
Backtest overfitting: quando muitas tentativas fabricam desempenho
Bailey, Borwein, López de Prado e Zhu provaram em 2014 que o Sharpe ratio do vencedor entre N tentativas cresce com √(2 ln N). Uma década depois, eis o que mudou na caixa de ferramentas.

Em maio de 2014, a Notices of the American Mathematical Society publicou um artigo de quatro autores com um título incomum para uma revista de matemática pura. Bailey, Borwein, López de Prado e Zhu usaram a palavra fraude para descrever uma classe inteira de rotinas correntes na indústria de gestão sistemática (BAILEY et al., 2014). A tese, em uma frase, é que o gestor que apresenta um backtest sem informar quantas configurações de estratégia testou está, por construção, omitindo a evidência decisiva sobre a probabilidade de o resultado ser falso.
O paper repercutiu fora do circuito acadêmico. Foi noticiado em sites de divulgação científica, gerou cartas indignadas de hedge funds e provocou um debate sobre se a comparação dos autores com a publicação seletiva de ensaios clínicos era justa. A analogia central comparava a omissão do número de tentativas (N) à omissão de ensaios clínicos negativos pela indústria farmacêutica antes do movimento alltrials.net. O regulador de fármacos exige hoje a divulgação completa de todos os braços testados, ao passo que o regulador de fundos sistemáticos não exige nada equivalente.
Onze anos depois, o paper é citado regularmente como referência canônica do problema de backtest overfitting. Os mesmos autores publicaram extensões importantes que detalharam o ferramental para detecção e correção. Em paralelo, surgiu uma literatura empírica massiva sobre crise de replicação em factor investing que confirmou o diagnóstico de 2014 com dados. Este texto complementa o artigo anterior Prevenção de overfitting e data snooping em backtests, que tratou do protocolo walk-forward com purging, embargo e métricas deflacionadas. Aqui o foco recai sobre a mecânica estatística que torna esses cuidados necessários: a seleção do vencedor entre muitas tentativas já fabrica desempenho sob a hipótese nula.
O teorema central de Bailey, Borwein, López de Prado e Zhu
O ponto de partida é uma observação trivial sobre estatística de máximos. Se um pesquisador estima N Sharpe ratios independentes em uma série de retornos cuja média verdadeira é zero, e se o estimador de Sharpe ratio sob essa hipótese é aproximadamente normal com média zero e variância V conhecida, então o máximo dos N estimadores constitui o estimador extremo de uma família, com distribuição assintótica dada pelo teorema de Fisher-Tippett-Gnedenko: o máximo padronizado de variáveis normais converge para a distribuição de Gumbel. As mesmas distribuições estudadas na Teoria de Valores Extremos.
Nesse contexto, conta como tentativa toda especificação completa que teve chance de virar vencedora, mesmo as descartadas antes do relatório final: uma janela de média móvel, um par de limiares de z-score, um filtro de liquidez, um universo de ativos, uma regra de rebalanceamento, um horizonte de treino e teste ou uma variante de pré-processamento dos dados. No experimento idealizado de Bailey, Borwein, López de Prado e Zhu, a tentativa é uma coluna da matriz T × N de retornos. Na pesquisa real, é cada caminho avaliado antes de escolher o melhor. Se cem combinações de médias móveis foram testadas e noventa e nove foram descartadas, N começa em cem, não em um. Quando essas combinações são quase idênticas, o número efetivo de tentativas pode ser menor que o número bruto. Ainda assim, elas não desaparecem da inferência.
