
Anatomia de uma camada semântica: do YAML à resposta auditável sobre dados da CVM
Como um arquivo de metadados em linguagem simples, combinado a um pipeline de múltiplos estágios, transforma perguntas em português em consultas SQL auditáveis sobre 24 datasets públicos.

Em um artigo anterior, Uma Métrica, Uma Verdade, argumentei que a convergência entre camadas semânticas e modelos de linguagem finalmente oferece uma saída para o caos de métricas que há décadas assombra áreas de finanças, risco e controladoria. O argumento ficou em nível conceitual: o que é uma camada semântica, por que ela importa, onde o mercado está caminhando. Faltava mostrar o equipamento por dentro, com exemplos.
Tomo como estudo de caso o pq_semantic_cvm (se quiser mais detalhes sobre o projeto, entre em contato no chat), projeto em que modelei quase a totalidade dos 24 datasets públicos da CVM (cadastros de fundos, DFPs e ITRs de companhias abertas, composição de carteiras, ofertas, securitizações, formulário de referência, processos sancionadores) em uma camada semântica baseada em YAML conectada a um data warehouse PostgreSQL e a um pipeline de geração de SQL em múltiplos estágios. A ideia é mostrar como as peças se encaixam, que tipo de conhecimento a camada semântica carrega, e por que esse padrão serve a qualquer empresa que queira oferecer acesso confiável aos próprios dados via linguagem natural.
O que está dentro dos arquivos YAML
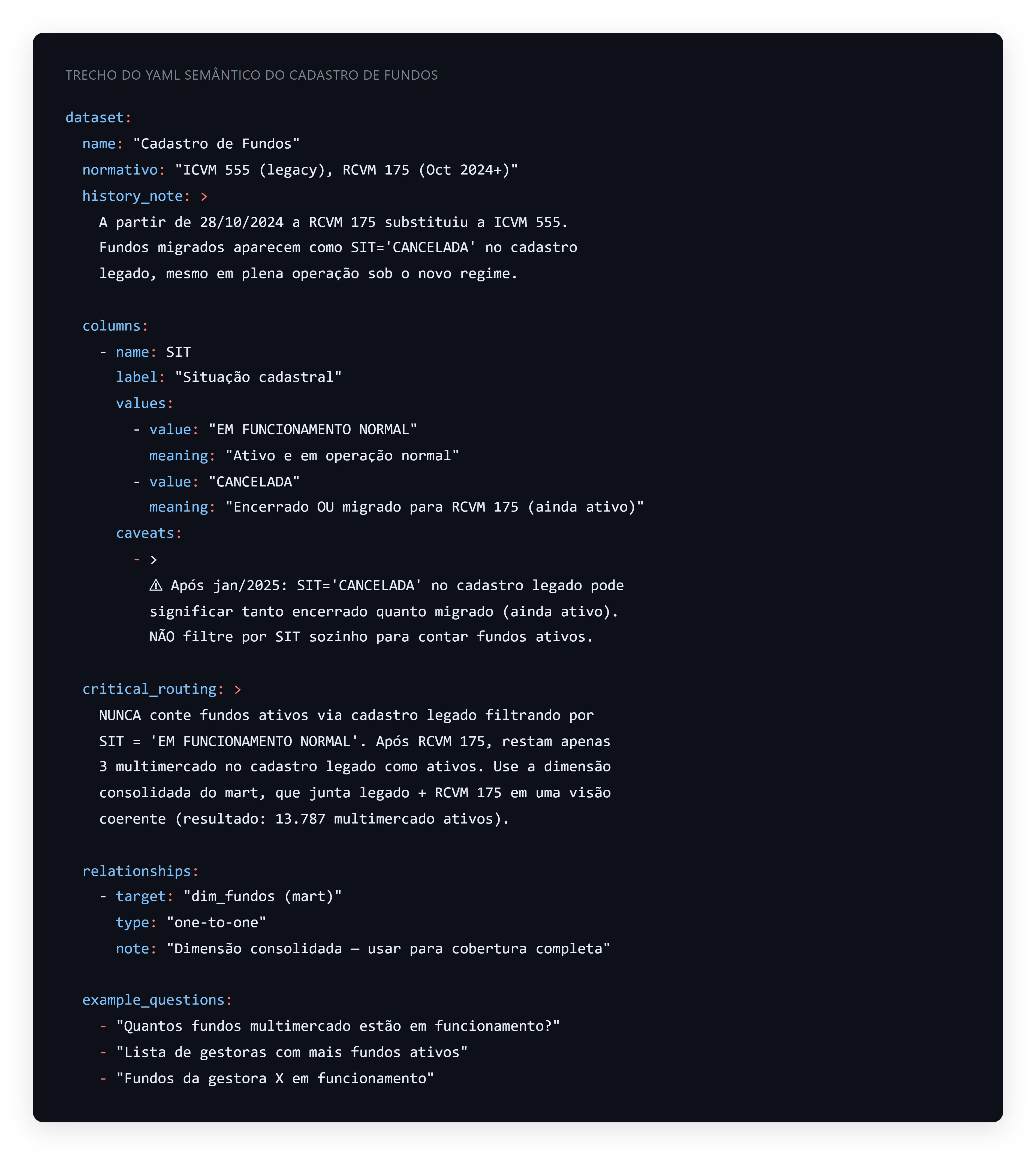
A camada semântica do projeto é uma coleção de arquivos YAML organizados por dataset. Cada YAML documenta uma tabela ou um grupo coeso de tabelas, e o conjunto cumpre três funções: descreve o que o dado significa, onde ele mora e quando ele mente. Não é documentação técnica no sentido tradicional, é um contrato de interpretação.
