
Uma Métrica, Uma Verdade: como camadas semânticas e linguagem natural estão criando o BI confiável que finanças sempre precisou
A convergência entre modelos semânticos e LLMs text-to-SQL representa a infraestrutura que resolve o problema mais antigo dos dados financeiros: garantir que todo mundo fale do mesmo número.

Na manhã de uma segunda-feira qualquer, dois analistas de uma mesma instituição financeira recebem a mesma pergunta da diretoria: “Qual foi o P&L do desk de câmbio na semana passada?” O analista de front-office abre seu sistema, aplica marcação a mercado intraday com preços de tela, e responde: R$ 4,2 milhões positivos. O controller de middle-office consulta o sistema contábil, usa preços de fechamento da ANBIMA e aplica critérios de hedge accounting: R$ 2,8 milhões positivos. Duas respostas para a mesma pergunta. Nenhuma está errada, pois cada uma reflete uma definição legítima de “P&L”. Mas o diretor que recebe dois números diferentes perde a confiança nos dados, e a reunião que deveria durar vinte minutos se transforma em uma hora de reconciliação.
Cenários como esse são rotineiros. Uma pesquisa da McKinsey de 2019 revelou que mais de 70% dos grandes bancos possuíam ao menos três sistemas calculando métricas de risco sobrepostas com inconsistências, especialmente em VaR, retornos e spreads. O caso mais emblemático é o do JPMorgan em 2012: o Chief Investment Office utilizava um modelo de VaR com parâmetros diferentes do modelo firm-wide, e quando as perdas começaram a aparecer, a equipe alterou o modelo no meio do trimestre, efetivamente redefinindo a métrica. Limites de risco foram violados mais de 330 vezes em quatro meses sem que houvesse alguma ação, porque o dashboard consolidado não detectou a inconsistência. Perda total: US$ 6,2 bilhões (US SENATE, 2013).
A raiz do problema é a falta de significado compartilhado sobre o que cada dado representa. A convergência entre camadas semânticas e modelos de linguagem (large language models, LLMs) promete preencher esse vazio, codificando uma única vez a definição canônica de cada métrica e permitindo que qualquer consumidor (um dashboard, um relatório regulatório, ou uma pergunta em linguagem natural) obtenha exatamente o número correto para aquela definição.
O problema semântico em dados financeiros internos
Instituições financeiras operam com uma complexidade de dados que poucos setores enfrentam. Uma tesouraria de banco de médio porte mantém dezenas de tabelas de posições, instrumentos, preços, curvas, calendários, limites, contrapartes e eventos corporativos. Sobre essa base, diferentes áreas calculam métricas que, embora compartilhem o mesmo nome, diferem em definição.
Considere o conceito aparentemente simples de “retorno mensal de um ativo”. Existem ao menos três definições válidas:
O retorno aritmético simples. Mas “P_t” é o preço de fechamento do último dia do mês, ou do último dia útil? Ajustado por proventos ou não? E o retorno logarítmico
E o retorno total, que incorpora dividendos reinvestidos:
Um analista de front-office pode usar o retorno aritmético sobre preços de fechamento sem ajuste. O gestor de portfólio usa retorno total com dividendos reinvestidos. O time de risco usa retorno logarítmico para modelagem de distribuições. Se cada um escreve sua própria consulta SQL diretamente contra o banco de dados, o resultado são três números diferentes que, reportados sem contexto, geram confusão e desconfiança.
Mas a ambiguidade das fórmulas é apenas a superfície do problema. Antes de decidir qual fórmula usar, o analista (ou o LLM) precisa encontrar os dados certos dentro de uma topologia que raramente é autoexplicativa.
Uma tesouraria típica de banco de médio porte opera com 80 a 200 tabelas no data warehouse. Os nomes refletem convenções internas acumuladas ao longo de décadas: TB_POSICAO_D0, VW_RISCO_CARTEIRA_HIST, DIM_INSTRUMENTO_RF, FT_MTM_DERIVATIVO, STG_ANBIMA_PRECOS.
