtesting. Diferentemente de uma simples separação treino-teste única, a validação walk-forward divide os dados em múltiplos splits temporais sequenciais. Em cada split, um modelo é treinado em um intervalo inicial de tempo (janela de treino) e então testado imediatamente no período subsequente (janela de teste) que o sucede cronologicamente. Em seguida, desliza-se a janela para frente (daí o termo walk-forward), frequentemente incorporando os dados de teste anterior ao novo treino, e repete-se o processo até percorrer toda a série histórica. Esse procedimento cria diversas avaliações out-of-sample genuínas, simulando a repetição do ciclo de treinamento -> teste que ocorreria na prática conforme o tempo avança.
A otimização de parâmetros do modelo é integrada a esse processo: em cada janela de treino realiza-se uma busca (por exemplo, grid search) pelos parâmetros ótimos segundo alguma métrica objetivo – tipicamente maximização do Sharpe Ratio anualizado ou outro retorno ajustado ao risco – e então esses parâmetros são fixados para gerar os sinais e retornos na janela de teste subsequente. Crucialmente, nenhum dado futuro é usado para treinar modelos destinados a prever períodos anteriores; cada teste ocorre em dados totalmente não vistos pelo modelo naquela iteração. Assim, a avaliação evita look-ahead bias (viés de espreitar o futuro) e reflete melhor como a estratégia reagiria em tempo real.
Purging e embargo: evitando vazamento de informação
Mesmo com a separação temporal, há casos sutis de vazamento de informação que podem ocorrer se não tomarmos cuidado. Por exemplo, suponha que o critério de entrada/saída de uma estratégia dependa de eventos futuros dentro de uma certa janela (como cálculo de retornos futuros para determinar rótulos de sinal). Nesses casos, alguns registros do conjunto de treino podem inadvertidamente conter informações sobre o período de teste – por exemplo, se o label de treino de uma amostra envolve preços que também estão no intervalo de teste. Para eliminar completamente essa contaminação, aplica-se a técnica de purging, que consiste em remover do treino quaisquer amostras cuja janela de informação se sobreponha ao período de teste. Na prática, se uma observação de treino precisasse de dados de horizonte de X dias à frente para calcular seu sinal (retornos futuros, por exemplo), então os X dias anteriores e posteriores a cada janela de teste são purgados do conjunto de treino, assegurando que nem mesmo “sombras” de informação futura estejam presentes no treinamento.
Além do purging, emprega-se o embargo temporal como salvaguarda adicional contra correlações entre retornos de treino e teste. O embargo impõe um hiato entre o fim da janela de teste e o início da próxima janela de treino, excluindo alguns dias imediatamente após cada período de teste antes de começar a aprender com dados subsequentes. Esse procedimento impede que efeitos de mercado que aconteceram no período de teste (por exemplo, reações a um evento específico) influenciem indevidamente o treinamento seguinte – afinal, em tempo real um trader também não teria como “reaprender” imediatamente após ver o resultado daquele teste, havendo um intervalo natural.
Em suma, combinando purging e embargo, garantimos separação absoluta entre informações de treino e teste, evitando vazamentos temporais. Essas práticas foram difundidas em grande parte pela literatura recente (LÓPEZ DE PRADO, 2018), sendo especialmente importantes em validações cruzadas com dados dependentes no tempo.