Um YAML típico começa com um bloco de cabeçalho que registra o normativo aplicável, a fonte bruta, a chave de grão e uma history note que descreve mudanças regulatórias relevantes. Em seguida vêm as colunas, cada uma com rótulo legível, descrição, contexto de negócio, valores possíveis e, a parte mais valiosa, caveats: armadilhas conhecidas, assimetrias, pegadinhas que só quem já quebrou a cabeça contra aquele dado sabe. O YAML do cadastro de fundos, por exemplo, avisa ao modelo que o campo SIT = 'CANCELADA' pós-RCVM 175 pode significar tanto encerrado quanto migrado para o novo regime e ainda ativo.
Além das colunas, os YAMLs declaram relationships (caminhos de junção pré-validados entre tabelas), critical_routing (regras peremptórias sobre qual tabela usar ou não usar para um tipo de pergunta), example_questions (perguntas reais com dicas de padrão SQL correto) e dimensional_traps (pares de conceitos que parecem sinônimos e não são, como administrador versus gestor de fundo, ou coordenador líder versus agente fiduciário em securitizações).
Há ainda um conjunto de arquivos auxiliares que descrevem regras transversais ao domínio: um registra idiomas de PostgreSQL que devem ser seguidos; outro consolida marcas canônicas (Bradesco casa como BRADESCO%, não como BANCO BRADESCO S.A.); um terceiro lista as confusões dimensionais recorrentes; um quarto define o que o crítico automático deve checar depois da execução.
Três camadas de tabelas, não uma
A camada semântica só faz sentido se estiver ancorada em um modelo dimensional bem estruturado. O projeto organiza o banco em três camadas clássicas de data warehouse na tradição de Kimball (KIMBALL; ROSS, 2013), cada uma com papel próprio.
A camada raw contém cópias fiéis dos arquivos publicados pela CVM: informes diários de fundos, balanços patrimoniais, formulários de referência, cadastros de participantes. Nada é normalizado, nada é deduplicado. Os tipos são preservados como texto (todo campo em CSV chega como texto), os nomes das colunas são idênticos aos do arquivo original, e cada dataset mora em sua própria tabela. Essa camada é a fonte da verdade: se houver discrepância, é ela que vale.
A camada staging é a primeira limpeza. Aqui os tipos são convertidos, valores nulos são padronizados, CNPJs são normalizados com LPAD para 14 dígitos, e, mais importante, tabelas equivalentes oriundas de regimes regulatórios diferentes são fundidas em visões coerentes. O stg_cvm__fundos é o exemplo canônico: ele faz UNION ALL entre raw.cad_fi (cadastro legado ICVM 555) e raw.registro_classe (RCVM 175), marcando a origem de cada linha para que a próxima camada possa escolher qual prevalecer quando houver duplicata.
A camada mart contém as tabelas prontas para análise. Suas tabelas têm prefixo dim_ (dimensões cadastrais, como dim_fundos), fct_ (tabelas-fato, como fct_fundos_performance_mensal ou fct_liquidez_trimestral) e sem_ (visões semânticas agregadas, como sem_composicao_carteira_gestora). É essa a camada que o pipeline de linguagem natural procura primeiro, tanto pela ergonomia quanto porque ela já absorveu as descontinuidades regulatórias que o raw expõe cru.

A camada semântica espelha essa estrutura: há um conjunto de YAMLs descrevendo as tabelas raw mais importantes (cadastros, informes, formulários), um conjunto separado descrevendo os marts (incluindo os staging selecionados que o modelo precisa conhecer) e os arquivos transversais já mencionados. Quando o pipeline monta um prompt, ele carrega apenas os YAMLs relevantes para a pergunta, filtrando por prefixo de tabela e por dataset envolvido.
O fluxo pergunta → resposta
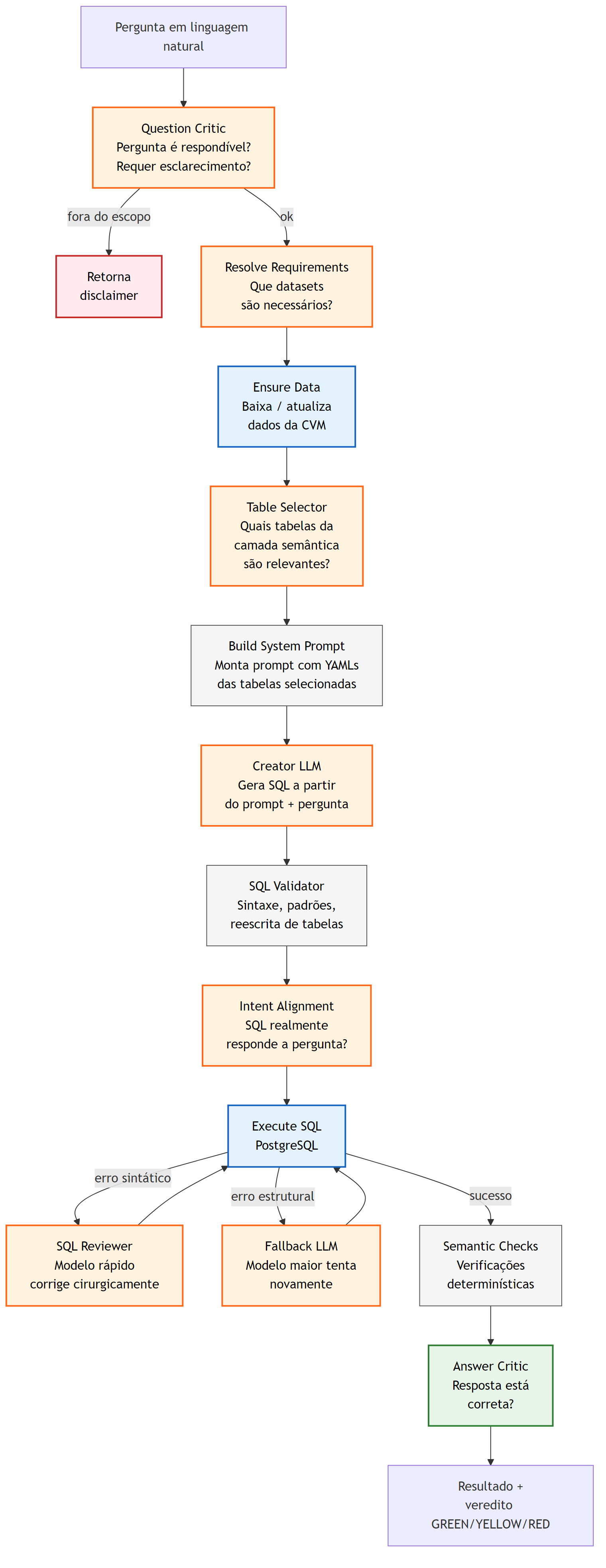
A camada semântica é conhecimento em repouso. O pipeline de linguagem natural é o que coloca esse conhecimento em uso. Ele recebe uma pergunta em português, consulta a camada semântica conforme o contexto, gera SQL, executa contra o PostgreSQL e devolve os dados junto com um veredito automático sobre a adequação da resposta.