O Teorema 1 do paper original (Proposição 2.1 no texto formal) explicita a fórmula assintótica:
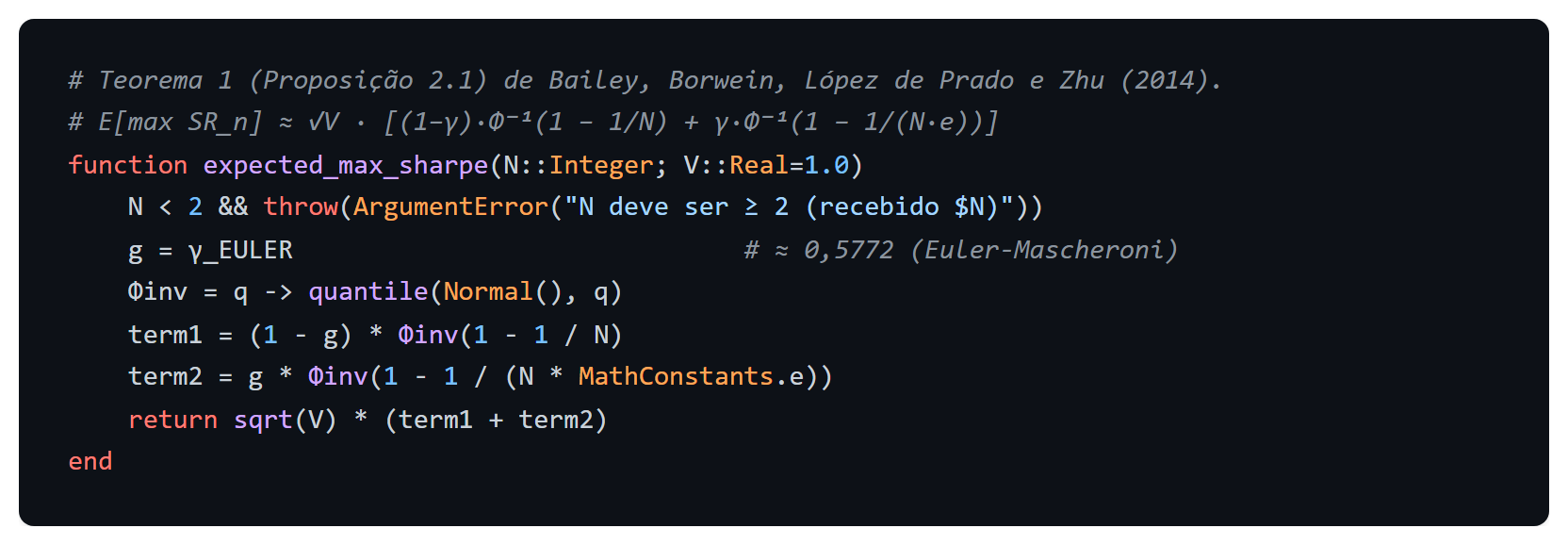
Aqui Φ⁻¹ é a quantil normal padrão e γ ≈ 0,5772 é a constante de Euler-Mascheroni. A cota superior simples e útil é E[max] ≲ √(2 ln N), que cresce devagar mas inexoravelmente. Em termos prosaicos, se você joga uma moeda muitas vezes, o maior número de caras consecutivas que aparece numa sequência cresce com √(log do número de jogadas). Em pesquisa quantitativa, a mesma mecânica aparece quando você testa 1.000 médias móveis sobre o mesmo histórico: o Sharpe ratio do melhor grid é, sob hipótese nula de zero alfa, da ordem de √(2 ln 1000) ≈ 3,7 vezes o desvio-padrão do estimador de Sharpe ratio.
Teorema 1 (BAILEY et al., 2014, paráfrase). Sejam N Sharpe ratios estimados de forma independente, cada um com média zero (hipótese nula de retorno esperado nulo) e variância V. Para N grande, o valor esperado do máximo dos N Sharpe ratios estimados é dado pela fórmula acima, com cota superior assintótica √(2 ln N) · √V. A independência é hipótese explícita. Correlações entre estratégias reduzem o número efetivo de tentativas (LÓPEZ DE PRADO; LEWIS, 2019), mas não eliminam o resultado.
O Sharpe ratio observado em um backtest não é, por si só, evidência da qualidade da estratégia. Ele só vira evidência quando confrontado com a distribuição do Sharpe ratio máximo de N tentativas independentes sob a hipótese nula. Sem o número de tentativas, qualquer Sharpe ratio é compatível com sorte, e a omissão de N torna o backtest um objeto vazio do ponto de vista estatístico.
Quanto de backtest é necessário
O Teorema 2 (Teorema 3.1 no texto formal) inverte a fórmula anterior. Se o pesquisador testa N configurações e quer que o Sharpe ratio esperado do “vencedor” seja menor que um alvo SR* (digamos, 1 anualizado, abaixo do qual ninguém confiaria a alocação), então a quantidade mínima de dados necessária satisfaz a desigualdade:
O acrônimo MinBTL vem de Minimum Backtest Length. Se um quant testou 100 estratégias e quer convencer o investidor de que um Sharpe ratio observado de 1 não é artefato, ele precisa de cerca de 6,4 anos de retornos. Para 1.000 estratégias, são 10,6 anos. Para 10.000 (típico de busca em grid de quatro hiperparâmetros), são quase 15 anos. A primeira tabela do artigo mostra valores numéricos exatos calculados pelo pacote de apoio.