Configuração walk-forward por estratégia
No contexto do código PQ Backtests 1, adotamos configurações específicas de janela de treino, janela de teste e embargo adequadas a cada estratégia, com justificativas baseadas nas características das estratégias:
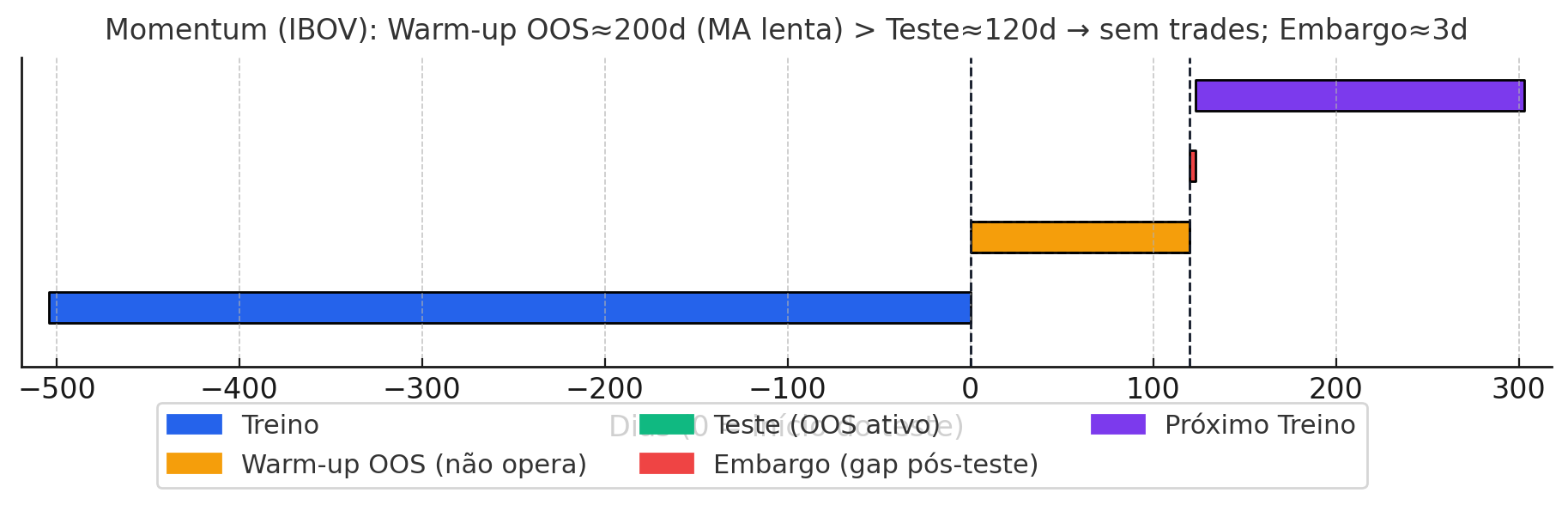
Momentum (IBOVESPA)
Janela: treino 24 meses, teste 6 meses, embargo 3 dias.
Racional: a estratégia usa cruzamento de médias móveis de longo prazo; ~504 dias úteis dão lastro para calibrar uma MM lenta de até 200d com boa estabilidade. O teste semestral casa com o rebalanceamento semestral, oferecendo validação out-of-sample relevante. O embargo curto é suficiente porque os sinais são de médio prazo, mas ainda evita “vazamento” imediato entre teste e novo treino.
Cuidados adicionais: há lag adaptativo de 1–2 dias após o cruzamento (curta vs. longa), garantindo uso apenas de dados passados e eliminando look-ahead. Regras: +1 se a curta ficou ≥1 dia acima da longa; –1 se abaixo; 0 caso contrário. Isso evita sinal e execução no mesmo dia com a mesma informação.
Benchmark: buy-and-hold do Ibovespa