A implementação usada tem dez estágios encadeados, desenhados para empilhar defesas em profundidade. Não é a única maneira de montar um sistema assim: frameworks como Vanna AI, Wren AI, Cube e dbt Semantic Layer seguem caminhos diferentes, ora mais próximos de RAG puro, ora mais próximos de compiladores de metrics (CHI, 2024; CANNER INC., 2024). A literatura acadêmica também documenta famílias distintas: decomposição com autocorreção (POURREZA; RAFIEI, 2023), decoding com gramática restrita (SCHOLAK; SCHUCHER; BAHDANAU, 2021), fine-tuning específico sobre corpora de SQL (LI et al., 2024; SUN et al., 2023), mistura de few-shot e recuperação (LIU et al., 2024). Cada escolha tem consequências em latência, custo de tokens e tipos de erro residual. O arranjo abaixo é o que, em experimentação sobre o domínio da CVM, deu melhor relação entre acurácia e tempo de resposta; ele deve ser visto como um ponto no espaço de projeto, não como receita universal.
Question Critic, Resolve Requirements e Ensure Data
A primeira etapa, Question Critic, decide se a pergunta é respondível com dados da CVM e se está dimensionalmente clara. Perguntas fora do escopo retornam um disclaimer em vez de um SQL, o que evita que o modelo alucine SQL para assuntos impossíveis. Perguntas ambíguas passam por uma clarificação automática que, quando o domínio permite, reescreve a pergunta de forma canônica (por exemplo, substitui “fundos da XP” por “fundos sob gestão da XP”, ou registra que “lucro” nessa pergunta provavelmente significa lucro líquido societário).
Em seguida, Resolve Requirements consulta a camada semântica e devolve a lista de datasets necessários com seus recortes temporais, por exemplo dfp:2024,2023; cia_aberta_cad:snapshot para uma pergunta sobre evolução de lucro de uma companhia aberta. Esse resultado alimenta o estágio Ensure Data, responsável por baixar ou atualizar na camada raw apenas os arquivos necessários. Se o dataset já estiver em cache, o estágio passa em um milissegundo.
Table Selector e System Prompt
O Table Selector é um segundo estágio de LLM cuja única função é escolher, dentre todas as tabelas candidatas, o subconjunto mais provável para responder à pergunta. Ele recebe descrições sucintas de cada tabela (extraídas dos YAMLs) e devolve uma lista curta, tipicamente de duas a cinco tabelas. Esse filtro reduz drasticamente o tamanho do prompt principal.
Com as tabelas escolhidas, Build System Prompt monta o contexto que vai alimentar o gerador de SQL: regras de PostgreSQL, YAMLs das tabelas selecionadas (com colunas, caveats, critical_routing e example_questions), marcas canônicas relevantes, armadilhas dimensionais pertinentes ao domínio e uma amostra de valores enumerados para colunas categóricas. O prompt fica tipicamente entre 30 e 50 mil tokens, contra centenas de milhares se todos os YAMLs fossem carregados.
Creator LLM, SQL Validator e Intent Alignment
O Creator LLM é o gerador propriamente dito. Ele recebe o prompt e a pergunta, e devolve SQL em saída estruturada (JSON com um único campo sql), o que elimina toda uma classe de erros de parsing associados a respostas em markdown livre (GENG et al., 2025). A escolha do modelo responsável por esse estágio é uma decisão de custo-benefício: modelos maiores tendem a acertar mais em perguntas complexas, mas custam mais e são mais lentos. A configuração usada aqui combina um modelo principal de nível intermediário com dois níveis de fallback mais capazes, acionados apenas se o anterior falhar. Os marcadores específicos importam menos do que a forma da cascata.
O SQL Validator roda checagens determinísticas sobre o SQL gerado: sintaxe, bloqueio de operações perigosas, reescrita de tabelas alucinadas (se o modelo inventou staging.stg_cvm__fundos quando o Table Selector só havia autorizado marts.dim_fundos, a substituição é automática e registrada). É barato e rápido, e pega erros cirúrgicos antes de encostarem no banco.