Os nomes das colunas são igualmente opacos: dt_ref, dt_pos, dt_liq e dt_cot representam datas diferentes (referência, posição, liquidação e cotação), mas nenhuma documentação inline explica a diferença. vl_mtm, vl_curva, vl_contabil e vl_mercado parecem sinônimos, mas refletem critérios de valorização distintos que afetam diretamente o P&L reportado.
Os relacionamentos entre essas tabelas são o obstáculo mais sério. Para calcular o VaR de uma carteira de renda fixa, por exemplo, não basta consultar uma tabela de “risco”. O caminho real envolve cinco ou seis joins: partir de risk_metrics, encontrar a carteira correta em portfolios, mapear os instrumentos via portfolio_instruments, buscar classificações em instrument_classification para filtrar “renda fixa”, e ainda cruzar com calendars para resolver a data de referência como dia útil.
Um analista que conheça o esquema faz isso sem pensar. Um LLM que receba apenas os nomes das tabelas tem chances consideráveis de escolher o join errado ou ignorar uma tabela intermediária, produzindo um número sintaticamente válido mas semanticamente incorreto.
Essa complexidade estrutural se soma à ambiguidade das fórmulas. O Sharpe ratio pode ser calculado com taxa livre de risco fixa ou variável, com volatilidade histórica ou EWMA. O VaR pode ser paramétrico, histórico ou Monte Carlo, com janelas de 252 ou 504 dias úteis. O duration pode ser Macaulay, modificado ou efetivo. Cada combinação é legítima em seu contexto; o problema surge quando não existe uma autoridade central que defina qual combinação se aplica a qual contexto.
A Gartner estimou em 2021 que organizações perdem, em média, US$ 12,9 milhões por ano (para bancos é ainda maior), devido a problemas de qualidade de dados (GARTNER, 2021). Em finanças, onde um erro de 5% em um relatório regulatório pode gerar multas e sanções, o custo da inconsistência semântica é ainda maior.
Anatomia de uma camada semântica
Uma camada semântica é uma abstração declarativa que se posiciona entre os dados brutos (tabelas, colunas, esquemas físicos) e os consumidores desses dados (dashboards, relatórios, APIs, perguntas em linguagem natural). Sua função é codificar o significado de negócio dos dados, descrevendo o que eles representam independentemente de como estão armazenados.
Tim Berners-Lee propôs em 2001 a visão da Semantic Web: uma extensão da web onde “a informação recebe significado bem-definido, permitindo que computadores e pessoas cooperem melhor” (BERNERS-LEE; HENDLER; LASSILA, 2001). Embora a Semantic Web completa não tenha se materializado como previsto, sua percepção central, de que dados precisam de uma camada descritiva de significado para serem universalmente compreendidos, é exatamente o que as camadas semânticas modernas implementam para dados analíticos.
No mundo de data warehousing, a herança conceitual vem de Ralph Kimball: a modelagem dimensional com tabelas de fatos (medidas numéricas) e tabelas de dimensões (atributos descritivos) é a precursora direta das camadas semânticas modernas (KIMBALL; ROSS, 2013). O que mudou é que a camada semântica atual torna esse modelo lógico agnóstico de banco de dados e agnóstico de ferramenta, com definições que existem independentemente de onde os dados estão armazenados ou de qual ferramenta os consome.
Na prática, uma camada semântica codifica quatro tipos de informação:
Métricas — fórmulas de negócio com definição precisa. Exemplo: var_99_1d é definido como o percentil 1% da distribuição de P&L simulado, sobre a tabela risk_metrics, filtrado por holding_period = 1 e confidence_level = 0.99. Não há ambiguidade: todo consumidor que referencia var_99_1d obtém exatamente esse cálculo.
Dimensões — atributos de corte e filtro. Exemplo: asset_class (renda fixa, renda variável, câmbio), desk (tesouraria, proprietário, hedge), business_date (com lógica de dias úteis embutida).
Relacionamentos — joins pré-definidos entre entidades. A camada semântica sabe que positions se conecta a instruments via instrument_id, que instruments se conecta a issuers via issuer_id, e que prices se conecta a instruments e calendars. Esses caminhos de join são declarados uma vez e reutilizados em qualquer consulta.