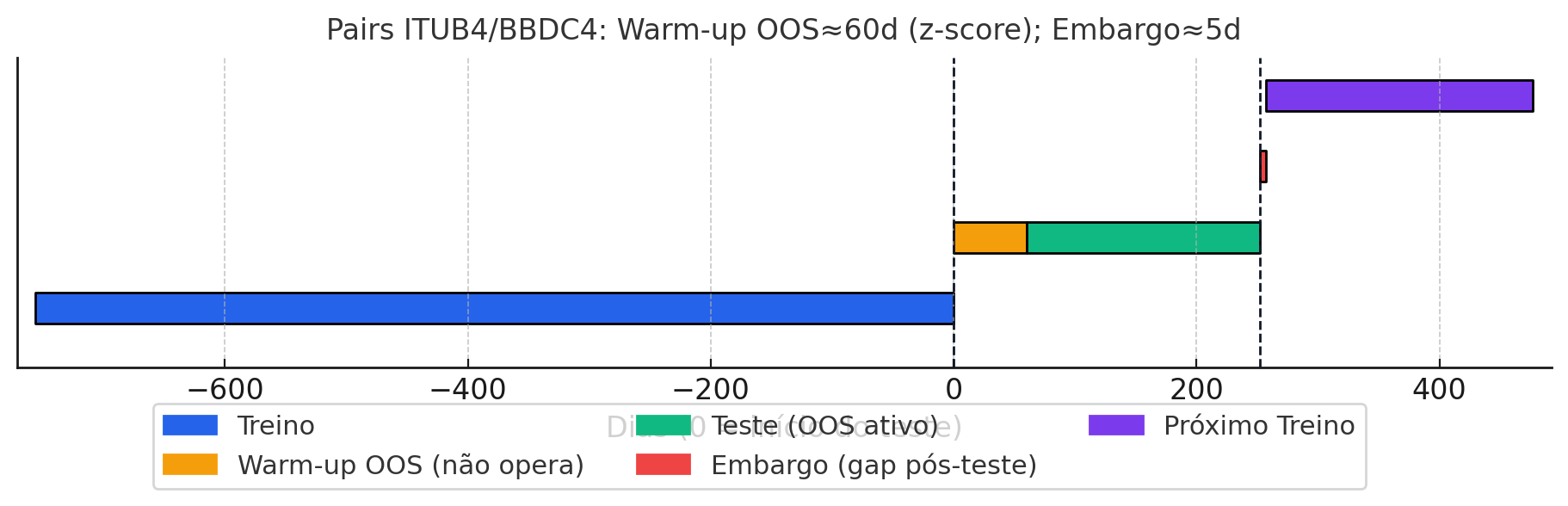
Pairs trading (ITUB4/BBDC4)
Janela: treino 36 meses, teste 12 meses, embargo 5 dias.]
Racional: 3 anos dão robustez para estimar o hedge ratio (β) via cointegração/regressão (log-preço), capturando a relação de equilíbrio do par. A estratégia usa uma janela interna móvel para média e desvio do spread, definida como ~1/3 do período (limitada a 20–80 dias), permitindo reagir a mudanças sem perder sinal. O teste anual cria amostra suficiente de aberturas/fechamentos do spread. O embargo maior reflete maior autocorrelação de curto prazo na reversão à média.
Cuidados adicionais: sinais via z-score do spread: short se > 2,0, long se < –2,0, zera perto de 0 (p.ex., 0,5). Há histerese (evita troca por ruído) e lag 1–2 dias para eliminar look-ahead. O β é recalibrado a cada treino, buscando capturar pequenos desvios que convergem à cointegração.
Benchmark: buy-and-hold de 50% de ITUB4 e 50% de BBDC4
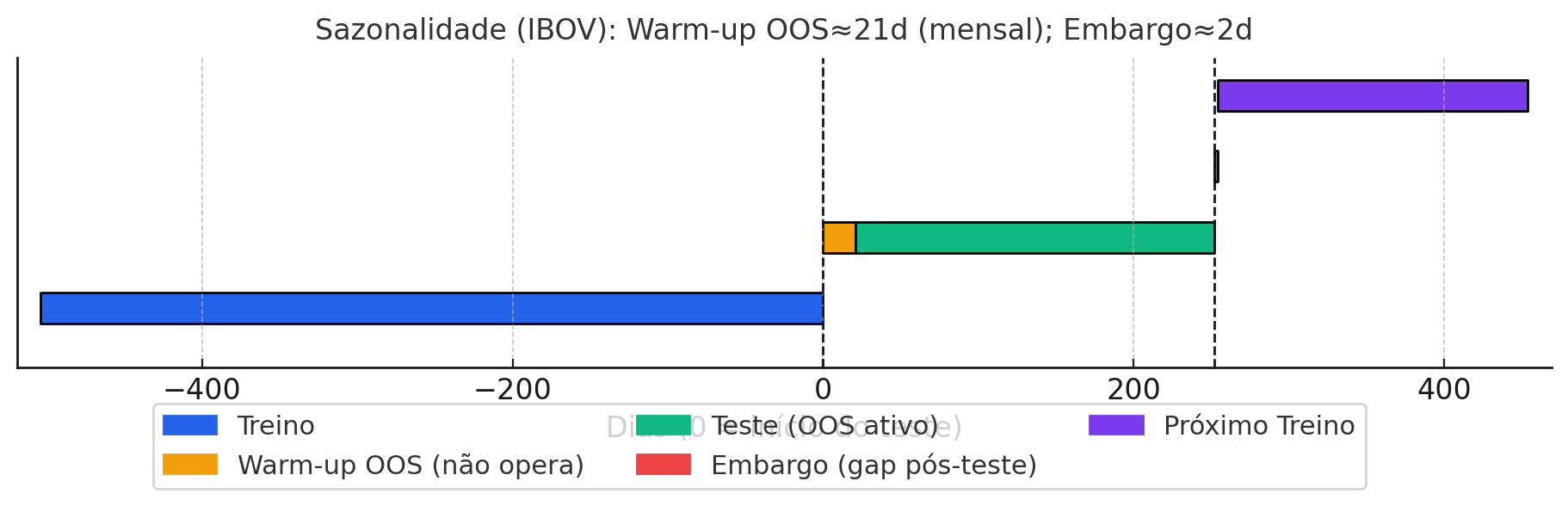
Sazonalidade (IBOVESPA)
Janela: treino 24 meses, teste 12 meses, embargo 2 dias.
