
Scraping de dados do Tesouro Direto com Julia: guia passo a passo
Como automatizar a coleta e análise de dados do Tesouro Direto com Julia

Acompanhar dados históricos de títulos públicos, como os do Tesouro Direto, é interessante para realizar estudos financeiros, avaliar tendências de mercado e tomar decisões de investimento mais embasadas. Contudo, acessar esses dados diretamente em formatos prontos para análise nem sempre é simples.
Neste post, vamos criar um projeto utilizando Julia, uma linguagem de alto desempenho e bastante adequada para análise de dados. Vamos mostrar como configurar o ambiente, baixar os dados e organizá-los em DataFrames, uma estrutura que facilita a manipulação e exploração.
Preparando o ambiente Julia
Antes de começar, precisamos configurar o ambiente de trabalho e instalar os pacotes necessários.
Passo 1: Instalando o Julia
Faça o download do Julia no site oficial (julialang.org) e siga as instruções de instalação para o seu sistema operacional.
Passo 2: Configurando um ambiente de projeto
No terminal do Julia (REPL), crie um ambiente específico para este projeto. Isso mantém as dependências organizadas.
Passo 3: Instalando as dependências
Instale os pacotes necessários para o projeto:
Agora, o ambiente está pronto para receber o código!
1. Baixando dados do Tesouro Direto
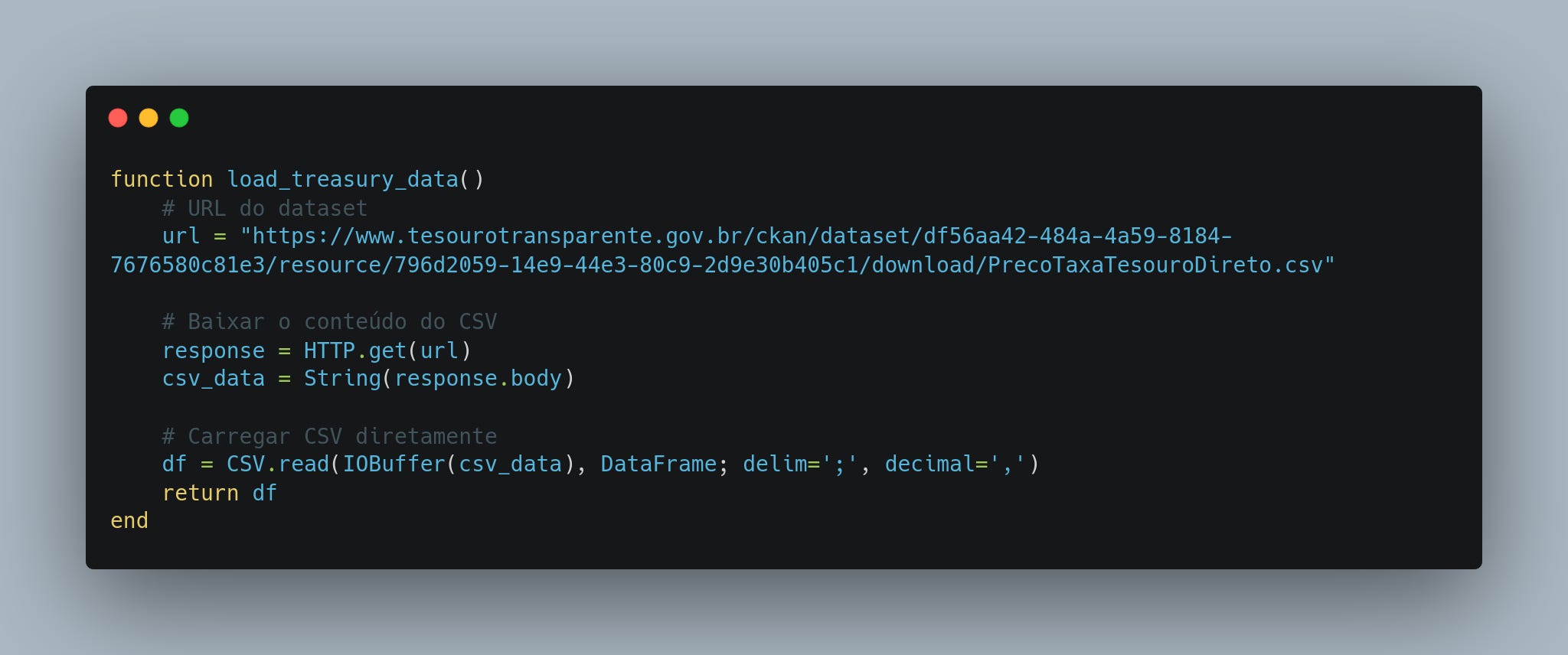
A função load_treasury_data baixa um arquivo CSV que contém informações detalhadas sobre os preços e taxas dos títulos do Tesouro Direto. Este arquivo é disponibilizado publicamente no site do Tesouro e atualizado regularmente. O script completo desse artigo está aqui → scraping_tesouro.jl.
