
Predição conformal em regressão: CQR aplicado a retornos do Ibovespa
Construção da Conformalized Quantile Regression com exemplo passo a passo do ajuste conformal sobre uma calibração concreta, e mini-backtest contra intervalos paramétricos e de bootstrap em onze anos

Digamos que um modelo de fechamento preveja o retorno de amanhã do Ibovespa em 0,3%. Esse número, sozinho, não diz nada sobre quão confiável ele é. Para um gestor de risco, a pergunta que importa não é qual o ponto, e sim qual o intervalo dentro do qual o retorno verdadeiro ficará com probabilidade 90%, por exemplo, e essa pergunta admite respostas radicalmente diferentes conforme a metodologia.
O primeiro artigo desta série apresentou o arcabouço da predição conformal, a única família de métodos com garantia frequentista de cobertura em amostra finita sob a premissa de intercambialidade (invariância da distribuição conjunta dos dados sob qualquer permutação dos índices, premissa estritamente mais fraca que i.i.d.). Este artigo aplica esse arcabouço a regressão, na variante Conformalized Quantile Regression (CQR) de Romano, Patterson e Candès (2019), e mede empiricamente seu desempenho em retornos diários do Ibovespa entre 2015 e 2025.
Métodos clássicos e a falta de garantias
O caminho clássico é o intervalo paramétrico. Ajusta-se uma janela móvel de 252 dias da média e do desvio padrão, e se constrói μt ± 1,645·σt. A cobertura sai correta marginalmente, mas a premissa é que retornos seguem distribuição normal e que a volatilidade da janela móvel reflete a volatilidade do dia seguinte. Em períodos de estresse, ambas as premissas falham. A inferência bayesiana exige um prior que rara vez é defensável quantitativamente para retornos.
O bootstrap dos resíduos parece uma saída não paramétrica, mas tem validade apenas assintótica. O argumento clássico de Efron (1979) exige n → ∞ para que a distribuição empírica dos resíduos convirja para a distribuição populacional do erro, e em amostra finita as caudas empíricas subestimam sistematicamente os quantis extremos. O procedimento i.i.d. ainda assume resíduos identicamente distribuídos, suposição inadequada em séries financeiras com volatilidade clusterizada. O bootstrap em blocos (KÜNSCH, 1989) corrige parcialmente essa lacuna reamostrando blocos contíguos de resíduos de comprimento L, o que preserva a estrutura de dependência local. Continua, porém, amostrando da distribuição marginal das janelas observadas, sem condicionar ao estado de volatilidade do dia que se quer prever.
A predição conformal é a única família com garantia frequentista de cobertura em amostra finita sem premissas distribucionais, condicionada apenas à intercambialidade.
Garantia de cobertura frequentista (paráfrase de Lei et al., 2018, e Romano, Patterson e Candès, 2019).
Sob intercambialidade da sequência (Xi, Yi), o intervalo conformal indutivo Cα(Xn+1) construído a partir de um conjunto de calibração de tamanho n satisfaz ℙ(Yn+1 ∈ Cα(Xn+1)) ≥ 1 − α em amostra finita, sem hipóteses sobre a distribuição conjunta dos dados. A probabilidade é marginal, tomada sobre toda a distribuição conjunta do conjunto de calibração e do par de teste.
O mecanismo é comum a todas as variantes desta família. Computa-se um score de não-conformidade num conjunto de calibração separado, toma-se seu quantil empírico ao nível desejado, e usa-se esse quantil como ajuste sobre as predições do modelo base. CQR aplica esse mecanismo a quantis condicionais estimados, e é a primeira variante que vamos construir e testar no Ibovespa.
Regressão quantílica como base
A alternativa que dispensa a hipótese de normalidade é estimar diretamente os quantis condicionais da distribuição de retornos, sem passar pela média e pelo desvio padrão. Sob heterocedasticidade ou caudas pesadas, a média condicional 𝔼[Y | X = x] minimizada por mínimos quadrados não captura a estrutura completa da distribuição condicional, e os quantis carregam mais informação sobre a banda de incerteza.
Koenker e Bassett (1978) introduziram a regressão quantílica como o estimador que minimiza a pinball loss:
A função ρτ penaliza assimetricamente os resíduos positivos e negativos, com erros u > 0 (previsão abaixo do observado) pesando τ e erros u < 0 (previsão acima do observado) pesando (1 − τ). Minimizar ρτ é equivalente a exigir que a fração de observações com u < 0 seja exatamente τ, condição que reproduz a definição populacional do τ-quantil condicional, ℙ(Y < Qτ(X) | X) = τ, e a calibração das inclinações em τ e (1 − τ) é o que materializa essa propriedade na função de perda. O nome pinball vem do formato em V do gráfico da função, cujos dois ramos têm inclinações τ e (1 − τ).