Hierarquias — caminhos de drill-down. Exemplo: ano → trimestre → mês → dia útil, ou classe de ativo → subclasse → instrumento.
Uma analogia útil vem da ciência da computação: a camada semântica funciona como um type system para dados analíticos. Assim como um type checker em uma linguagem de programação rejeita a operação string + int em tempo de compilação, antes que o erro chegue à execução, uma camada semântica rejeita combinações inválidas de métricas e dimensões antes que a consulta chegue ao banco de dados. Robin Milner cunhou o princípio de que “programas bem-tipados não dão errado” (MILNER, 1978); analogamente, consultas bem-tipadas pela camada semântica não produzem números errados.
LLMs e text-to-SQL: a promessa e as armadilhas
A ideia de consultar dados em linguagem natural (NLQ, Natural Language Query, ou text-to-SQL) ganhou viabilidade prática com o avanço dos LLMs. Em vez de escrever SQL ou depender de uma equipe de dados para construir cada relatório, o analista simplesmente pergunta “Qual a exposição total a crédito corporativo com rating abaixo de AA?” e recebe a resposta.
Os LLMs são genuinamente bons na compreensão de intenção. Entendem que a pergunta acima pede uma agregação, um filtro e uma dimensão temporal implícita. O problema é traduzir essa compreensão em SQL correto contra um esquema real.
Os benchmarks acadêmicos dimensionam o desafio. O Spider, benchmark fundacional para text-to-SQL (YU et al., 2018), mostrou acurácia de ~86% com os melhores modelos em esquemas limpos. O BIRD, com dados reais e sujos (LI et al., 2023), derruba para 54-72%. O FINCH, primeiro benchmark dedicado a dados financeiros (33 databases, 292 tabelas, 75.725 pares NL-SQL), mostra quedas adicionais de 15-30% em relação aos genéricos.
Uma análise sistemática de erros (FLORATOU et al., 2024) identificou as principais categorias de falha:
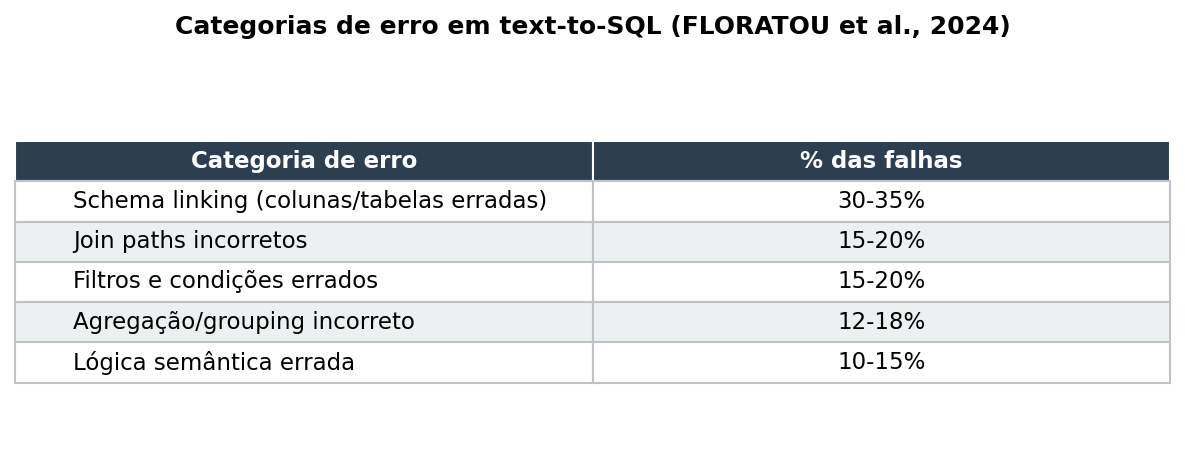
Para dados financeiros, o quadro é agravado por fatores que benchmarks genéricos não capturam. Alinhamento temporal é o desafio número um: consultas financeiras quase sempre envolvem dias úteis, anos fiscais, datas de liquidação e as-of dates. Um LLM que gera WHERE date = '2026-03-06' sem verificar se é dia útil pode retornar dados inexistentes. Ações corporativas (splits, bonificações, grupamentos) criam descontinuidades que exigem ajuste nos preços. Esquemas massivos com centenas de tabelas multiplicam as chances de erro.