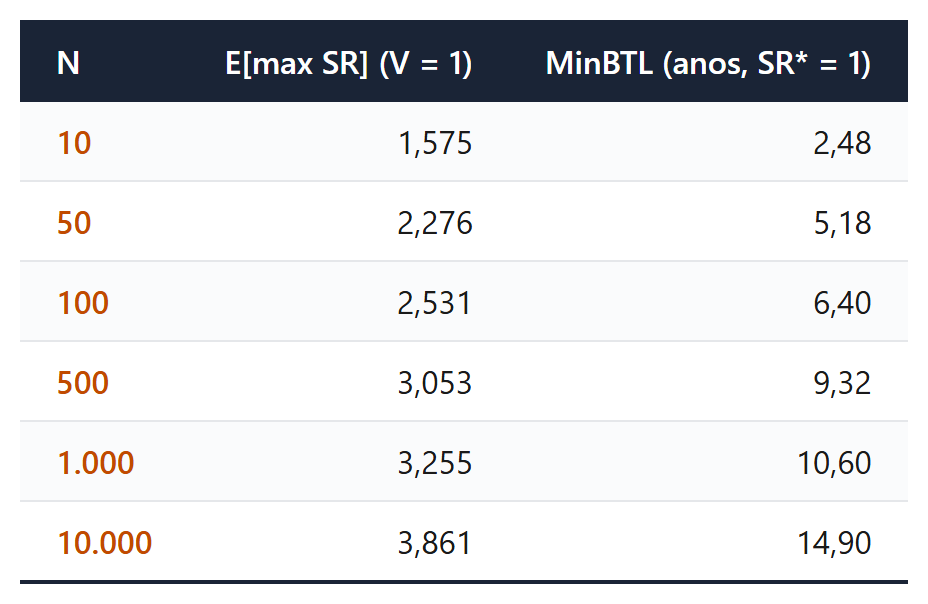
Quase nenhum estudo de fundo sistemático brasileiro tem 10 anos de série diária em ativos comparáveis. Quase todo grid de pesquisa de estratégia toca a casa das centenas ou milhares de configurações testadas, somando otimizações de janela, parâmetros de filtro e cortes temporais. A combinação dos dois prazos diz que a pesquisa empírica padrão da indústria, sob a ótica do Teorema 2, está sistematicamente sub-amostrada.
O paper de 2014 propõe que journals e prospectos tratem a omissão de N como informação material faltante, comparável à omissão de braços negativos em ensaios clínicos. A SEC Marketing Rule (IA-5653, vigente desde 2022) exige divulgação de “criteria and assumptions” para resultados hipotéticos, mas não obriga divulgar o número de tentativas. O GIPS Handbook 2020 do CFA Institute classifica desempenho retroprojetado como informação suplementar e impede que entre em compósitos, mas não impõe exigência quantitativa sobre N. A recomendação do paper original ainda não virou regra.
PSR e DSR, ou como descontar o Sharpe pela seleção
O Teorema 1 informa o pesquisador, mas não dá ao investidor uma estatística diretamente comparável entre estratégias. Os mesmos autores fecharam essa lacuna com duas extensões nos anos seguintes.
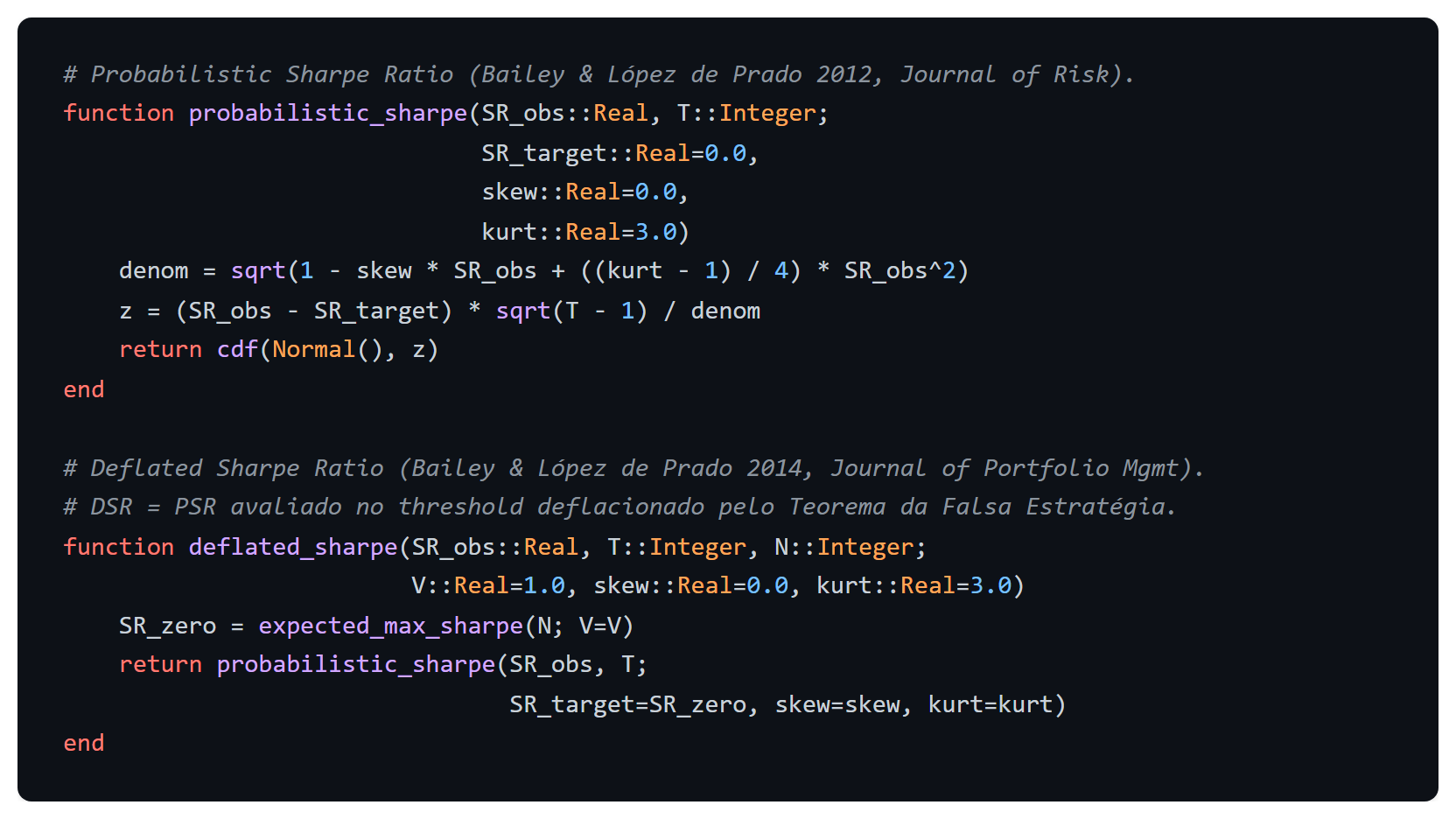
O Probabilistic Sharpe Ratio traduz o Sharpe ratio observado em probabilidade de que o Sharpe ratio verdadeiro exceda um alvo dado, ajustando explicitamente para skewness γ₃ e kurtosis γ₄ da série (BAILEY; LÓPEZ DE PRADO, 2012):
O PSR generaliza o resultado sobre erro-padrão do Sharpe ratio para retornos não-normais (LO, 2002). Skewness negativa (perdas extremas mais frequentes que ganhos) e kurtosis alta (caudas pesadas) inflam o denominador, reduzindo o PSR. Uma estratégia com Sharpe ratio anualizado de 1 e cauda pesada pode ter PSR(0) inferior a 80%, enquanto outra com mesmo Sharpe ratio sob retornos normais tem PSR(0) próximo de 95%.