Como funciona?
Fazemos uma requisição HTTP para obter o arquivo CSV.
Os dados são lidos diretamente na memória e convertidos para um DataFrame, uma estrutura que organiza as informações em formato de tabela.
Utilidade
Esse conjunto de dados é uma base importante para:
Estudar o histórico de preços e taxas dos títulos públicos.
Entender a dinâmica entre diferentes tipos de títulos ao longo do tempo.
Fazer comparações ou projeções financeiras.
2. Filtrando os dados
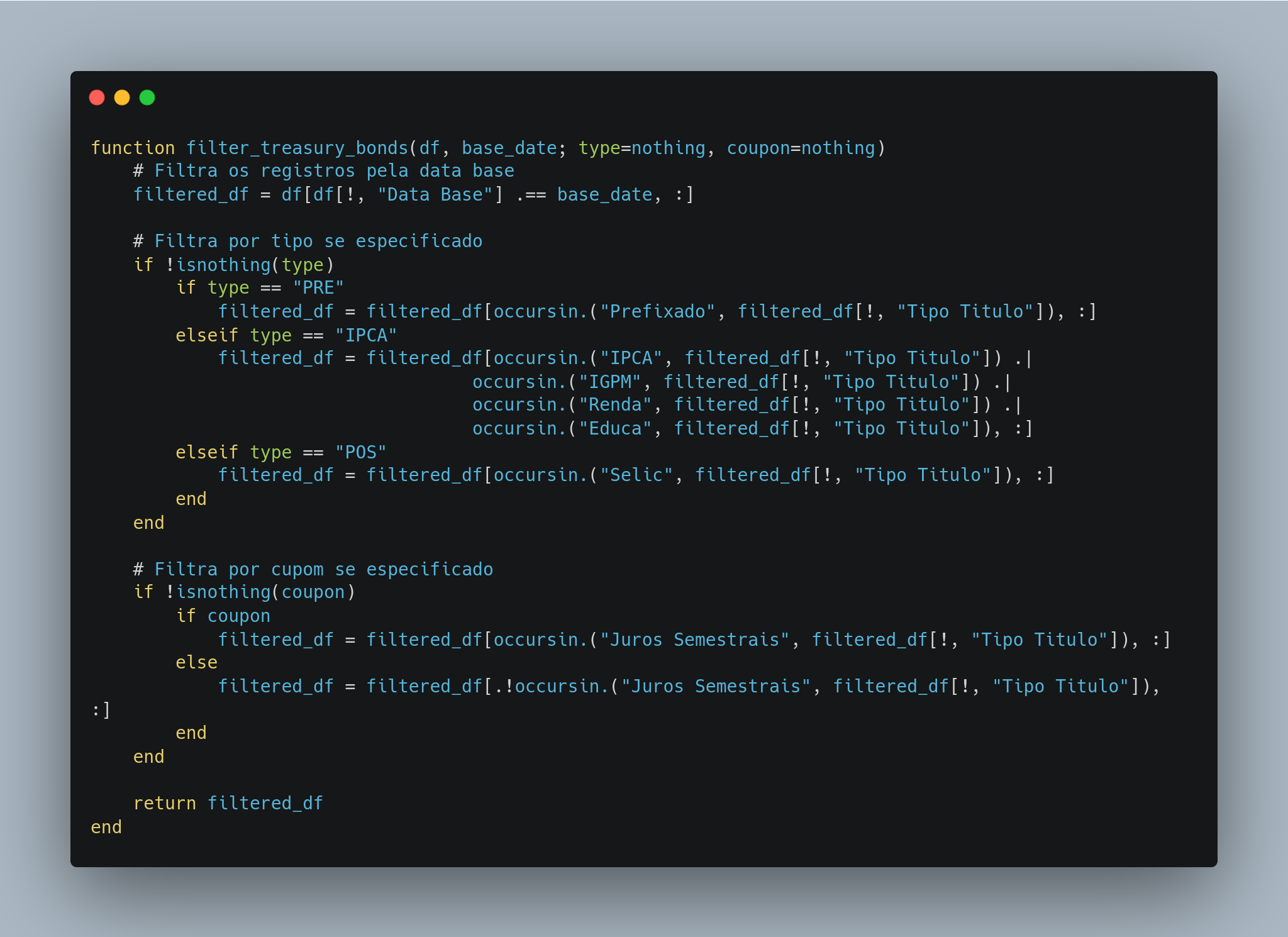
Nem sempre você precisa de todo o dataset. A função filter_treasury_bonds permite filtrar os dados com base em critérios específicos, como o tipo de título, a presença de juros semestrais ou uma data base.
Como funciona?
Filtro por tipo de título: Títulos prefixados, atrelados à inflação (IPCA) ou pós-fixados (Selic).
Filtro por juros semestrais: Incluir ou excluir títulos com pagamento periódico de juros.