Na prática, acurácia de 80% em benchmarks genéricos pode significar 50% ou menos em dados financeiros reais. E em finanças, um número aproximado frequentemente é pior que nenhum número, porque gera falsa confiança.
A convergência: camada semântica como guardrail do LLM
Em vez de expor o esquema bruto ao LLM, a abordagem que vem ganhando tração é restringir o espaço de atuação do modelo com um pipeline semântico estruturado em etapas:
Pergunta em linguagem natural — a entrada do usuário
Intent extraction — o LLM identifica tipo de consulta, entidades e contexto temporal
Entity mapping contra o modelo semântico — cada termo é resolvido contra definições pré-existentes. “VaR 99%” é mapeado à métrica
var_99já definida com fórmula, tabela-fonte e filtros canônicosSQL generation restrita — o LLM gera SQL apenas com referências a métricas e dimensões do modelo semântico
Validação e execução — a consulta é verificada contra as regras do modelo
Resposta formatada + linhagem — resultado com definição da métrica, consulta gerada e linhagem do dado
Em 2024, a AtScale publicou um benchmark usando o dataset TPC-DS com 40 perguntas de negócio que quantifica esse ganho (ATSCALE, 2024):
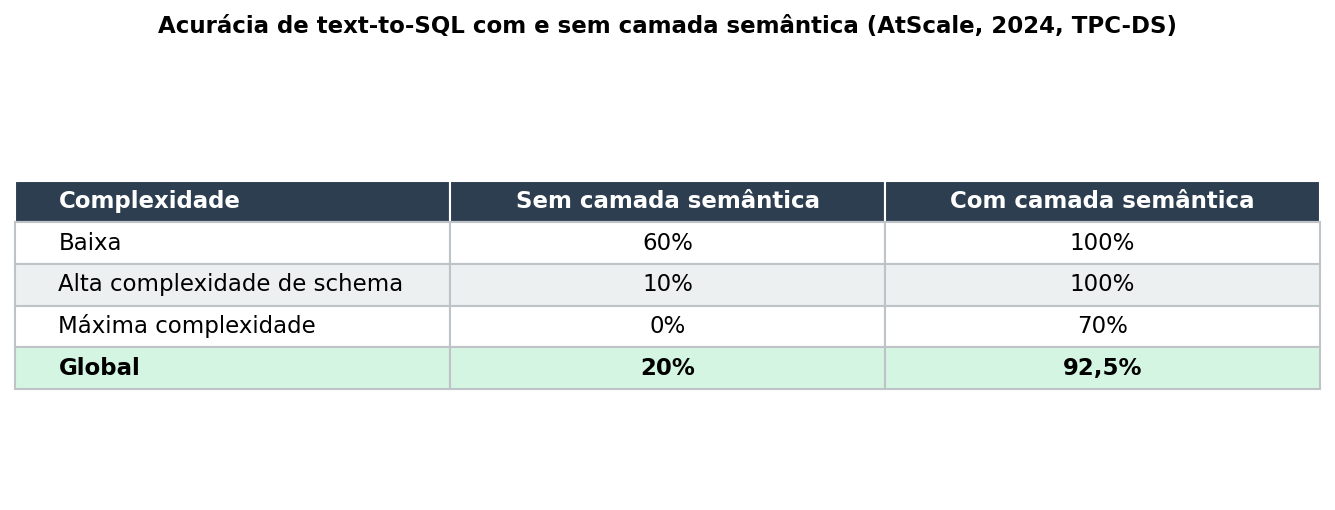
O salto de 20% para 92,5% confirma o que a análise de erros já sugeria: a camada semântica elimina categorias inteiras de erro. Schema linking incorreto desaparece porque o LLM só referencia entidades mapeadas. Joins errados são raros porque os caminhos são pré-definidos. Ambiguidade de métricas desaparece porque cada métrica tem uma única definição.