Para τ = 0,5, ρτ se reduz à perda absoluta e a função estimada é a mediana condicional. Para τ = 0,05, o estimador converge ao quantil 5% condicional, e analogamente para τ = 0,95. Modelos modernos como Quantile Random Forest (MEINSHAUSEN, 2006) e Quantile Gradient Boosting (objetivo quantile no LightGBM de KE et al., 2017) treinam um modelo separado por nível τ minimizando a pinball loss, sem assumir forma paramétrica para a distribuição condicional.
Para o retorno de amanhã do Ibovespa, isso significa treinar dois modelos, um para o quantil 5% condicional a lags de retorno e volatilidade recente, e outro para o quantil 95%. O intervalo nominal é o par. O problema é que esses estimadores não trazem garantia de cobertura. Em pequenas amostras ou sob especificação incorreta, a cobertura empírica do intervalo [q̂α/2(x), q̂1−α/2(x)] pode ficar arbitrariamente abaixo de 1−α. CQR resolve essa lacuna.
CQR e o ajuste conformal sobre quantis
CQR aplica calibração via predição conformal indutiva (ICP, baseada em uma única partição treino/calibração, em contraste com variantes transdutivas que refazem o ajuste para cada ponto novo) sobre os quantis condicionais estimados por regressão quantílica. A construção tem três passos.
Primeiro, dada uma partição treino/calibração, ajustam-se q̂α/2 e q̂1−α/2 no conjunto de treino. Para o Ibovespa, isso é dois LightGBM treinados de 2004 a 2013.
Segundo, define-se em cada ponto i do conjunto de calibração o score CQR, uma medida de não-conformidade entre Yi e o intervalo nominal estimado.
Score CQR (paráfrase de Romano, Patterson e Candès, 2019).
O score de não-conformidade Ei da Conformalized Quantile Regression (CQR) é a violação máxima entre o limite inferior q̂α/2(Xi) e o limite superior q̂1−α/2(Xi) do intervalo nominal. Quando Yi fica fora do intervalo, Ei é positivo e mede a folga abaixo do quantil inferior ou acima do quantil superior. Quando fica dentro, Ei é negativo e mede a margem ao limite mais próximo.
Terceiro, o quantil empírico Q̂ desses scores ao nível (1−α)(1 + 1/ncal) define o ajuste:
A garantia ℙ(Yn+1 ∈ Cα(Xn+1)) ≥ 1−α vale em amostra finita sob intercambialidade, herdada da estrutura ICP de Lei et al. (2018) e Romano, Patterson e Candès (2019). É uma garantia marginal, com a probabilidade tomada sobre toda a distribuição conjunta do conjunto de calibração e do par de teste, sem condicionar em um valor específico X = x. A largura |Cα(x)| = q̂1−α/2(x) − q̂α/2(x) + 2Q̂ é uma função de x e varia com a dispersão condicional estimada pelos quantis. Em períodos de alta volatilidade, q̂1−α/2(x) e q̂α/2(x) se afastam, e o intervalo se alarga automaticamente.
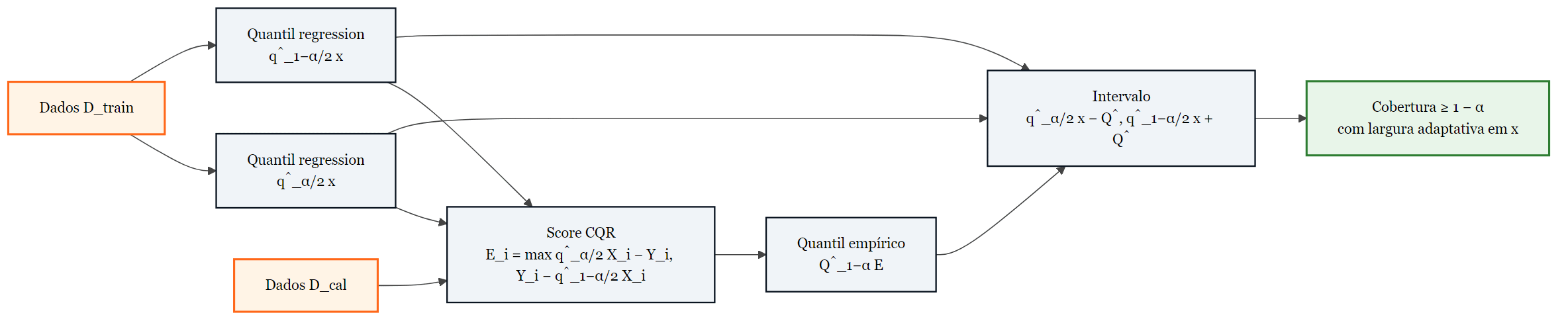
Pipeline da CQR. Dois modelos quantílicos são treinados em D_train, o score CQR é calculado em D_cal, e o quantil empírico desses scores define o ajuste aplicado ao intervalo final, que herda adaptatividade local da regressão quantílica.
Aplicado ao Ibovespa, isso vira ajustar dois LightGBM em 2004 a 2013, computar os scores CQR em 2014, tomar o quantil empírico Q̂, e aplicar [q̂5%(x) − Q̂, q̂95%(x) + Q̂] a cada dia do conjunto de teste 2015 a 2025.