A questão remanescente é o threshold contra o qual avaliar o PSR. Avaliar contra zero ignora o problema do Teorema 1 e infla artificialmente a probabilidade. O Deflated Sharpe Ratio aplica o PSR não ao threshold zero, mas ao threshold deflacionado pelo Teorema da Falsa Estratégia (BAILEY; LÓPEZ DE PRADO, 2014):
O DSR é, em palavras, a probabilidade de que o Sharpe ratio verdadeiro de uma estratégia exceda o Sharpe ratio máximo esperado sob hipótese nula com N tentativas e variância cross-section V. A diferença entre DSR e PSR é exatamente o desconto pela seleção. Uma estratégia que tem PSR(0) = 99,87% (parece imbatível) pode ter DSR = 40% após reconhecer que foi selecionada entre 1.000 candidatas, diferença que separa “alocar” de “investigar mais”.
O cálculo de N efetivo é não-trivial quando as estratégias são correlacionadas. O algoritmo ONC (Optimal Number of Clusters) usa a matriz de correlação dos retornos das estratégias para estimar o número de clusters como N efetivo (LÓPEZ DE PRADO; LEWIS, 2019). Essa correção é decisiva quando o grid varre micro-perturbações dos mesmos hiperparâmetros, situação em que N bruto superestima a multiplicidade efetiva.
Cross-validation combinatorialmente simétrica
O DSR fornece um corretivo paramétrico que assume normalidade do estimador e independência (ou correção via clustering). Em paralelo, a literatura propôs um diagnóstico não-paramétrico baseado em validação cruzada (BAILEY et al., 2017). O método chama-se Combinatorially Symmetric Cross-Validation (CSCV) e produz uma estatística chamada Probability of Backtest Overfitting (PBO).
Dada a matriz M de tamanho T × N (T observações de retornos para cada uma das N estratégias candidatas), particiona-se as linhas em S sub-amostras disjuntas de tamanho T/S, com S par. Para cada uma das C(S, S/2) escolhas de S/2 sub-amostras como conjunto de treino (in-sample), o complemento serve como conjunto de teste (out-of-sample). Em cada partição, identifica-se a estratégia vencedora in-sample (n*) e mede-se seu rank relativo no conjunto de teste. O logit do rank converte a estatística em uma escala simétrica em torno de zero. O PBO é a fração das partições em que o vencedor in-sample ficou abaixo da mediana out-of-sample.