Filtro por data: Seleciona registros de uma data específica.
Utilidade
Com essa função, é possível:
Focar nos títulos de maior interesse (por exemplo, prefixados), podendo analisar uma data específica.
Analisar títulos com cupons semestrais e comparar seus pagamentos com outros investimentos.
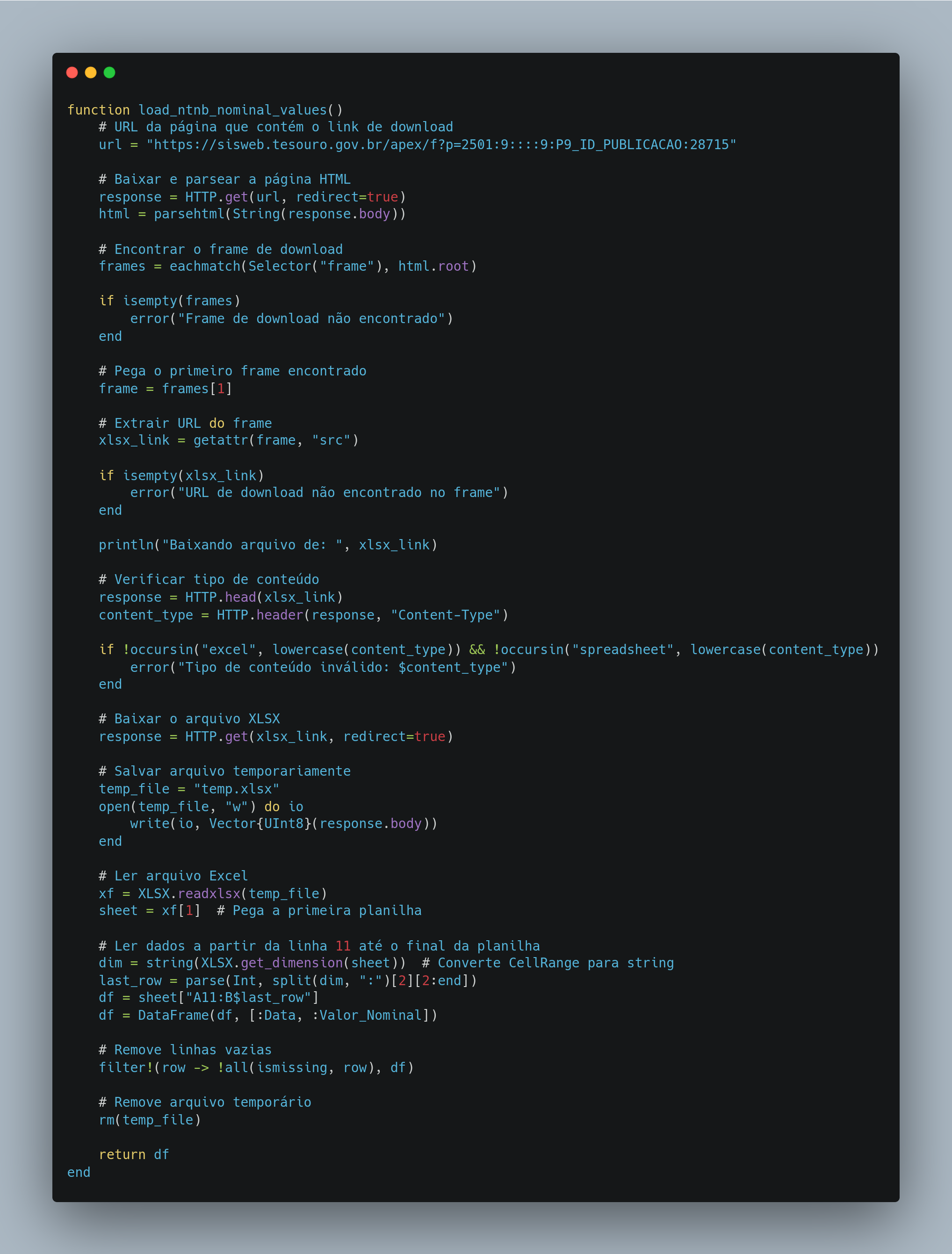
3. Baixando os valores nominais das NTN-Bs
Essa função faz o scraping de uma página HTML para obter um arquivo Excel que contém os valores nominais das NTN-Bs. Este dado é essencial para calcular rentabilidades históricas de títulos corrigidos pelo IPCA.
Exige algum esforço saber qual página acessar para você achar os seus dados de interesse. Em algum caso, como este, o link pode ser gerado dinamicamente, ou ser alterado sem aviso prévio. O uso de certas bibliotecas como explicadas a seguir, mitigam um pouco esse problema.
Gumbo e Cascadia são bibliotecas em Julia usadas para scraping de páginas web. Gumbo processa o HTML bruto de uma página, transformando-o em uma estrutura DOM (Document Object Model), que organiza os elementos HTML em uma hierarquia navegável. Cascadia complementa o Gumbo, permitindo buscar elementos específicos no DOM utilizando seletores CSS, como .classe, #id ou tags como <frame> e <a>. Juntas, essas ferramentas tornam o scraping mais eficiente e estruturado, facilitando a extração de informações mesmo em páginas com HTML complexo ou dados aninhados em elementos específicos.
Como funciona?
Baixamos a página HTML usando
HTTP.get.Usamos as bibliotecas
GumboeCascadiapara encontrar o link do arquivo Excel.Fazemos o download do Excel, processamos as informações relevantes e retornamos um DataFrame organizado.
Utilidade
Esses valores são fundamentais para:
Estimar quanto foi pago de cupom em determinada época, uma vez que os cupons desses títulos são baseados nesses valores.
Estudar a evolução histórica do valor nominal das NTN-Bs.