O ajuste em ação, passo a passo
O procedimento fica mais palpável com um conjunto de calibração concreto e pequeno, suficiente para mostrar cada passo. A animação percorre n = 6 pontos de calibração, calcula o score Ei = max(q̂5%(Xi) − Yi, Yi − q̂95%(Xi)) para cada um, toma o quantil empírico Q̂ ao nível (1 − α)(1 + 1/n), e aplica o ajuste a um ponto de teste novo com q̂5%(x) = −0,7 e q̂95%(x) = +0,9.
Cada par (q̂5%(Xi), q̂95%(Xi)) na animação é a saída dos dois LightGBM quantílicos quando avaliados nos features Xi daquele dia. Os valores diferem entre pontos porque a regressão quantílica é condicional aos features. Em dias com volatilidade recente baixa, q̂5% e q̂95% se aproximam e o intervalo nominal fica estreito. Em dias com volatilidade alta ou retornos extremos recentes, o par se afasta e o intervalo alarga. O ponto i = 1 da animação mostra um caso intermediário, com (q̂5%, q̂95%) = (−0,8, +0,9) e largura nominal 1,7. O ponto i = 3 traz um intervalo mais estreito, (−0,5, +0,6), correspondente a um regime mais calmo. O ponto i = 4 entrega um intervalo deslocado para baixo, (−1,6, −0,2), em que a mediana condicional estimada também desce.
Em cada ponto, o procedimento compara o retorno observado Yi ao par (q̂5%(Xi), q̂95%(Xi)) e calcula o score Ei = max(q̂5%(Xi) − Yi, Yi − q̂95%(Xi)). No ponto i = 1, Y1 = +0,5 cai dentro do intervalo [−0,8, +0,9], e E1 = max(−1,3, −0,4) = −0,4 fica negativo, com magnitude igual à distância ao limite mais próximo (o quantil superior em +0,9). No ponto i = 2, Y2 = −1,5 fura o limite inferior q̂5% = −1,2 por 0,3, e E2 = +0,3 fica positivo. No ponto i = 3, Y3 = +0,8 ultrapassa o limite superior q̂95% = +0,6 por 0,2, com E3 = +0,2. Os pontos i = 4, i = 5 e i = 6 ficam dentro de seus intervalos estimados, com scores negativos de −0,4, −0,6 e −0,2 respectivamente. Linhas vermelhas na animação marcam as violações (Ei > 0), verdes os pontos dentro (Ei ≤ 0).
Depois de percorrer os seis pontos, a coleção ordenada de scores é {−0,6, −0,4, −0,4, −0,2, +0,2, +0,3}. O quantil empírico Q̂ se calcula no nível (1 − α)(1 + 1/n) = 0,9 × 7/6 = 1,05. Esse nível ultrapassa 1, situação esperada em amostras pequenas. A regra de finite-sample correction trunca em 1, e Q̂ vira o máximo dos scores, ou seja, Q̂ = +0,30 (o valor de E2, a maior violação observada). Para n maior, com algumas centenas de pontos de calibração, o nível ajustado fica abaixo de 1 e Q̂ pega um percentil interior da coleção, em vez do máximo.
O ajuste se aplica ao ponto de teste novo. Os dois LightGBM quantílicos, avaliados nos features do dia de teste, retornam q̂5%(xnew) = −0,7 e q̂95%(xnew) = +0,9. O intervalo conformal infla o nominal por Q̂ em cada lado, com q̂5%(xnew) − Q̂ = −0,7 − 0,3 = −1,0 no limite inferior e q̂95%(xnew) + Q̂ = +0,9 + 0,3 = +1,2 no superior. O intervalo final Cα(xnew) = [−1,0, +1,2] tem largura 2,2, contra largura nominal 1,6 do par bruto (q̂5%, q̂95%). A inflação de 0,6 corresponde ao preço pago pela garantia frequentista em amostra finita, calibrado pelas violações observadas no conjunto de calibração.