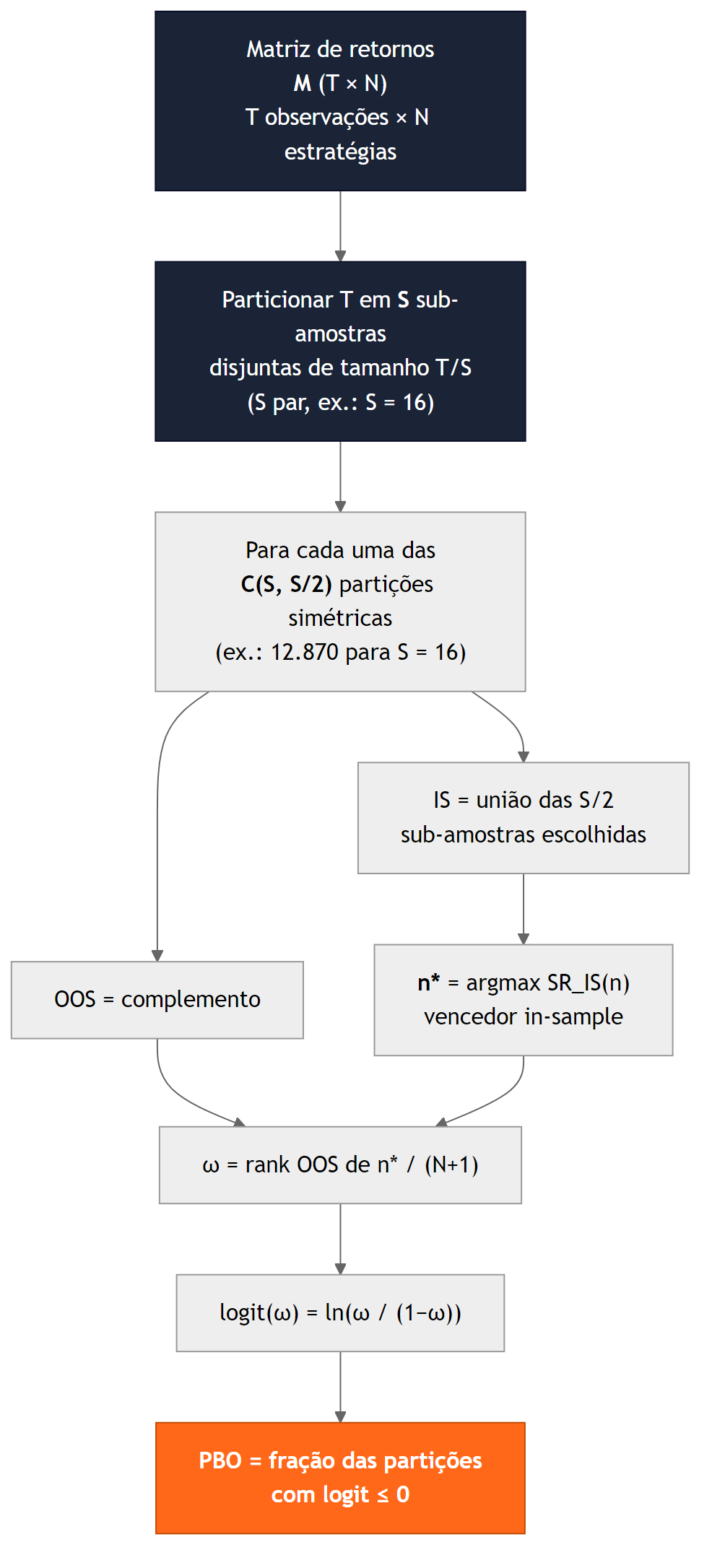
O adjetivo “combinatorialmente simétrico” é a chave do método. Cada observação aparece o mesmo número de vezes em conjuntos de treino e em conjuntos de teste através das C(S, S/2) partições, e a transformação (J, J̄) ↔ (J̄, J) é parte do conjunto. Isso elimina a assimetria temporal do walk-forward tradicional (que sempre treina no passado e testa no futuro, dando uma única trajetória de validação) e a quebra de ordem temporal do k-fold genérico, que ignora autocorrelação. Sob hipótese nula de retornos i.i.d. com média zero, o vencedor in-sample é tão provável de ficar acima quanto abaixo da mediana out-of-sample, e o PBO converge para 0,5. Quando há sinal genuíno em alguma estratégia, o PBO desce de forma marcada.
Uma comparação recente de métodos out-of-sample em ambiente sintético controlado documenta fragilidades do CSCV, mostrando que métodos tradicionais podem subestimar o risco de overfitting quando N é pequeno, há regimes de mercado ou as estratégias são altamente correlacionadas (ARIAN et al., 2024). A versão mais robusta para uso em pesquisa séria é o Combinatorial Purged Cross-Validation (CPCV), que adiciona purging (remoção de observações de treino cujos labels temporalmente se sobrepõem ao teste) e embargo (buffer adicional contra autocorrelação serial), gerando múltiplos caminhos out-of-sample (LÓPEZ DE PRADO, 2018). O custo é computacional, e para S = 16 são 12.870 ajustes de modelo.
DSR e PBO são diagnósticos complementares, um avaliando o candidato específico e o outro avaliando o procedimento que selecionou esse candidato. A tabela abaixo organiza as ferramentas discutidas até aqui pelo tipo de pergunta que cada uma responde.