O Intent Alignment é uma segunda passagem de LLM, barata, que pergunta: “esse SQL, se executado, responde à pergunta original?”. Quando a resposta é não, o SQL é regenerado com feedback específico sobre o que está faltando. Esse estágio captura a diferença entre right data, wrong dimension: SQL que compila, executa e retorna números plausíveis, mas responde a uma pergunta diferente da que foi feita.
Execute, recuperação e Answer Critic
Se tudo passa, o SQL vai para Execute. Quando o banco devolve erro, entra uma cadeia de recuperação: primeiro o SQL Reviewer (modelo pequeno, correção cirúrgica, latência abaixo de um segundo); depois o Fallback LLM (modelo maior, recebe o SQL errado junto com o erro e regenera); por fim, o Fallback LLM 2 (modelo ainda mais capaz, recebe as duas tentativas anteriores e seus respectivos erros). Cada nível só é acionado se o anterior falhar, e a cascata abre mão de tentativas quando os erros sugerem problema estrutural insolúvel.
Quando a execução produz linhas, o Semantic Checks roda verificações determinísticas simples: por exemplo, se a pergunta pedia um ranking de cinco itens e o resultado tem apenas um, ou se todos os valores voltaram NULL. Em seguida, o Answer Critic (outra chamada de LLM, com modelo diferente do gerador para reduzir viés correlacionado) lê a pergunta, o SQL e as primeiras linhas do resultado, e emite um veredito em três níveis: GREEN (resposta adequada), YELLOW (resposta provavelmente correta com ressalvas) ou RED (resposta inadequada, seja por SQL incorreto, seja por interpretação equivocada da pergunta). O veredito é exibido junto do resultado; o usuário vê não apenas o número, mas uma segunda opinião automatizada sobre se aquele número responde ao que foi perguntado.
O paradigma de usar um modelo como juiz de outro foi popularizado por Zheng et al. (2023) com o MT-Bench, e a ideia de autoconsistência por múltiplas amostragens, por Wang et al. (2023). Aqui não há amostragem múltipla: há um juiz único com acesso ao resultado, que é mais barato e, para o domínio, tem se mostrado adequado.
Um exemplo executado
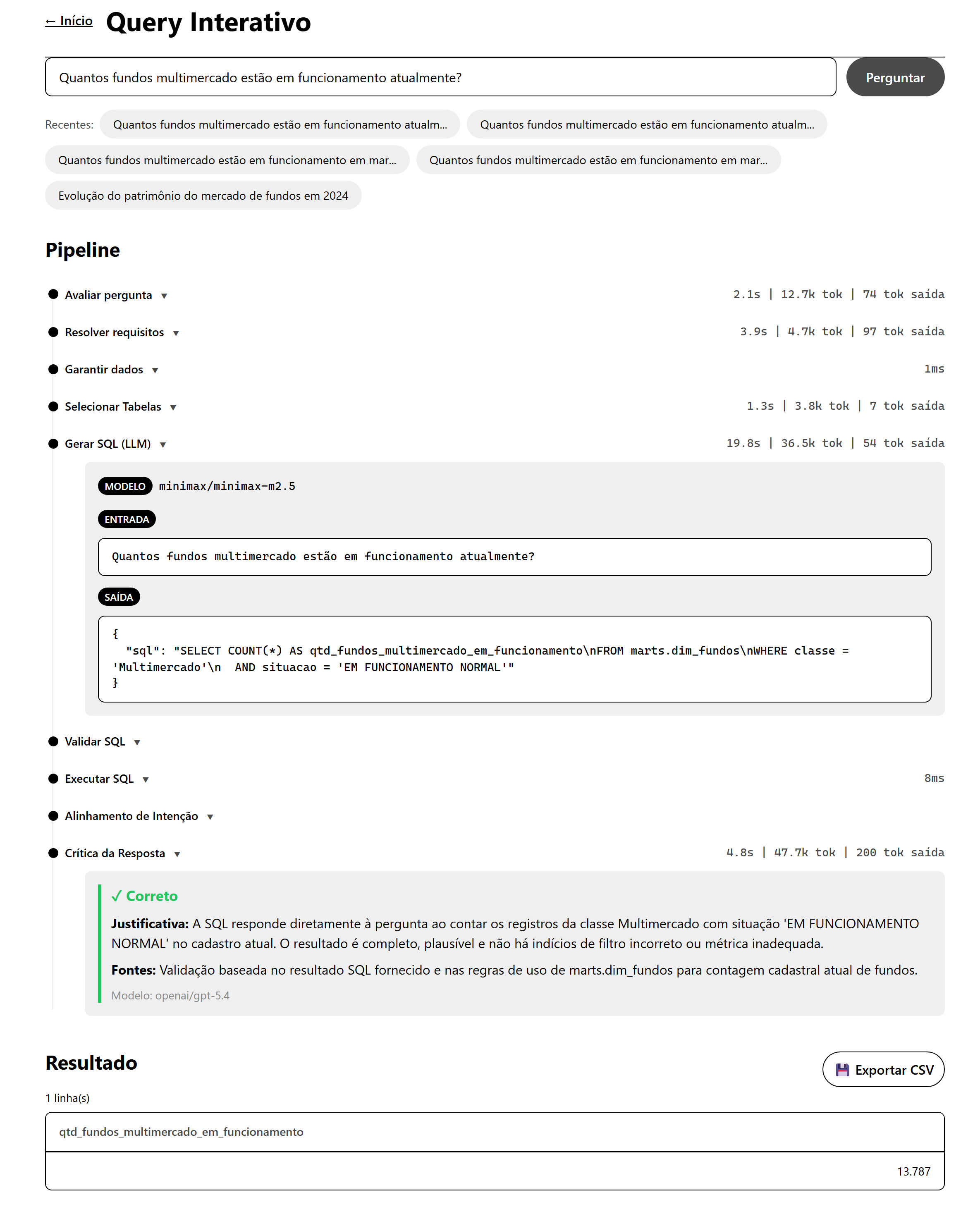
A descrição acima fica mais palpável quando se acompanha a execução. Abaixo está o fluxo completo para uma pergunta simples, registrada pela interface do projeto:
Dois elementos merecem atenção. O SQL gerado aponta para marts.dim_fundos e não para raw.cad_fi. Essa escolha é consequência do critical_routing documentado no YAML do cadastro, que instrui o LLM a nunca contar fundos ativos diretamente em cad_fi após a RCVM 175. Sem essa instrução, o mesmo modelo escreveria, com a mesma confiança, um SQL contra cad_fi e devolveria três fundos multimercado, não 13.787, como o próximo exemplo mostra.