Racional: explora padrões mensais (p.ex., “sell in May”, rally de fim de ano). 24 meses equilibram evidência e possíveis mudanças estruturais; 12 meses de teste cobrem um ciclo anual completo. O embargo curto basta pela baixa frequência (decisão mensal).
Cuidados adicionais: o ranking de meses é iterativo no walk-forward, usando apenas histórico disponível até cada decisão, evitando look-ahead. Seleciona-se top k e bottom k meses com k ≤ 6 (no máximo metade favorável/desfavorável). Exige ao menos ~8 meses únicos de histórico; caso contrário, a posição fica neutra para evitar overfitting inicial. Resultado: cada alocação mensal reflete o que um investidor saberia em tempo real.
Benchmark: buy-and-hold do Ibovespa
Com essas configurações, o backtest walk-forward reotimiza cada estratégia em cada janela (p.ex., médias no momentum, limiares de z-score no pairs e k na sazonalidade) e testa em múltiplos passos out-of-sample, gerando estimativas mais confiáveis e evidenciando estabilidade/regime-dependência que um único backtest poderia ocultar. Há controles automáticos: splits com <60 observações acionam alerta ou parâmetros padrão (Cochran, 1977); avisos quando não há trades em treino/teste; e tratamento de casos degenerados (volatilidade/drawdown zero) para não distorcer as métricas.
Métricas estatísticas robustas de performance
Tão importante quanto um design experimental sólido é a forma de medir e interpretar os resultados. Em ambientes com milhares de retornos diários e múltiplos períodos de teste, as métricas tradicionais podem falhar em capturar a significância real de uma estratégia. Por isso, adotamos um conjunto de métricas robustas que incorporam correções para autocorrelação, múltiplos testes e viéses estatísticos.
Sharpe Ratio (SR) com correção Newey-West
O Sharpe Ratio (SR) mede o retorno em excesso sobre a taxa livre de risco dividido pelo desvio-padrão, anualizado:
SR alto indica muito retorno por unidade de risco. Porém, em séries temporais com retornos não-i.i.d., a autocorrelação distorce σ e inflaciona o SR. LO (2002) mostrou a não-normalidade do SR e como estimar seu erro-padrão com lags.
Correção Newey–West (HAC): em séries com autocorrelação, substituímos a variância sob independência por um estimador HAC da variância (ou do erro-padrão da média). Seja γ̂ a autocovariância no defasagem k dos retornos em excesso; com kernel de Bartlett
e largura de banda L, a variância HAC é
Escolhemos L por regra de bolso e, em cenários mais conservadores, admitimos teto maior (até ∼n/4) para capturar caudas longas de dependência. Dessa forma, recalculamos o Sharpe corrigido:
Reportamos SR±SESR; um atalho útil para o erro-padrão do Sharpe é
e o uso de HAC melhora a confiabilidade desse SE quando há autocorrelação/heterocedasticidade.
Intuitivamente: quando os retornos têm autocorrelação positiva, o Sharpe “bruto” tende a ficar inflado; a correção Newey–West reduz esse valor para refletir melhor o risco efetivo. Se a autocorrelação é negativa (caso típico de estratégias de reversão), o ajuste costuma ser menor, mas ainda assim evita superestimar a significância. Em estratégias com carry ou P&L suavizado, a diferença entre o Sharpe “bruto” e o Sharpe corrigido por Newey–West costuma ser relevante — exatamente o que se deseja ao aplicar a correção.