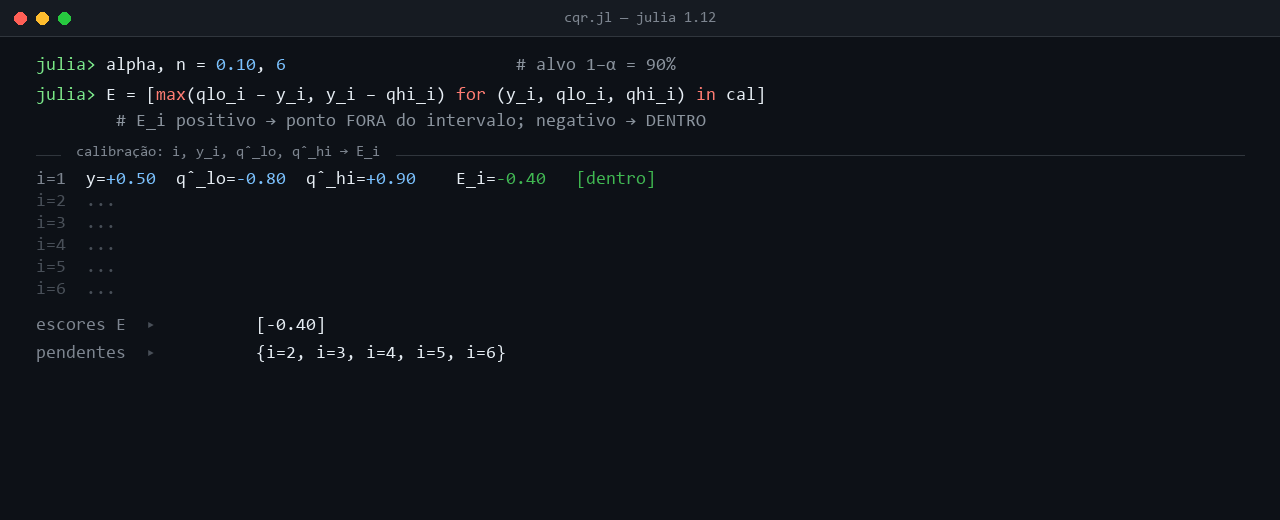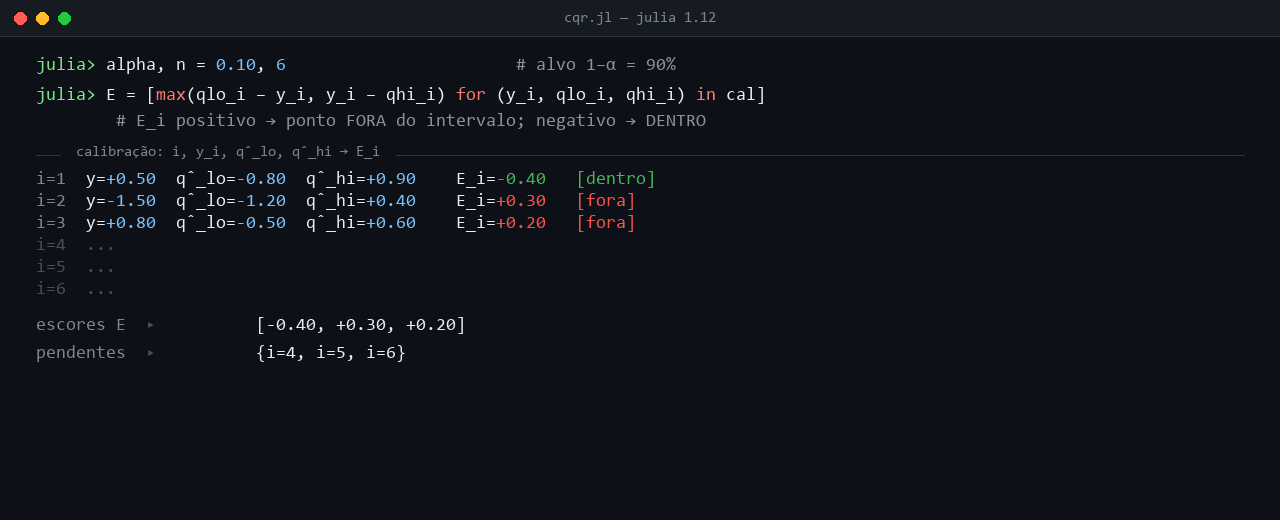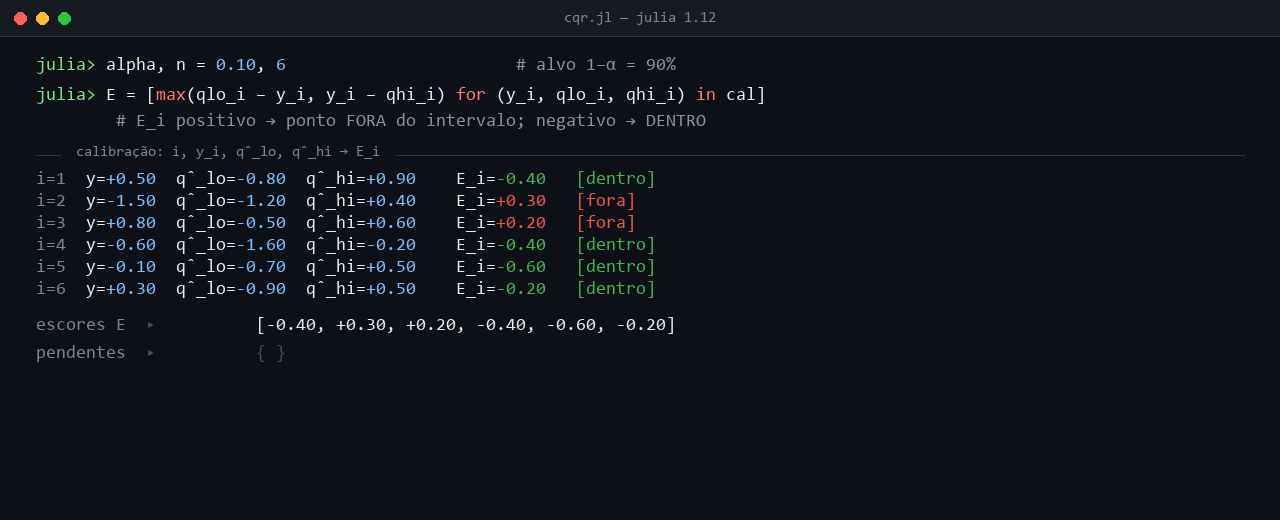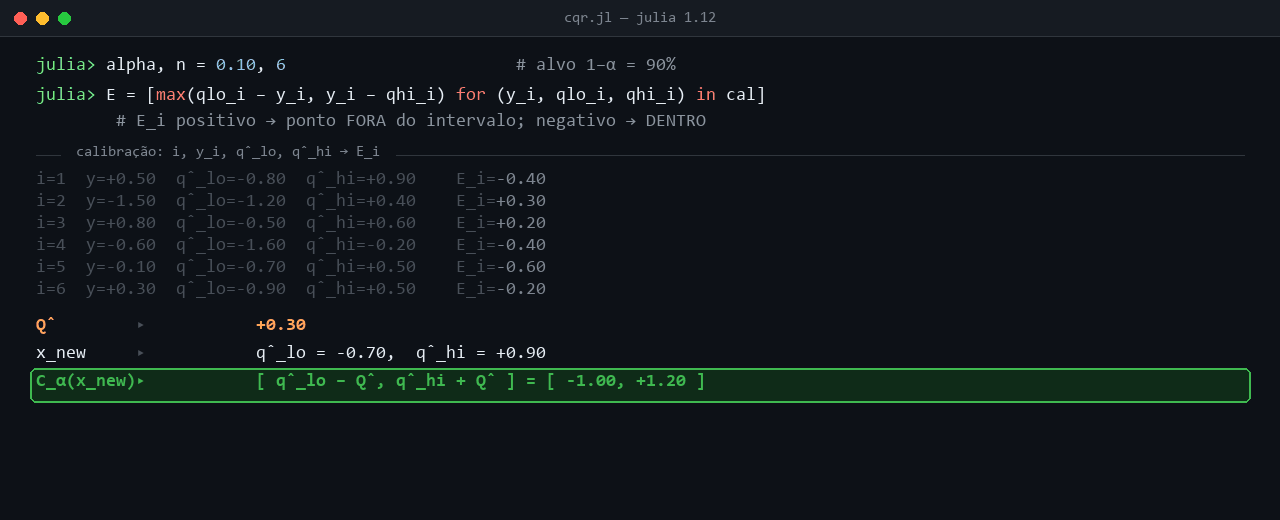
anim_cqr_passo_a_passo.png.O score CQR sintetiza num único número a violação simultânea dos quantis inferior e superior, sem favorecer um dos lados, o que mantém o ajuste simétrico. A calibração das inclinações τ e (1 − τ) da pinball loss tampouco dispensa o passo conformal, porque a regressão quantílica entrega quantis condicionais sem garantia frequentista de cobertura, e é Q̂ que fecha essa lacuna.
A construção dispensa hipóteses sobre a forma da distribuição condicional, mas exige intercambialidade dos dados. Essa premissa precisa ser examinada antes de transportar a teoria para o Ibovespa.
Intercambialidade e séries financeiras
A premissa de intercambialidade que sustenta CQR é violada por construção em séries temporais financeiras. Retornos diários não são i.i.d. A volatilidade clusteriza, retornos absolutos exibem autocorrelação serial não-desprezível em lags de várias semanas, e regimes macroeconômicos alteram a distribuição condicional ao longo do tempo. Aplicar diretamente a teoria a um par treino/calibração tomado da série em ordem cronológica significa, formalmente, perder a garantia que motiva a escolha do método.
A aproximação ainda assim se sustenta porque condicionar nas features atenua essa violação. A distribuição condicional de Y dado X, com X composto por lags de retorno e volatilidade realizada, é mais próxima de estacionária do que a distribuição marginal de Y, porque as features absorvem o estado dinâmico do mercado. O resíduo conformal calculado sobre X carrega menos dependência temporal do que o retorno bruto, e a violação efetiva de intercambialidade fica menor do que uma leitura ingênua da série sugere.
Barber, Candès, Ramdas e Tibshirani (2023), em “Conformal prediction beyond exchangeability”, formalizam essa intuição.
Cobertura sob violação de intercambialidade (paráfrase de Barber, Candès, Ramdas e Tibshirani, 2023).
Quando a sequência (Xi, Yi) deixa de ser intercambiável, a probabilidade marginal de cobertura cai do nível nominal 1 − α por uma penalidade Δ proporcional à distância em variação total média entre a distribuição conjunta dos dados e suas versões permutadas. Em séries aproximadamente estacionárias Δ é pequeno e a garantia permanece controlada. Em séries com drift abrupto, Δ cresce.