O segundo elemento é o veredito. O Answer Critic não apenas valida: ele explicita a justificativa (”a SQL usa a dimensão cadastral adequada, filtra a classe certa e restringe aos fundos em funcionamento”) e aponta as fontes consultadas. É essa explicitação que transforma “número de um LLM” em “resposta com cadeia de custódia visível”.
As vantagens claras da camada semântica: dois exemplos reais
Os dois casos a seguir foram executados contra a base de produção, em PostgreSQL 17, com dados públicos da CVM. Não são cenários didáticos: são o tipo de falha silenciosa que a ausência de uma camada semântica produz no dia a dia de uma mesa de dados.
Exemplo 1: o colapso silencioso pós-RCVM 175
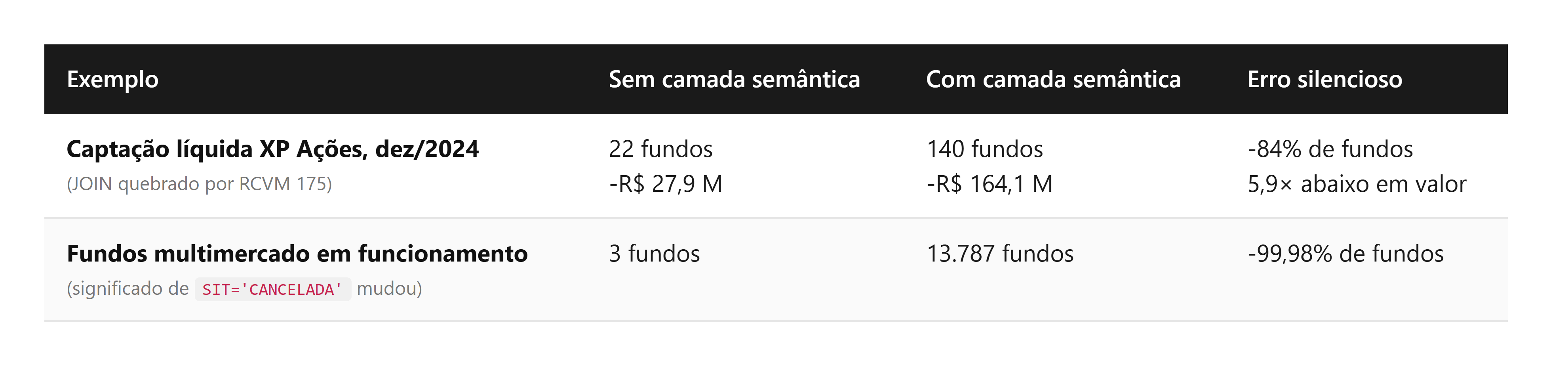
Em 28 de outubro de 2024, a RCVM 175 substituiu a ICVM 555 na regulação de fundos. A mudança foi a migração de identificador: o informe diário passou a usar CNPJ da classe do fundo em vez do CNPJ do fundo. Em novembro de 2024, 22.895 de 25.866 CNPJs ativos (88,6%) já eram CNPJs de classe, invisíveis para qualquer consulta que fizesse JOIN raw.inf_diario → raw.cad_fi, o padrão legado.
A pergunta “Qual foi a captação líquida dos fundos de ações da XP em 2024, mês a mês?” gerada por um modelo sem acesso à camada semântica produz um SQL sintaticamente perfeito, que roda sem erro e devolve uma tabela coerente. O problema é que a contagem de fundos cai de 69 em janeiro para 22 em dezembro, o valor de captação fica 5,9× menor que o real em dezembro, e o analista tende a interpretar o declínio como decisão de negócio da XP quando, na verdade, é artefato da migração regulatória que fez 82% dos fundos sumirem do JOIN.
Com a camada semântica, o mesmo LLM passa a receber, junto da pergunta, a instrução de que dim_fundos consolida cadastros do regime legado e do novo, e que a tabela-fato fct_fundos_performance_mensal já absorve essa migração. O SQL gerado então faz JOIN contra as tabelas certas. Em dezembro, o resultado passa a mostrar 140 fundos e captação líquida de -R$ 164,1 milhões, refletindo a realidade.
Exemplo 2: quando o significado da coluna muda
A segunda armadilha é ainda mais sutil. A mesma RCVM 175 fragmentou o cadastro de fundos: os fundos migrados aparecem como SIT = 'CANCELADA' no cadastro legado raw.cad_fi, mesmo em plena operação. O campo SIT não mudou de nome. Os valores possíveis não mudaram. Mas o significado de 'CANCELADA' expandiu: agora pode ser encerrado ou migrado e ativo sob RCVM 175.