Deflated Sharpe Ratio (DSR) e múltiplos testes
Muitos testes geram “vencedores” por sorte (HARVEY; LIU, 2015). O DSR (BAILEY; LÓPEZ DE PRADO, 2012) “desinfla” o SR observável combinando não-normalidade e penalização por multiplicidade. Primeiro estima-se o PSR (probabilidade de SR verdadeiro exceder 0/benchmark, com ajustes de skew e curtose). Depois, calcula-se um limite SR₀ esperado como máximo entre N tentativas sob H₀ (sem skill). Então:
onde Φ é a CDF da disitruição normal e divisor é o erro-padrão ajustado. Assim, DSR≈0,80 indica 20% de chance de “sorte”. No walk-forward, podemos computar DSR por split e agregar, ou usar N total de combinações testadas. Resultado: Sharpe alto após muitas tentativas pode virar DSR baixo; já Sharpe robusto mantém DSR alto.
Information Ratio (IR) e Deflated Information Ratio (DIR)
Para alpha relativo a um benchmark, usamos IR:
(anualizado; tracking error no denominador). Evitamos concatenar toda a série OOS: calculamos IR por split (alpha e tracking error de cada janela) e agregamos por média ponderada pelos dias do split, verificando consistência com alpha e tracking error globais.
Para refletir múltiplos testes também no âmbito relativo, usamos
Se DSR é baixo, DIR cai (alpha possivelmente casual); se DSR é alto, DIR fica próximo do IR. Isso integra magnitude de superação do benchmark e significância pós-seleção, reduzindo a chance de destacar falsos positivos.
Agregação ponderada de métricas e intervalos de confiança
Devido à natureza walk-forward, nossas estratégias geram múltiplos segmentos de retornos OOS. Uma abordagem ingênua seria concatenar todos os retornos fora-da-amostra em uma única série e então computar métricas sobre essa série combinada. Entretanto, essa prática pode introduzir viés: concatenação simples assume implicitamente pesos iguais por período ou mesmo distribuições estacionárias, o que nem sempre é o caso (por exemplo, um split de teste pode ter durado 3 meses e outro 6 meses; concatenar daria peso dobrado ao segundo). Para evitar isso, empregamos a média ponderada por split das métricas, atribuindo a cada janela de teste um peso proporcional ao número de observações (dias) naquela janela. Essa técnica, recomendada por Cochran (1977) para combinações de estimativas com tamanhos desiguais, produz uma estimativa global mais fiel.
Para agregar o Sharpe entre splits, calculamos o Sharpe de cada janela de teste e fazemos a média ponderada pelos dias daquela janela (splits maiores pesam mais). O erro-padrão dessa média vem de uma variância ponderada corrigida pelo número efetivo de graus de liberdade (ajuste de Cochran), que considera a distribuição dos tamanhos dos splits e evita que janelas muito curtas reduzam artificialmente a incerteza. Com esse erro-padrão, aplicamos um teste t para a hipótese de Sharpe médio igual a zero. Para o DSR, em vez de “promediar” diretamente valores por split (o que é problemático por ele se comportar como um nível de significância), preferimos estimar um DSR único a partir do Sharpe agregado e do total de tentativas realizadas, alinhado ao problema de múltiplas comparações.
Também reportamos o Sharpe composto, uma média geométrica dos Sharpe por split. Antes, deslocamos todos para valores positivos e, ao final, removemos o deslocamento. Na prática, é como multiplicar fatores e tirar a raiz enésima — isso reduz a influência de outliers. A leitura é útil: se a média aritmética ficar bem acima do composto, há instabilidade entre janelas; quando ambos ficam próximos, a consistência temporal é maior.
Por fim, usamos bootstrap para robustez adicional: reamostramos com reposição os retornos fora-da-amostra e recalculamos as métricas milhares de vezes (por exemplo, 1000 reamostragens), obtendo intervalos de confiança de 95% para o Sharpe médio, retorno total etc. O método dispensa normalidade e ajuda quando a distribuição das métricas é complexa (como o próprio DSR). Na apresentação, além de estrelas de significância para o Sharpe, damos uma leitura qualitativa do DSR: valores em torno de 0,5 sugerem alto risco de overfitting (resultado possivelmente casual), enquanto 0,95 indica forte evidência de skill genuíno mesmo após penalizar múltiplos testes.