Multiple testing e a crise de replicação em finanças
A literatura de econometria financeira chegou ao mesmo problema por outro caminho. Harvey, Liu e Zhu catalogaram aproximadamente 316 fatores publicados em journals de topo até 2012 e argumentaram que o threshold convencional de t-stat ≥ 2 é inadequado quando a profissão como um todo testa centenas de candidatos (HARVEY et al., 2016). Aplicando correções de testes múltiplos (Bonferroni, Holm e o controle de FDR de Benjamini-Hochberg-Yekutieli), eles propuseram que apenas fatores com t-stat acima de aproximadamente 3,0 deveriam ser considerados descobertas confiáveis. O haircut Sharpe correspondente é dado por:
onde pmt é o p-valor ajustado pela correção de testes múltiplos escolhida. O ajuste é matematicamente diferente do DSR mas conceitualmente análogo, e ambos descontam Sharpe ratios observados pelo número (efetivo) de tentativas que produziram o achado.
A confirmação empírica veio logo depois, em estudo que replicou 452 anomalias publicadas em journals de finanças usando metodologia padronizada (NYSE breakpoints, retornos value-weighted, controles de microestrutura), com aproximadamente 65% das anomalias falhando a replicar com t-stat acima de 1,96 fora da amostra original (HOU et al., 2020). Outra evidência mostra que retornos médios de anomalias caem cerca de 58% após a publicação acadêmica do paper que as documentou, padrão consistente com mistura de arbitragem real e seleção a posteriori (MCLEAN; PONTIFF, 2016). A magnitude dessa crise foi contestada por um modelo Bayesiano de replicação que incorpora correlação entre fatores, mas a direção qualitativa do problema permanece reconhecida (JENSEN et al., 2023).
Avançando essa linha, o problema se torna bilateral: correções clássicas tipo Bonferroni controlam erro tipo I (falsos positivos), mas com custo agudo em poder estatístico, descartando gestores e fatores genuinamente bons (HARVEY; LIU, 2020). O artigo propõe um double-bootstrap que calibra simultaneamente as duas taxas de erro. A literatura de teste de superioridade preditiva é mais antiga, e dois trabalhos canônicos resolvem variantes do mesmo problema. O Reality Check e o Model Confidence Set formalizam a comparação entre conjuntos de modelos sob hipótese nula composta, retornando intervalos para o melhor procedimento em vez de um vencedor pontual (WHITE, 2000; HANSEN et al., 2011).
Implementação em Julia
Disponibilizamos o pacote pq_backtest_overfitting em Julia que implementa, de forma transparente, os objetos centrais discutidos acima, do valor esperado do máximo Sharpe ratio até o PBO via CSCV. A escolha por Julia foi motivada pela ausência de biblioteca canônica equivalente no General Registry. Pacotes como Trading.jl e Fastback.jl oferecem motores de backtest orientados a eventos, mas nenhum traz a camada de validação estatística. Em Python, o mlfinlab implementa as mesmas funções, porém migrou para licença comercial em 2021. O pacote cobre toda a sequência da Tabela 2 em código aberto e auditável, com testes que reproduzem os anchors numéricos do paper original.
A função central traduz o Teorema 1 literalmente, com a constante de Euler-Mascheroni e a quantil normal padrão chamadas diretamente da biblioteca padrão da linguagem, sem aproximações intermediárias.
O DSR encadeia o Teorema da Falsa Estratégia com o PSR. Optei por receber a variância cross-section V como argumento explícito, em vez de inferi-la dos dados, porque a interpretação correta de V depende de o usuário ter calculado os N Sharpe ratios e tirado a variância amostral. Embutir essa etapa esconderia uma decisão delicada.
A implementação do CSCV é mais densa porque enumera explicitamente as C(S, S/2) combinações via Combinatorics.combinations. Para S = 16, são 12.870 partições, cada uma exigindo o cálculo de N Sharpe ratios in-sample e N out-of-sample. O custo é O(C(S, S/2) · N · T) e domina o tempo total. Mantive a estrutura de retorno como um struct nomeado para que o usuário tenha acesso aos logits brutos, e não apenas à estatística agregada PBO.

O pacote inclui suíte de testes que verifica os valores anchor citados na Figura 2 do paper original (N = 7 → ≈ 2 anos, N = 45 → ≈ 5 anos para SR* = 1), monotonicidade do PSR em skewness e kurtosis, convergência da simulação Monte Carlo dentro de 5% do valor teórico, e dois experimentos de PBO (sob hipótese nula com PBO próximo de 0,5, e com uma estratégia genuinamente boa puxando o PBO para abaixo de 0,1). Vinte testes passam em poucos segundos.