Uma pergunta comum, “Quantos fundos multimercado estão em funcionamento no Brasil em março de 2025?”, gera sem camada semântica o SQL óbvio: SELECT COUNT(*) FROM raw.cad_fi WHERE classe = 'Multimercado' AND sit = 'EM FUNCIONAMENTO NORMAL'. O resultado é 3. Apenas três fundos multimercado em funcionamento no Brasil. Sem erro, sem aviso: a consulta é sintaticamente perfeita.
Com a camada semântica, o critical_routing no YAML do cadastro proíbe esse padrão: “NUNCA conte fundos ativos usando raw.cad_fi WHERE SIT = 'EM FUNCIONAMENTO NORMAL'. Use marts.dim_fundos.situacao, que consolida cad_fi e registro_classe em uma dimensão coerente”. O SQL gerado passa a contar pelo mart e retorna 13.787, cerca de 4.600 vezes mais fundos do que o primeiro caminho.
Os dois erros têm escalas diferentes mas a mesma natureza: uma consulta hardcoded é um contrato com o esquema físico de ontem; toda vez que a CVM publica uma nova instrução normativa (e foram muitas, de ICVM 302 a RCVM 175), o contrato quebra. Uma camada semântica é um contrato com o significado do dado. A regulação muda uma vez; o YAML é atualizado uma vez; dessa forma as consultas geradas automaticamente passam a refletir a nova realidade.
Que tipo de pergunta esse sistema responde
A camada semântica modelada cobre oito grandes domínios, e o pipeline tem histórico de respostas validadas como corretas em todos eles. Para dar a medida do escopo, seguem exemplos reais abaixo que tal sistema é capaz de responder utilizando somente dados da CVM.
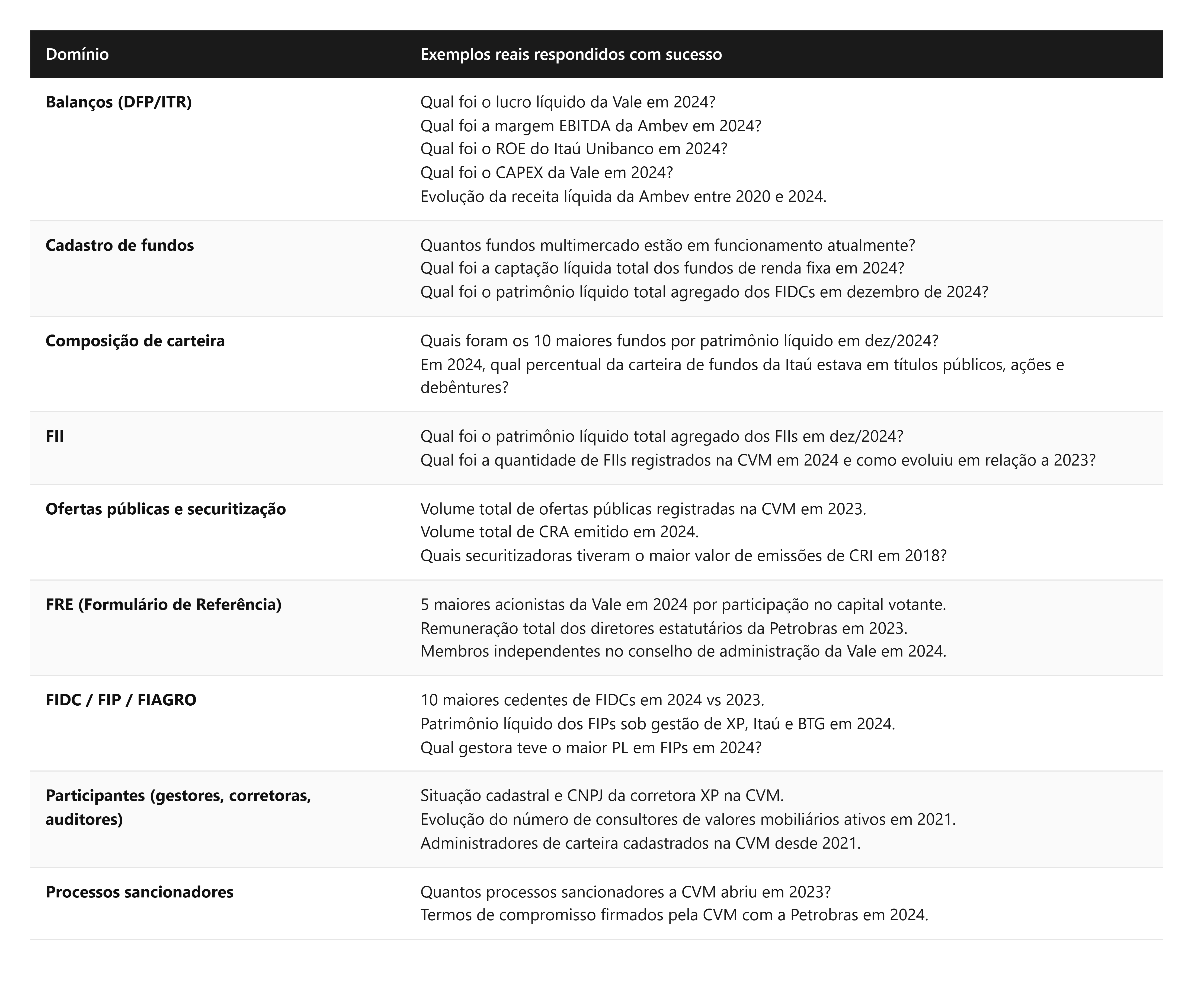
A amplitude decorre de que cada domínio exigiu construção de YAMLs específicos, com seus próprios caveats, critical_routing e dimensional_traps. Perguntas sobre composição de carteira, por exemplo, só funcionam bem porque o mart sem_composicao_carteira_gestora pré-agrega 1,47 milhão de linhas do informe CDA por gestor e tipo de ativo, e porque o YAML correspondente deixa claro que essa tabela existe, que granularidade por fundo deve cair no staging, e que a coluna gestor se refere à gestora do fundo, não ao emissor do título.