Exemplos concretos
Exemplo 1: VaR da carteira de renda fixa
Pergunta do gestor de risco: “Qual foi o VaR 99% da carteira de renda fixa ontem?”
Sem camada semântica, o LLM recebe o esquema bruto com dezenas de tabelas e precisa navegar uma topologia que não é autoexplicativa. Só no perímetro de risco, há tabelas como risk_metrics, risk_scenarios, risk_params_hist e risk_limits. “VaR” aparece como coluna em risk_metrics (vl_var_99, vl_var_95), mas também em risk_daily_summary (var_1d, var_10d), com diferenças sutis de periodicidade e escopo. Para filtrar “renda fixa”, o LLM precisa decidir entre asset_class em portfolios, tp_classe em instrument_classification, ou cd_segmento em DIM_INSTRUMENTO_RF, cada um com granularidades diferentes.
O caminho de join correto envolve cinco tabelas: risk_metrics → portfolios → portfolio_instruments → instruments → instrument_classification. Se o LLM pula a tabela intermediária portfolio_instruments e tenta ligar risk_metrics diretamente a instruments, o resultado é um produto cartesiano ou um filtro que não restringe a carteira corretamente.
E “ontem” precisa ser resolvido como dia útil, consultando calendars (onde dt_ref é diferente de calendar_date). O LLM gera seu melhor palpite, que pode retornar o VaR de toda a carteira sem filtro, usar um dia que não é útil, ou confundir VaR 1-dia com 10-dias. Sem inspecionar a consulta, não há como saber se o número está certo.
Com camada semântica, cada termo é resolvido contra definições pré-existentes:
“VaR 99%” → métrica
var_99_1d:value FROM risk_metrics WHERE metric_type = 'VAR' AND confidence_level = 0.99 AND holding_period = 1“carteira de renda fixa” →
portfolio_asset_class = 'fixed_income', join pré-definidorisk_metrics → portfolios → portfolio_classification“ontem” →
MAX(business_date) FROM calendars WHERE is_business_day = TRUE AND calendar_date < CURRENT_DATE
Resultado: “O VaR 99% 1-dia da carteira de renda fixa em 06/03/2026 foi de R$ 12,4 milhões. Fonte: risk_metrics, D-1 útil, simulação histórica 504 dias.” O número vem com linhagem.
Exemplo 2: P&L segregado por tratamento contábil
Pergunta do controller: “Qual foi o resultado do desk de câmbio no mês, segregando trading e hedge accounting?”
Sem camada semântica, o LLM não tem como inferir que “resultado” neste contexto significa duas métricas distintas que vivem em locais diferentes do esquema. O P&L de trading vem de FT_RESULTADO_TRADING, calculado com marcação a mercado intraday contra preços de tela, enquanto o P&L de hedge accounting vem de VW_RESULTADO_HEDGE, que aplica preços de fechamento ANBIMA e filtros de classificação IFRS 9 (cd_hedge_type IN ('FAIR_VALUE', 'CASH_FLOW')).
As duas views compartilham colunas de mesmo nome (vl_resultado, dt_ref, cd_desk), mas com semânticas diferentes: vl_resultado em trading inclui ajustes de spread, enquanto em hedge accounting exclui. Um LLM que encontra apenas uma das tabelas retorna uma soma geral que mistura tratamentos contábeis, ou pior, soma as duas views gerando dupla contagem.
Com a camada semântica, o sistema reconhece que “segregando” aciona duas métricas pré-definidas (pnl_trading com regra de mark-to-market intraday, e pnl_hedge_accounting com regra IFRS 9), cada uma com sua tabela-fonte e filtros específicos, e as apresenta lado a lado.
O ecossistema de ferramentas: quem materializa esses conceitos
Os exemplos acima ilustram como camada semântica e NLQ funcionam conceitualmente; na prática, esse pipeline é implementado por plataformas que variam em arquitetura e abrangência. O mercado se organiza em três camadas, cada uma com contrapartidas distintas.