No caso brasileiro, esse Δ é o que o backtest mede empiricamente, e a comparação com o alvo nominal indica quão custosa é a violação de intercambialidade na série diária do Ibovespa.
Há ainda outra característica do enunciado da garantia com peso na interpretação empírica. A probabilidade ℙ(Yn+1 ∈ Cα(Xn+1)) ≥ 1 − α se calcula sobre toda a distribuição conjunta do par de teste e do conjunto de calibração, e essa propriedade marginal não se estende automaticamente a sub-regiões do espaço de features. A versão condicional ℙ(Yn+1 ∈ Cα | Xn+1 = x) ≥ 1 − α, válida para cada x específico, é estritamente mais forte e exigiria suposições adicionais sobre a regularidade dos quantis estimados que ICP e CQR clássicos não impõem. Em sub-populações como dias de volatilidade realizada elevada, a cobertura efetiva pode ficar abaixo do alvo enquanto a cobertura na média da série permanece dentro dele. O contraste entre cobertura marginal e cobertura condicional é o que separa um número global próximo do alvo de uma cobertura preservada em todos os regimes de risco.
Resultados no Ibovespa, 2014 a 2025
O dataset é composto por retornos logarítmicos diários do Ibovespa (^BVSP no Yahoo Finance) entre janeiro de 2004 e dezembro de 2025, totalizando 5426 observações com features completas. As features são lags de retornos (1, 5 e 22 dias), volatilidades realizadas em janelas de 5 e 22 dias, e lags de retornos absolutos. Os splits temporais são fixos: 2004 a 2013 para treino (2449 dias), 2014 para calibração da CQR (248 dias), e 2015 a 2025 para teste (2729 dias). O conjunto de teste cobre onze anos com regimes muito distintos, incluindo a crise fiscal brasileira de 2015 a 2016, o Joesley Day em 2017, a campanha eleitoral de 2018, a pandemia em 2020, o ciclo de juros e a disputa eleitoral em 2022, e o ciclo fiscal subsequente.