Um trecho da saída só para exemplificar:
Resultados
Os números finais reforçam o motivo de usarmos métricas robustas e um pipeline walk-forward com purging e embargo: quando olhamos apenas para Sharpe “bruto”, podemos superestimar ou subestimar a evidência; com Newey-West, DSR e DIR, o quadro fica mais nítido — especialmente em amostras fracionadas por splits e sob múltiplas tentativas (LÓPEZ DE PRADO, 2018; HARVEY; LIU; ZHU, 2016; LO, 2002).
Momentum (IBOV)
A estratégia de momentum mostrou desempenho absoluto positivo e consistente, ainda que não espetacular, e — mais importante — com evidência estatística robusta após deflação:
Sharpe (média ponderada OOS): 0,8089 ± 0,3882 (p = 0,071). É um resultado “na trave” pelo t-teste tradicional, mas ainda assim indica vantagem média fora da amostra.
Sharpe (Newey-West): 0,7554 ± 0,5163. A correção HAC (NEWEY; WEST, 1987) alarga a incerteza (como esperado em séries com autocorrelação), mas não desmonta a tese de que há sinal.
Alpha anualizado vs IBOV: 7,3152%. Em termos econômicos, é um excesso que não depende de um único período e que sobrevive à concatenação OOS.
IR: 0,2374; DIR: 0,1953 (= 0,2374 × √0,6766). O IR é modesto, mas o DIR mostra que, após penalizar por múltiplos testes, ainda sobra contribuição relativa ao benchmark.
DSR: 0,6766 ± 0,1305 com *** (p = 0,001). Este é o ponto-chave: o Deflated Sharpe Ratio indica que a probabilidade de o Sharpe observado ser “sorte” é baixa mesmo considerando seleção/otimização (BAILEY et al., 2014; LÓPEZ DE PRADO, 2018).
O retrato por splits corrobora: há períodos muito bons (e.g., 2007 e 2024) e períodos fracos (e.g., 2017), além de um split sem operações (parâmetro 50×200 em 2012), que o relatório marca como N.A. — um comportamento esperado em trend following com filtros de média móvel. O Sharpe composto (0,5392) abaixo do Sharpe médio sugere heterogeneidade entre janelas (algumas muito fortes, outras mornas), mas sem invalidar o conjunto, pois o DSR* é elevado. Em suma: momentum passa no nosso crivo anti-overfitting — há alfa econômico (≈ 7,3% a.a.) e evidência estatística deflacionada que sustenta o resultado, mesmo com IR moderado.
Importante: estamos otimizando por Sharpe, que nem sempre é a métrica mais adequada. Ele não capta bem riscos de cauda, assimetria e curtose; e não penaliza drawdowns profundos, risco de “crash” em reversões rápidas, capacidade/liquidez. Por isso, a leitura correta combina o Sharpe (corrigido por Newey–West) com DSR/DIR e, idealmente, métricas complementares como Sortino, Calmar/MAR, Expected Shortfall (CVaR 95%), distribuição de max drawdown por janela e testes de estresse por regime. Essa bateria reduz o risco de selecionar um parâmetro “campeão de Sharpe”, mas frágil a eventos raros — especialmente relevante em estratégias de momentum.
Pairs trading (ITUB4/BBDC4)
No par bancário ITUB4/BBDC4, o veredito é claro: não há evidência robusta de habilidade no período, apesar de um alpha anual ligeiramente positivo.
Sharpe (média ponderada OOS): −0,821 ± 0,4101 (p = 0,139). O sinal absoluto é fraco/negativo; a incerteza não permite afirmar skill em retorno total.
Sharpe (Newey-West): −0,2826 ± 0,5142, coerente com o quadro de insignificância.
Alpha anualizado vs 50/50: 1,965%. O excesso médio relativo existe, mas é pequeno e instável.
IR: 0,074; DIR: 0,035 (= 0,074 × √0,2245). Após deflação, o IR encolhe para um nível economicamente irrelevante.
DSR: 0,2245 ± 0,1938 (p = 0,33). A leitura é direta: alta probabilidade de “sorte” dado o conjunto de tentativas/parametrizações.
Olhando os splits, 2011 tem Sharpe ligeiramente positivo; 2015, 2019 e 2023 são negativos — padrão típico quando o spread estrutural entre os bancos não permanece estável ou quando limiares de z-score capturam mais ruído do que reversão eficaz. A mensagem metodológica é importante: o WFO + DSR/DIR impediu que interpretássemos um alpha anual pequeno como “prova” de arbitragem; a evidência não sustenta a tese de skill.