Warehouse-native: a camada semântica embutida no banco
Um exemplo é o Snowflake Cortex Analyst, que permite definir modelos semânticos em YAML diretamente no Snowflake. O LLM (Mistral ou Meta Llama, hospedado dentro do Snowflake) recebe a pergunta em linguagem natural, consulta o modelo semântico para resolver entidades e métricas, e gera SQL executado no warehouse do próprio cliente. O dado nunca sai do perímetro de governança, nem metadata nem prompts. O custo é zero para clientes Snowflake existentes. O Databricks LakehouseIQ segue abordagem similar, mas com diferencial: aprende automaticamente do uso do ambiente de trabalho (notebooks, consultas, dashboards), construindo contexto organizacional de forma incremental. O Google BigQuery + Gemini integra text-to-SQL via Gemini diretamente no console do GCP (Google Cloud Platform).
A vantagem dessa abordagem (warehouse-native) é a fricção zero: se a empresa já usa o warehouse, a camada semântica é uma extensão natural. A limitação é a dependência de fornecedor, pois o modelo semântico é proprietário e preso ao ecossistema do fabricante.
Se a abordagem warehouse-native amarra a camada semântica ao banco, a alternativa é posicioná-la como middleware independente.
Middleware semântico: a camada universal independente
O Cube (D3 platform) é o líder em headless BI, uma camada semântica API-first que serve métricas consistentes via SQL, REST, GraphQL e MDX para qualquer interface. Lançou em 2025 suporte a AI agents nativos e ao MCP (Model Context Protocol), permitindo que agentes de IA consumam métricas governadas. O semantic caching e as pre-aggregations otimizam performance sem sacrificar consistência.
O AtScale posiciona-se como camada semântica universal sobre Snowflake, Databricks e BigQuery. Criou o SML (Semantic Modeling Language), primeira linguagem de código aberto para modelos semânticos, e mantém compatibilidade com Excel e Tableau via MDX/DAX, o que importa para instituições financeiras onde Excel ainda é a interface dominante. Foi a AtScale que publicou o benchmark mostrando o salto de 20% para 92,5% de acurácia com camada semântica.
O dbt Semantic Layer (MetricFlow), código aberto sob Apache 2.0, define métricas junto aos modelos de transformação do dbt. O foco é na definição consistente de métricas, sem NLQ direto, mas serve como fundação semântica que outras ferramentas de NLQ podem consumir.
O Looker (LookML) foi pioneiro em “camada semântica como código” e continua maduro e com forte governança, embora preso ao ecossistema Google Cloud.
Além dessas plataformas estabelecidas, um ecossistema de código aberto vem expandindo as fronteiras do que é possível.
Código aberto e startups: inovação na fronteira
O Wren AI é o projeto de código aberto mais alinhado com a visão de camada semântica + NLQ integrados. Desenvolveu o MDL (Modeling Definition Language), formato em JSON que define modelos semânticos com entidades, relacionamentos, cálculos reutilizáveis e macros. A arquitetura é com privacidade como prioridade: apenas metadata vai ao LLM, nunca dados reais. O Wren Engine transpila “WrenSQL” para o dialeto do banco de destino (PostgreSQL, BigQuery, Snowflake). Com mais de 13 mil stars no GitHub e integração com Apache DataFusion, representa a democratização dessas capacidades.
O Vanna AI usa RAG (Retrieval-Augmented Generation) para text-to-SQL: recupera esquemas, documentação e consultas de exemplo como contexto para o LLM. É mais simples de configurar que uma camada semântica completa, mas não oferece garantias semânticas, pois as definições são implícitas nos exemplos, não declaradas formalmente.
O que todas essas abordagens compartilham é o reconhecimento de que o LLM sozinho não é suficiente e precisa de uma camada de significado de negócio para gerar resultados confiáveis. A diferença entre elas está em onde essa camada vive (no data warehouse, como middleware, ou como serviço independente) e quão formalmente o modelo semântico é especificado.
Governança e auditabilidade: BCBS 239 e o elo com a camada semântica
Uma pergunta natural surge ao adotar essas ferramentas: quem garante que as definições no modelo semântico estão corretas? A resposta passa por governança, e a regulação financeira já oferece um framework para isso.