Três métodos entram na comparação. Paramétrico (rolling 252d), bootstrap em blocos sobre regressão linear (Künsch, 1989, com L = 22 dias e 1000 reamostragens), e CQR com dois LightGBM (objetivo quantile, τ = 0,05 e 0,95). O alvo de cobertura é 1 − α = 90%.
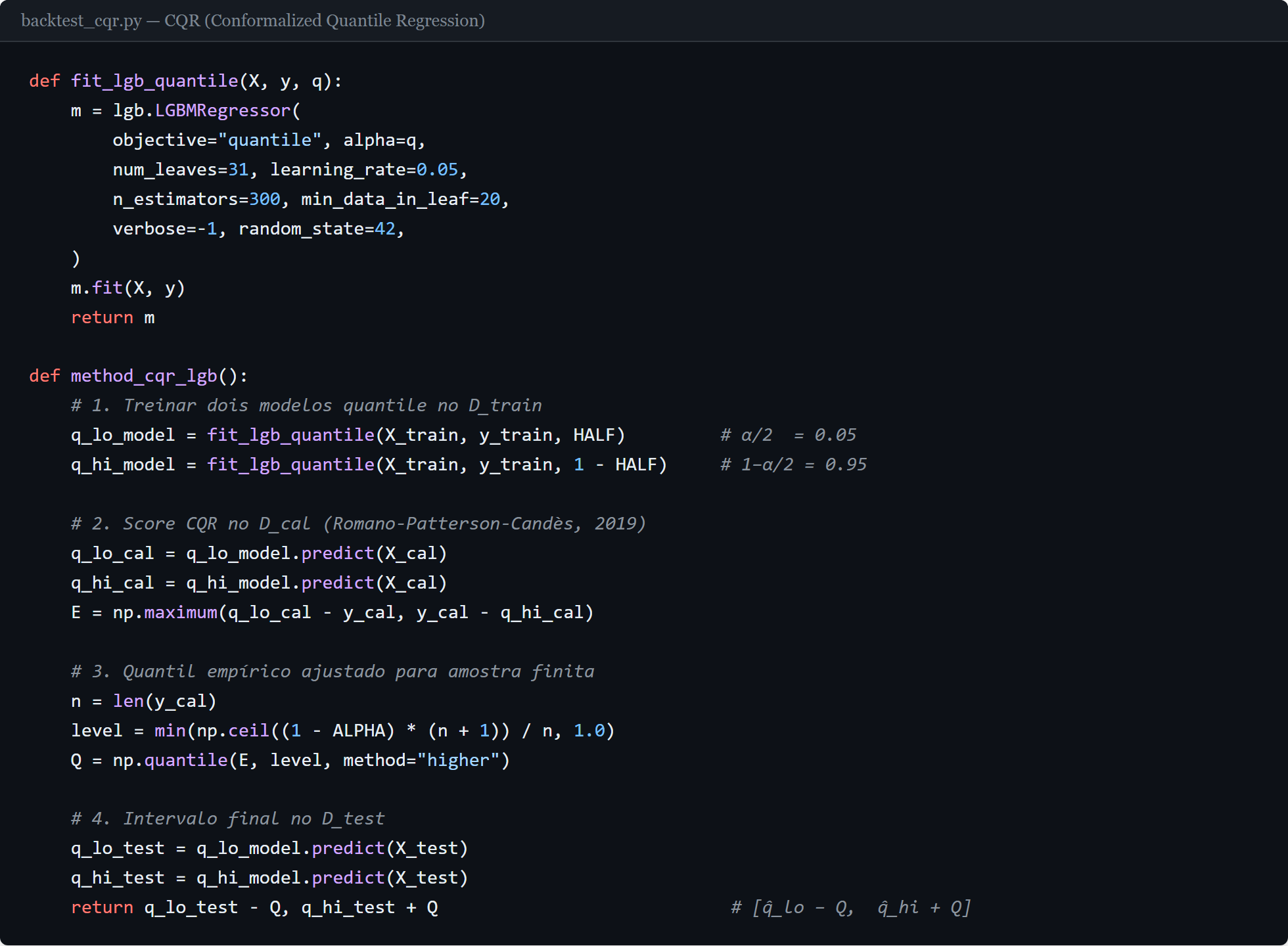
backtest_cqr.py com a implementação de CQR em Python. Dois modelos LightGBM com objetivo quantile são treinados, o score CQR de Romano, Patterson e Candès (2019) é calculado sobre o conjunto de calibração, e o quantil empírico desses scores define o ajuste aplicado ao intervalo final. Código completo em pq_conformal_prediction.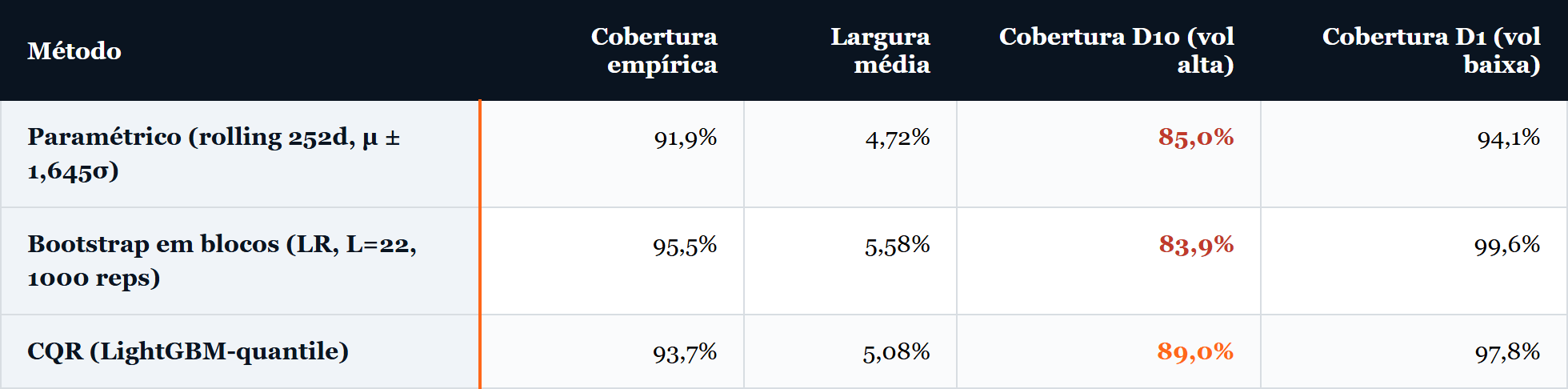
CQR sai com cobertura empírica 93,7% e largura média 5,08%, ligeiramente acima do alvo nominal de 90%, com banda que se alarga ou se estreita conforme a volatilidade condicional estimada pelos LightGBM. O paramétrico mantém cobertura 91,9% com largura menor, 4,72%, mas com banda rígida que responde apenas pela janela móvel de 252 dias e não pela estrutura condicional do dia. O bootstrap em blocos fica em 95,5% e 5,58%, a banda mais larga das três.
A cobertura empírica de CQR supera o alvo nominal de 90% em 3,7 pontos percentuais, indicação de que a correção (1 − α)(1 + 1/ncal) e a estabilidade do conjunto de calibração de 2014 produziram quantis empíricos conservadores. Na cota de Barber, Candès, Ramdas e Tibshirani (2023), o termo Δ que mediria o custo da violação de intercambialidade fica não-positivo na média do período de teste, porque as features condicionais absorvem a dinâmica da série diária. A análise por decil de volatilidade mostra que essa folga global se concentra nos regimes calmos.
A diferença qualitativa fica nítida em regime de estresse. A figura abaixo mostra a banda paramétrica e a banda CQR sobre o Ibovespa entre fevereiro e abril de 2020, quando a pandemia disparou a volatilidade.