Resultados Monte Carlo
O script examples/demo_artigo.jl reproduz três experimentos. No primeiro, validamos o Teorema 1 em uma realização Monte Carlo direta gerando uma matriz T × N de retornos i.i.d. Normal(0, σ²) com σ = 1% diário (próximo do desvio-padrão diário do Ibovespa) e T = 1.008 dias (cerca de quatro anos de pregão), tomando depois o máximo dos N Sharpe ratios anualizados. Repete-se 2.000 vezes para obter a distribuição empírica do máximo.
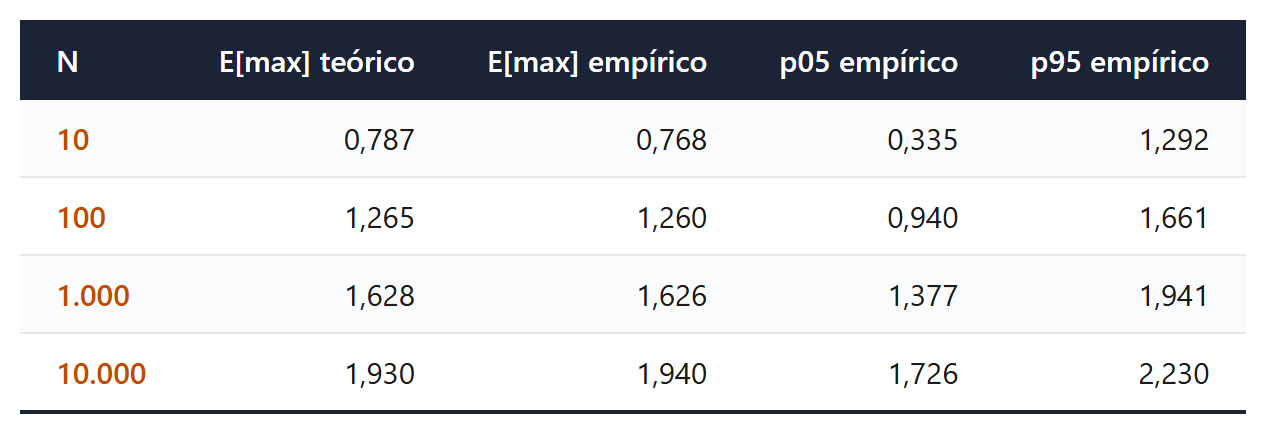
Para N = 1.000, o Teorema 1 prevê E[max SR] = 1,628 anualizado e a média empírica é 1,626, alinhamento apertado entre teoria e Monte Carlo. Os intervalos de 5% a 95% mostram que a variabilidade do máximo é alta. Para N = 100, o vencedor pode ter SR = 0,94 ou SR = 1,66 dependendo da realização, e isso significa que mesmo conhecendo o número de tentativas e a variância cross-section, o pesquisador disciplinado precisa pensar em distribuição, não em ponto.
O segundo experimento é o caso de uso central do DSR. Toma-se uma única realização (T = 1.008, N = 1.000, σ = 1%, drift verdadeiro zero) e calcula-se o Sharpe ratio anualizado de cada coluna. O vencedor tem SR_IS = 1,506, número que em qualquer relatório comercial seria apresentado como evidência de competência. O PSR avaliado contra zero é 99,87%, o que reforça a aparência. O DSR, no entanto, calcula a probabilidade de que o Sharpe ratio verdadeiro exceda E[max | N = 1000] e devolve 40,6%.

A diferença entre 99,87% e 40,6% é o desconto pela seleção, que separa “alocar” de “investigar mais”. O DSR diz, em substância, que o Sharpe ratio do vencedor é compatível com o que se espera por sorte de mil estratégias sem alfa. Aceitar o número bruto seria erro de inferência sobre a estratégia, não erro de estimação numérica. Esse é o ponto pedagógico que o paper de 2014 quis comunicar.
O terceiro experimento avalia o PBO via CSCV sobre uma matriz T = 1.008, N = 100, com S = 16 sub-amostras (12.870 partições). Sob hipótese nula i.i.d., o vencedor in-sample deveria ficar abaixo da mediana out-of-sample em metade das partições. Em uma realização específica, o PBO foi 0,648, valor próximo da expectativa teórica de 0,5 dada a variabilidade de uma única amostra com C(16, 8) ensaios.

O contraste com o caso em que uma das estratégias tem drift verdadeiro positivo é o que torna o método útil para diagnóstico. A suíte de testes inclui um exemplo com drift = 0,003/dia (Sharpe ratio anualizado verdadeiro de aproximadamente 4,8) em uma das colunas. O PBO desce para abaixo de 0,1, mostrando que o método separa corretamente sinal de ruído quando o sinal é forte. Em casos limítrofes, com drift próximo do nível de ruído, o PBO se mantém alto, e essa é justamente a região em que o pesquisador deveria recuar e cobrar mais dados.