O Comitê de Basileia publicou em 2013 os princípios BCBS 239 para agregação de dados de risco e reporte, motivado pelas falhas da crise de 2008. O princípio 2 exige que cada elemento de dado tenha uma fonte autoritativa única. O princípio 3 exige agregação automatizada para minimizar erros, com reconciliação explícita entre dados de risco e contábeis. O princípio 6 exige capacidade de gerar dados de risco para requisições ad-hoc, exatamente o que NLQ sobre camada semântica entrega (BIS, 2013).
Mais de uma década depois, a adoção ainda é incipiente: apenas 2 dos 31 G-SIBs (Global Systemically Important Banks) avaliados estavam plenamente em compliance com todos os princípios. O BIS observou que bancos frequentemente mantinham “múltiplas fontes da camada ouro” para a mesma métrica, contradição que persiste (BIS, 2023).
A camada semântica oferece solução estrutural para essa lacuna. Quando métricas são definidas programaticamente, como código versionado, testado e aplicado em tempo de consulta, a definição é a computação. Não há descolamento entre glossário e cálculo real. E como toda consulta gerada por NLQ passa pelo modelo semântico, a linhagem de dados é nativa: de onde veio o número, qual fórmula, quais filtros, qual data de referência.
No Brasil, a Resolução CMN 4.557/2017 incorporou os princípios BCBS 239, exigindo gerenciamento integrado de riscos com definições consistentes. A Circular BACEN 3.678 estabelece divulgação padronizada de métricas de risco. Uma camada semântica que codifica essas definições regulatórias corresponde à compliance embarcada na infraestrutura de dados.
Padronização e futuro
A história das finanças é, em grande parte, uma história de padronização. O FIX Protocol (1992) padronizou ordens eletrônicas. O FpML (ISDA, 1999) padronizou derivativos de balcão. O XBRL (SEC, 2009; CVM, Brasil) padronizou demonstrações financeiras. Em cada caso, o padrão levou anos para ser definido e mais para ser adotado, mas reduziu drasticamente o custo de integração e os erros de interpretação.
A iniciativa Open Semantic Interchange (OSI), lançada em setembro de 2025 por uma coalizão que inclui Snowflake, BlackRock, dbt Labs, Salesforce, ThoughtSpot e mais de 20 organizações, segue essa mesma trajetória. A spec v1.0, publicada em janeiro de 2026 sob Apache 2.0, define um formato agnóstico de fornecedor para métricas, dimensões, relacionamentos e contexto semântico. O objetivo é definir uma métrica uma vez e consumi-la em qualquer ferramenta (SNOWFLAKE, 2025). A presença da BlackRock sinaliza que o setor financeiro reconhece a urgência.
A próxima fronteira é o que a Gartner denominou agentic analytics (GARTNER, 2026): agentes que não apenas consultam, mas monitoram, alertam e recomendam ações com base em métricas governadas. Em vez de o gestor perguntar “Quais fundos estão acima de 90% do limite?”, um agente monitora continuamente e emite alertas proativos, com a confiabilidade da camada semântica garantindo que o cálculo está correto. A Gartner estima que 57% dos times de finanças já estão implementando ou planejando agentic AI (GARTNER, 2025).
Limitações e riscos
A consistência que as camadas semânticas proporcionam vem acompanhada de desafios próprios que merecem atenção.
O viés de cobertura é o mais significativo: o sistema só responde sobre o que está modelado. Se uma métrica não foi definida, a pergunta não funciona ou é respondida de forma incompleta. O usuário pode concluir que “se respondeu, está certo”, quando o modelo cobria apenas parte do necessário.
O custo de manutenção é significativo. Esquemas legados de instituições financeiras são massivos, com centenas de tabelas que evoluíram ao longo de décadas. Modelar esse patrimônio é projeto de meses ou anos, e o modelo precisa ser mantido continuamente com novos produtos, métricas regulatórias e mudanças contábeis.