Mas qual seria a diferença de tentar responder usando um chat LLM “inteligente” com capacidade de busca, considerando que os dados da CVM são públicos? Mesmo que os dados sejam públicos, o chat LLM não executa consulta analítica sobre eles: na melhor hipótese ele lê páginas descritivas do portal da CVM, ou tenta montar um script ad hoc a cada pergunta, sem garantia de que baixou os arquivos certos, fez o join certo e agregou corretamente. Mesmo que o chat consiga rodar o SQL, ele não carrega o conhecimento acumulado sobre as armadilhas do domínio que citamos. A camada semântica é esse conhecimento destilado, pronto para ser injetado em qualquer modelo que gere SQL. Além disso, o custo da consulta e o tempo de execução serão significativamente menores com o uso da camada semântica.
Quando a mesma arquitetura vai para dentro de uma empresa
A CVM é um laboratório conveniente: dados públicos, descontinuidades regulatórias bem documentadas, zero preocupação com autorização por linha ou com LGPD. Dentro de uma empresa, a mesma arquitetura precisa absorver três atritos adicionais.
O primeiro é o conhecimento tribal. No caso da CVM, todo caveat que entra no YAML pode ser justificado por uma instrução normativa que qualquer um consegue ler. Dentro da empresa, os caveats moram na cabeça da pessoa que há oito anos sabe que o campo status_venda = 7 significa “cancelado pelo cliente, mas com multa paga” e não “cancelado pelo backoffice”. Modelar bem a camada semântica exige sentar com essas pessoas, transcrever o que elas sabem e versionar. É um trabalho arqueológico antes de virar trabalho de engenharia, mas que pode ser auxiliado também com o uso de LLMs.
O segundo é o controle de acesso. A mesma pergunta (”margem de contribuição por SKU no trimestre”) pode ser legítima para o diretor comercial e proibida para um estagiário do financeiro. A camada semântica precisa casar com row-level security, views filtradas por perfil e trilhas de auditoria que a CVM, por natureza pública, dispensa. Isso transforma a camada semântica em um artefato de governança, não apenas de modelagem.
O terceiro é a velocidade do esquema. A CVM muda regras a cada alguns anos; times de produto mudam o esquema de dados a cada sprint. O YAML passa a ser um contrato que precisa ser atualizado junto do pull request que renomeia uma coluna, sob pena de o crítico começar a reprovar respostas de um dia para o outro.
Quando esses três atritos são endereçados, o que sobra é um padrão com conexão natural aos princípios de agregação e reporte de dados de risco do BCBS 239 (BCBS, 2013) e da Resolução CMN 4.557/2017 (BCB, 2017): fonte autoritativa única, definição consistente, capacidade de responder rapidamente a solicitações não padronizadas. O YAML documentado, versionado e conectado a um mart torna a auditoria mais barata, e o crítico automático fornece uma segunda leitura que o reporte manual não tem.
Os contratempos
A arquitetura não é livre de problemas, e os mais persistentes vêm do próprio LLM. Três merecem destaque.
O primeiro é o não-determinismo. Mesmo com temperatura zero e resposta estruturada, a mesma pergunta pode produzir SQLs diferentes em execuções distintas, por razões que remontam à não-associatividade de ponto flutuante em GPU e à dependência do resultado com o tamanho do batch de inferência (ATIL et al., 2024; HE, 2025). A mesma pergunta que recebeu GREEN em uma execução pode receber RED em outra, com SQLs sutilmente diferentes. No exemplo 2 acima, durante a gravação deste artigo, a mesma pergunta foi executada duas vezes em menos de uma hora: uma vez gerou COUNT(*) com filtro de data e o crítico aprovou; outra vez gerou COUNT(DISTINCT cnpj) sem filtro de data e o crítico reprovou por não respeitar o recorte temporal pedido. A saída foi próxima, mas a cadeia de raciocínio divergiu.
O segundo é a alucinação residual. LLMs ainda inventam colunas, tabelas, funções de janela e sintaxes que não existem no PostgreSQL, e o fazem com fluência suficiente para passarem por válidas em uma leitura rápida (JI et al., 2023; HUANG et al., 2023). O SQL Validator elimina uma fração, o Intent Alignment outra, o crítico pega o que sobra, mas nenhum desses mecanismos elimina o problema por completo. Mesmo no benchmark BIRD, que usa bancos reais e sujos, os melhores modelos proprietários chegam perto de 55% de acurácia contra 93% humana (LI et al., 2023); em benchmarks enterprise recentes como Spider 2.0, a taxa cai para algo em torno de 20% (LEI et al., 2024). A camada semântica eleva o piso, não o teto.