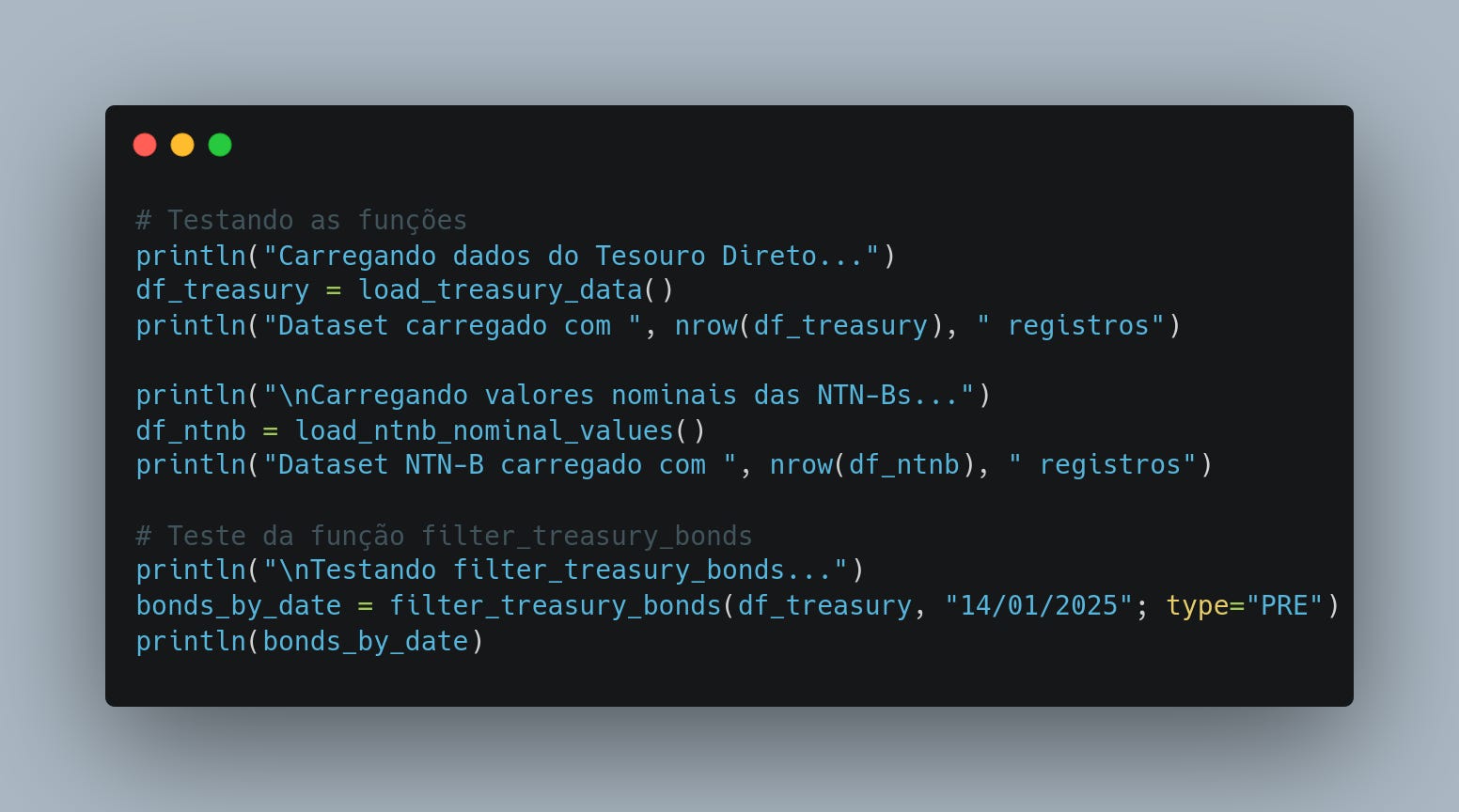
Testando o código
Por fim, integramos as funções para verificar se os dados foram carregados corretamente.