Sazonalidade (IBOV)
A estratégia de sazonalidade ilustra um caso clássico em que uma ideia plausível estatisticamente se mostra frágil ao escrutínio robusto.
Sharpe (média ponderada OOS): 0,1765 ± 0,2618 (p = 0,522). Indistinguível de zero no agregado.
Sharpe (Newey-West): −0,013 ± 0,356. Com HAC, a vantagem desaparece totalmente.
Alpha anualizado vs IBOV: 1,1457% — pequeno e instável.
IR: 0,0283; DIR: 0,0200 (= 0,0283 × √0,499). Na prática, nulo.
DSR: 0,499 ± 0,1768 com * (p = 0,026). Há um sinal marginal quando visto sob o prisma do DSR, mas a magnitude é baixa e não resiste quando combinamos com o IR/DIR e com o Sharpe-NW ~ 0.
O padrão por splits é o de alternância: alguns anos favoráveis (2017, 2020) e outros ruins (2011, 2014). O resultado agrega para um efeito fraco, típico de anomalias de calendário que não são estáveis ao longo de regimes. O próprio DSR (~0,50) junto ao DIR ≈ 0,02 sinaliza que, mesmo que haja algo, é pequeno demais para ser explorado com confiança após penalizações por múltiplos testes (HARVEY; LIU; ZHU, 2016).
Conclusão
Construir backtests inquebráveis requer ir além do trivial. Neste artigo, enfatizamos uma abordagem integrada: (i) uso de validação temporal walk-forward com divisões múltiplas e mecanismos de purging e embargo para prevenir qualquer vazamento de informação entre treino e teste; (ii) escolha criteriosa de janelas de calibração e teste adaptadas à dinâmica de cada estratégia, garantindo que os modelos tenham dados suficientes para aprender sem extrapolar tendências efêmeras; (iii) aplicação de métricas estatísticas avançadas – Sharpe com correção de autocorrelação, Deflated Sharpe Ratio, Information Ratio ajustado e sua versão deflacionada – para julgar a significância dos resultados obtidos no contexto de múltiplos testes e natureza não-i.i.d. dos retornos financeiros.
Ao basear-nos tanto em fundamentos teóricos robustos (LO, 2002; BAILEY; LÓPEZ DE PRADO, 2012; HARVEY; LIU, 2015) quanto em ferramentas práticas automatizadas, conseguimos montar um arcabouço de teste que diminui radicalmente as chances de sobreajuste. Os controles anti-overfitting agem em várias camadas: desde não permitir que dados futuros “vazem” para o treinamento, até penalizar estatisticamente performances suspeitas que poderiam ter surgido pela sorte. Com isso, qualquer estratégia que “passe” por esse crivo rigoroso inspira muito mais confiança de que poderá desempenhar em ambientes de mercado reais e desconhecidos.
Em última instância, a construção de backtests confiáveis é tanto uma arte quanto uma ciência. Implica entender profundamente a estratégia sendo testada – seus horizontes, frequência, pressupostos – para configurar corretamente a validação temporal, e igualmente importante, implica tratar a análise de performance com o devido ceticismo quantitativo, usando as lentes das estatísticas robustas para separar o sinal do mero ruído. Seguindo essas práticas, evitamos cair nas armadilhas de data snooping e produzimos resultados que, se não garantem sucesso futuro (nada garante), ao menos resistem aos escrutínios e testes contra várias formas de viés.
Referências bibliográficas
BAILEY, D. H.; LÓPEZ DE PRADO, M. (2012). The Sharpe Ratio Efficient Frontier. Journal of Risk, 15(2), p.3–44.
COCHRAN, W. G. (1977). Sampling Techniques. 3ª ed. New York: John Wiley & Sons.
HARVEY, C. R.; LIU, Y. (2015). Backtesting. Working Paper – Duke University & Purdue University, July 2015.
LO, A. W. (2002). The Statistics of Sharpe Ratios. Financial Analysts Journal, 58(4), p.36–52.
LÓPEZ DE PRADO, M. (2018). Advances in Financial Machine Learning. Hoboken, NJ: John Wiley & Sons.