Os LLMs, mesmo restritos, ainda podem gerar SQL sintaticamente correto mas semanticamente errado nas faixas de alta complexidade. O benchmark da AtScale mostra 70% no nível máximo, melhora expressiva sobre 0%, mas longe da infalibilidade. A revisão humana continua necessária para decisões de alta consequência.
E há o risco organizacional: se o modelo semântico é mantido por uma equipe técnica sem validação das áreas de negócio, as definições podem não refletir o entendimento correto. A camada semântica transfere o problema de inconsistência distribuída para governança centralizada, mas não elimina a necessidade de julgamento humano sobre o que cada métrica deve significar.
Implicações para o profissional de finanças
A convergência entre camadas semânticas e LLMs muda o contrato entre o dado e seu consumidor. Em vez de “pergunte ao analista de dados e espere o relatório”, o contrato passa a ser “pergunte diretamente, em linguagem natural, e receba uma resposta auditável, com a mesma definição que qualquer outro consumidor receberia”. Trata-se de construir uma infraestrutura de confiança.
Na prática, gestores de risco ganham acesso a perguntas ad-hoc sobre VaR, exposição e limites sem depender de relatórios pré-construídos, com a garantia de que os números são consistentes com o que é reportado ao regulador. Controllers passam a reconciliar P&L entre tratamentos contábeis de forma transparente, com linhagem do dado. Compliance pode monitorar continuamente em vez de auditar periodicamente. E tesoureiros consultam posições e liquidez em tempo real com a mesma confiabilidade dos relatórios formais.
O valor concreto está na eliminação daquela reunião improdutiva da segunda-feira: quando todos os consumidores de dados obtêm o número a partir da mesma definição canônica, a discussão deixa de ser “qual número está certo” e passa a ser “o que fazemos a respeito”.
Referências
ATSCALE. Unveils Breakthrough in Natural Language Processing with Semantic Layer and Generative AI. AtScale Press Release, 2024.
BERNERS-LEE, Tim; HENDLER, James; LASSILA, Ora. The Semantic Web. Scientific American, v. 284, n. 5, p. 34-43, maio 2001.
BIS — BANK FOR INTERNATIONAL SETTLEMENTS. Principles for effective risk data aggregation and risk reporting (BCBS 239). Basileia: BIS, jan. 2013.
BIS — BANK FOR INTERNATIONAL SETTLEMENTS. Progress in adopting the Principles for effective risk data aggregation and risk reporting. Basileia: BIS, nov. 2023.
DAMA INTERNATIONAL. DAMA-DMBOK: Data Management Body of Knowledge. 2. ed. Denville: Technics Publications, 2017.
FLORATOU, Avrilia et al. Text-to-SQL Error Analysis and Taxonomy. Proceedings of the VLDB Endowment, v. 17, 2024.
GARTNER. Data Quality Market Survey. Stamford: Gartner, 2021.
GARTNER. Market Guide for Agentic Analytics. Stamford: Gartner, 2026.
GARTNER. Agentic AI Will Transform Finance: What CFOs Should Do Now. Stamford: Gartner, 2025.
KIMBALL, Ralph; ROSS, Margy. The Data Warehouse Toolkit: the definitive guide to dimensional modeling. 3. ed. Indianapolis: Wiley, 2013.
LI, Jinyang et al. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQL. In: NeurIPS 2023 Datasets and Benchmarks Track, 2023.
MILNER, Robin. A Theory of Type Polymorphism in Programming. Journal of Computer and System Sciences, v. 17, n. 3, p. 348-375, 1978.
SNOWFLAKE. Snowflake, Salesforce, dbt Labs, and More, Revolutionize Data Readiness for AI with Open Semantic Interchange Initiative. Press Release, set. 2025.
US SENATE PERMANENT SUBCOMMITTEE ON INVESTIGATIONS. JPMorgan Chase Whale Trades: A Case History of Derivatives Risks and Abuses. Washington: US Senate, mar. 2013.
YU, Tao et al. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. In: EMNLP 2018, p. 3911-3921, 2018.
ZHANG, Qianren et al. FinSQL: Model-Agnostic LLMs-based Text-to-SQL Framework for Financial Analysis. arXiv:2401.10506, 2024.