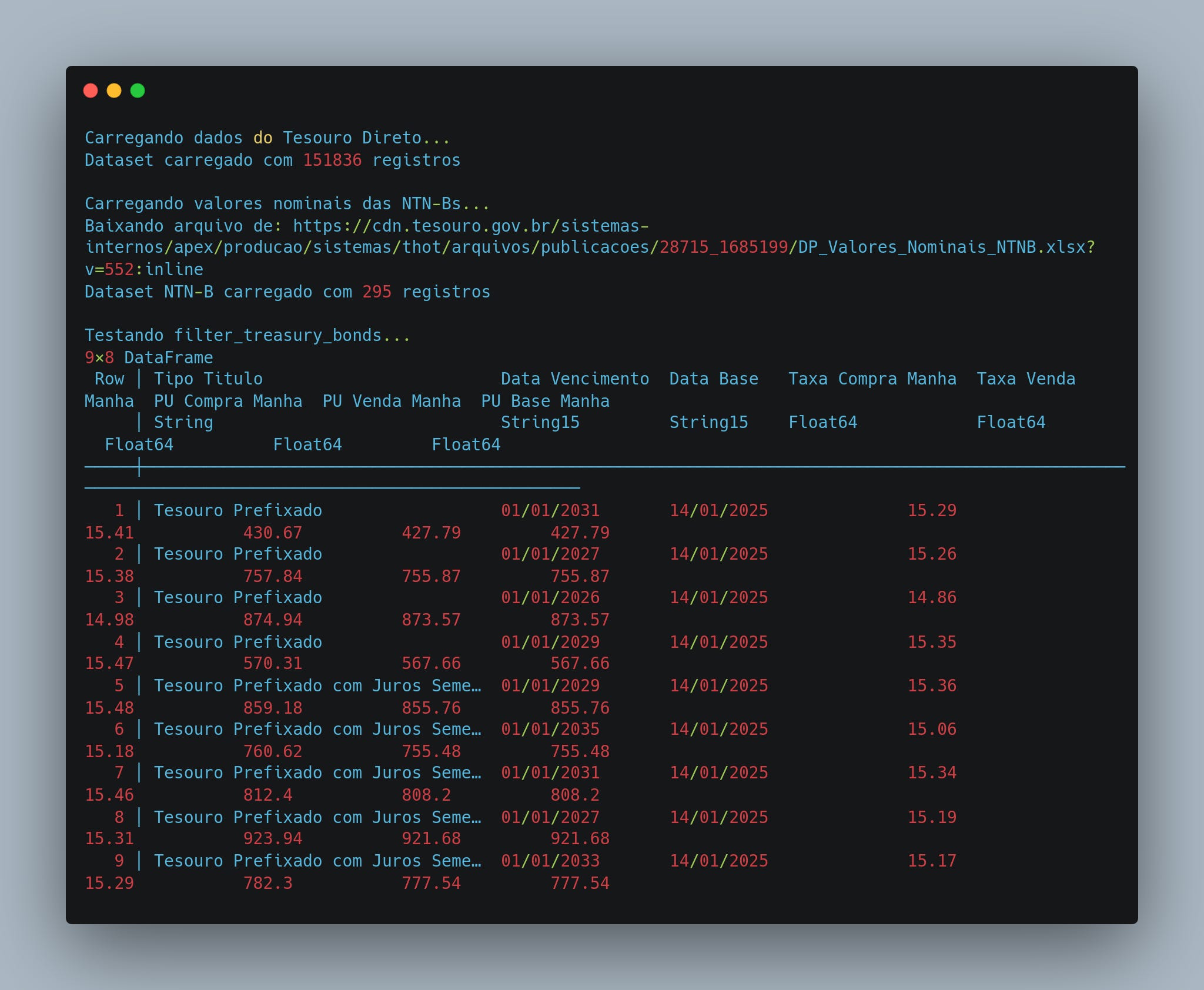
Os resultados obtidos:
Até a próxima!