Implicações para alocadores e quants
O artigo de 2014 exigiu que periódicos e prospectos reportassem o número de configurações testadas (N) e que leitores descontassem os Índices de Sharpe pelo Teorema 1. Onze anos depois, esse reporte segue sem mandato regulatório, enquanto a literatura empírica confirma que o *overfitting* é um problema profundo e imune a correções paramétricas isoladas.
Nesse cenário, Índices de Sharpe brutos em prospectos não atestam a qualidade de uma estratégia. O alocador de capital deve exigir o N e a variância cross-section dos Sharpe candidatos para computar o Deflated Sharpe Ratio (DSR), obtendo assim uma métrica comparável. A recusa do gestor em fornecer esses dados é, por si só, uma evidência decisiva contra ele. Para a pesquisa, o Teorema 2 sobre o MinBTL impõe que validar o vencedor de um grid de 1.000 estratégias exige de 10 a 14 anos de retornos diários. Ao lidar com séries mais curtas, típicas de mercados emergentes, o analista precisa reduzir N drasticamente, assumir premissas estruturais fortes ou aplicar DSR e Validação Cruzada Simétrica Combinatória (CSCV) antes de declarar qualquer descoberta.
Para quem roda as simulações internamente, o fluxo deve iniciar calculando a Probabilidade de Overfitting de Backtest (PBO) via CSCV sobre toda a família testada, antes de olhar para qualquer vencedor. Um PBO próximo a 0,5 indica que a seleção por Sharpe in-sample não tem validade out-of-sample, exigindo a reestruturação do grid. Para a estratégia validada, o DSR substitui o Sharpe bruto nas comunicações internas, mantendo-se o histórico sempre acima do MinBTL correspondente ao N efetivo para impedir que hipóteses sejam tratadas como descobertas.
O obstáculo atual é estritamente cultural e regulatório, permitindo que cada profissional corrija seu fluxo de trabalho sem aguardar mandatos externos. Incorporar métricas como PSR, DSR, CSCV e MinBTL tem um custo operacional marginal, mas a literatura recente sobre a crise de replicação (HOU et al., 2020; JENSEN et al., 2023) documenta exaustivamente que o verdadeiro prejuízo está em continuar pulando essa etapa.
Referências
ARIAN, H.; NOROUZI MOBAREKEH, D.; SECO, L. Backtest overfitting in the machine learning era: a comparison of out-of-sample testing methods in a synthetic controlled environment. Knowledge-Based Systems, v. 305, artigo 112477, 2024.
BAILEY, D. H.; BORWEIN, J. M.; LÓPEZ DE PRADO, M.; ZHU, Q. J. Pseudo-mathematics and financial charlatanism: the effects of backtest overfitting on out-of-sample performance. Notices of the American Mathematical Society, v. 61, n. 5, p. 458-471, 2014.
BAILEY, D. H.; BORWEIN, J. M.; LÓPEZ DE PRADO, M.; ZHU, Q. J. The probability of backtest overfitting. Journal of Computational Finance, v. 20, n. 4, p. 39-69, 2017.
BAILEY, D. H.; LÓPEZ DE PRADO, M. The Sharpe ratio efficient frontier. Journal of Risk, v. 15, n. 2, p. 3-44, 2012.
BAILEY, D. H.; LÓPEZ DE PRADO, M. The deflated Sharpe ratio: correcting for selection bias, backtest overfitting, and non-normality. Journal of Portfolio Management, v. 40, n. 5, p. 94-107, 2014.
HANSEN, P. R.; LUNDE, A.; NASON, J. M. The model confidence set. Econometrica, v. 79, n. 2, p. 453-497, 2011.
HARVEY, C. R.; LIU, Y. False (and missed) discoveries in financial economics. Journal of Finance, v. 75, n. 5, p. 2503-2553, 2020.
HARVEY, C. R.; LIU, Y.; ZHU, H. ...and the cross-section of expected returns. Review of Financial Studies, v. 29, n. 1, p. 5-68, 2016.
HOU, K.; XUE, C.; ZHANG, L. Replicating anomalies. Review of Financial Studies, v. 33, n. 5, p. 2019-2133, 2020.
JENSEN, T. I.; KELLY, B.; PEDERSEN, L. H. Is there a replication crisis in finance? Journal of Finance, v. 78, n. 5, p. 2465-2518, 2023.
LO, A. W. The statistics of Sharpe ratios. Financial Analysts Journal, v. 58, n. 4, p. 36-52, 2002.
LÓPEZ DE PRADO, M. Advances in financial machine learning. Hoboken: Wiley, 2018.
LÓPEZ DE PRADO, M.; LEWIS, M. J. Detection of false investment strategies using unsupervised learning methods. Quantitative Finance, v. 19, n. 9, p. 1555-1565, 2019.
MCLEAN, R. D.; PONTIFF, J. Does academic research destroy stock return predictability? Journal of Finance, v. 71, n. 1, p. 5-32, 2016.
WHITE, H. A reality check for data snooping. Econometrica, v. 68, n. 5, p. 1097-1126, 2000.