O terceiro é o custo de modelagem. A camada semântica não é automática: ela exige conhecimento de domínio que alguém precisa destilar em YAMLs. Cada caveat só chega ao arquivo depois que alguém quebrou a cabeça contra aquele dado e entendeu a armadilha. Para uma empresa com centenas de tabelas herdadas, a modelagem inicial pode levar meses, e a manutenção é contínua: toda mudança de schema, toda nova fonte, toda renomeação exige atualização correspondente no YAML. É o custo de transformar conhecimento tribal em infraestrutura.
Existe ainda o viés de cobertura: o sistema só responde bem ao que foi modelado. Perguntas que caem fora dos domínios mapeados tendem a receber respostas genéricas ou a serem rejeitadas pelo Question Critic. Isso é uma qualidade, não defeito (rejeitar é muito melhor que responder mal), mas a fronteira entre domínio coberto e domínio descoberto precisa ser visível ao usuário.
Conclusão
O investimento em uma camada semântica paga-se em três moedas diferentes.
A primeira é tempo, pois as perguntas que antes entravam numa fila de BI e voltavam dois dias depois voltam em segundos, com a resposta estruturada e pronta para discussão. Um diretor que pergunta e já recebe a contagem correta de fundos, a evolução da margem, o ranking do trimestre, deixa de esperar pelo analista e pede diretamente. O analista, por sua vez, sai de operador de consulta e volta a ser investigador de padrões.
A segunda é confiança, pois quando duas áreas discordam sobre um número, a discussão hoje costuma ser sobre qual definição foi usada. Com uma camada semântica bem modelada, a definição está escrita em um lugar só, é versionada, é auditável e acompanha cada resposta gerada. O tempo de reunião antes gasto em “qual planilha é a certa” migra para o que realmente importa: o que fazer com o que o número mostra.
A terceira é resiliência, pois quando a regulação muda, sistemas fonte são renomeados, produtos ganham novos campos. Sem camada semântica, cada mudança dispara uma caçada manual por consultas quebradas em planilhas, dashboards e relatórios. Com ela, a mudança é registrada uma vez, no YAML, e todas as perguntas futuras passam a refletir a nova realidade. O conhecimento institucional deixa de morrer quando o analista sênior sai.
Nenhum desses ganhos depende de acreditar que os modelos de linguagem já são confiáveis o bastante para serem soltos sozinhos, e é exatamente aí que a abordagem se torna atrativa: ela coleciona o conhecimento da casa em um artefato estável, e usa o LLM apenas como tradutor supervisionado. Quando o modelo seguinte chegar e for ainda mais confiável, a camada semântica está pronta para receber; quando chegar e alucinar de forma nova, as verificações já existirão.
A pergunta a fazer antes de começar não é se vale montar a infraestrutura, é quanto tempo mais a empresa pode continuar pagando o custo invisível de operar sem ela: divergência de número, analista caro resolvendo ad hoc, diretor que decide no escuro, auditoria que demora semanas. Quando esse custo é medido com honestidade, o investimento na camada semântica pode se tornar intessante.
Referências
ATIL, B. et al. Non-Determinism of ‘Deterministic’ LLM Settings. arXiv preprint, arXiv:2408.04667, 2024. Disponível em: https://arxiv.org/abs/2408.04667.
BASEL COMMITTEE ON BANKING SUPERVISION. Principles for effective risk data aggregation and risk reporting. Basel: Bank for International Settlements, jan. 2013. Disponível em: https://www.bis.org/publ/bcbs239.pdf.
BANCO CENTRAL DO BRASIL. Resolução CMN nº 4.557, de 23 de fevereiro de 2017: dispõe sobre a estrutura de gerenciamento de riscos e gerenciamento de capital. Brasília: BCB, 2017.
CANNER INC. Wren AI — Modeling Definition Language (MDL). Documentação técnica. 2024. Disponível em: https://docs.getwren.ai/oss/engine/concept/what_is_mdl.
CHI, H. Why the Semantic Layer is Essential for Reliable Text-to-SQL. Wren AI Blog, 2024. Disponível em: https://www.getwren.ai/post/why-the-semantic-layer-is-essential-for-reliable-text-to-sql-and-how-wren-ai-brings-it-to-life.
GENG, S. et al. JSONSchemaBench: A Rigorous Benchmark of Structured Outputs for Language Models. arXiv preprint, arXiv:2501.10868, 2025.
HE, H. Defeating Nondeterminism in LLM Inference. Thinking Machines Lab Blog, 2025. Disponível em: https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/.
HUANG, L. et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Transactions on Information Systems, 2023. arXiv:2311.05232.
JI, Z. et al. Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, v. 55, artigo 248, 2023.
KIMBALL, R.; ROSS, M. The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling. 3. ed. Indianapolis: John Wiley & Sons, 2013.
LEI, F. et al. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows. International Conference on Learning Representations (ICLR), 2025. arXiv:2411.07763.
LI, H. et al. CodeS: Towards Building Open-source Language Models for Text-to-SQL. arXiv preprint, arXiv:2402.16347, 2024.
LI, J. et al. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs (BIRD). In: Advances in Neural Information Processing Systems (NeurIPS), 2023.
LIU, X. et al. A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going?. arXiv preprint, arXiv:2408.05109, 2024.
POURREZA, M.; RAFIEI, D. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction. In: Advances in Neural Information Processing Systems (NeurIPS), 2023.
SCHOLAK, T.; SCHUCHER, N.; BAHDANAU, D. PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), p. 9895-9901, 2021.
SUN, R. et al. SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL. arXiv preprint, arXiv:2306.00739, 2023.
WANG, X. et al. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In: International Conference on Learning Representations (ICLR), 2023.
ZHENG, L. et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. In: Advances in Neural Information Processing Systems (NeurIPS), 2023.