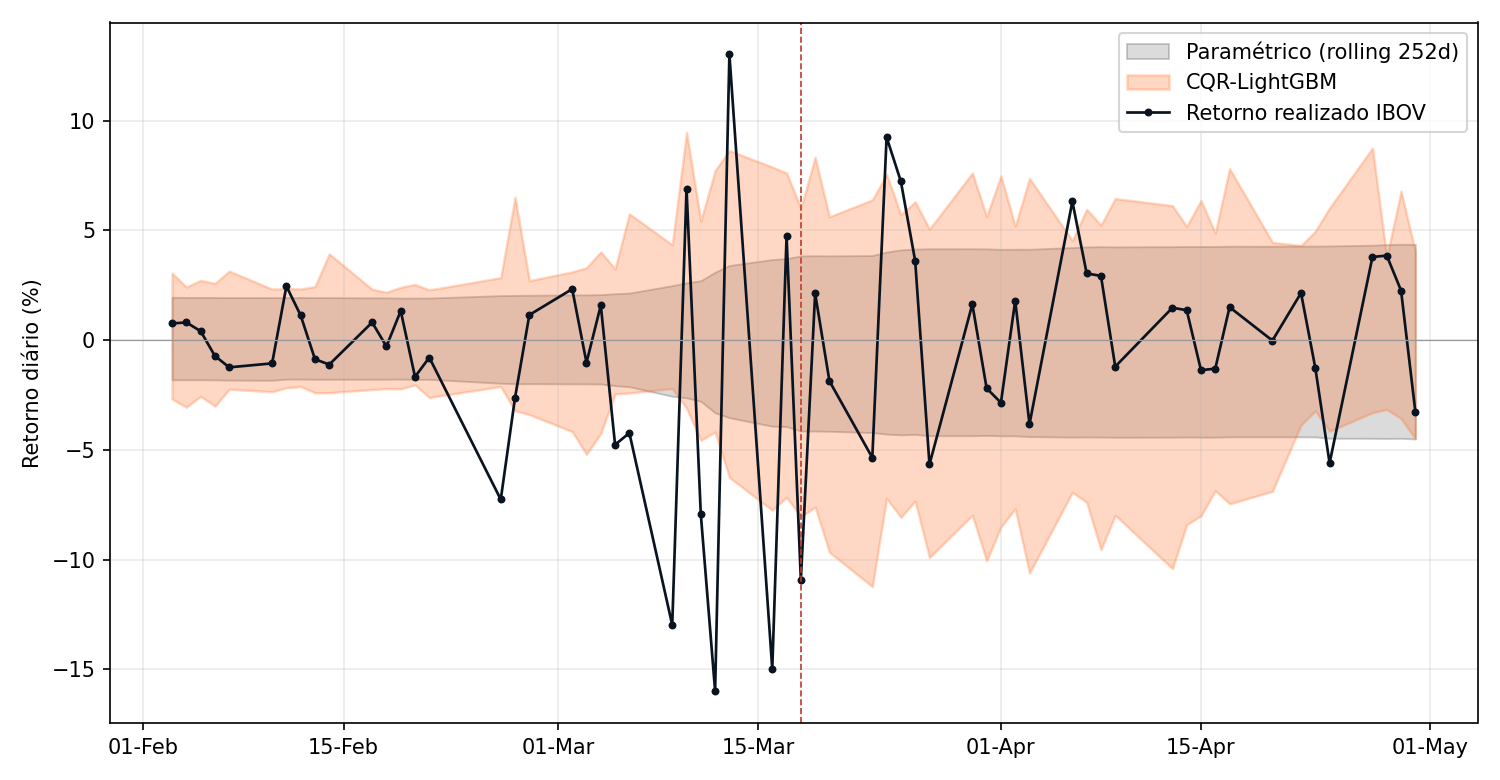
O ganho qualitativo de CQR sobre os outros métodos é a adaptação local da banda, o resultado mais consequente para uso em produção. Em períodos calmos, a banda CQR se estreita acompanhando os quantis condicionais. Em regime de estresse, alarga em poucos pregões, mantendo a cobertura por classe de volatilidade em vez de na média global.
O LightGBM serve como implementação dos quantis condicionais, mas a CQR independe dessa escolha. Substituindo a base por regressão quantílica linear (Koenker e Bassett, 1978) sobre as mesmas sete features, a CQR resultante atinge cobertura global 91,9%, largura 4,63%, e D10 91,2%, este último ligeiramente acima do alvo nominal. A versão linear é portanto competitiva com a versão LightGBM em todas as métricas deste exemplo. O ganho específico de gradient boosting fica reservado para configurações com mais features ou interações não-lineares que a regressão linear não captura. Neste caso, o componente que carrega o resultado é o conformal layer Q̂.
Onde a cobertura marginal esconde o problema
A cobertura empírica global de 93,7% (CQR), 91,9% (paramétrico) e 95,5% (bootstrap em blocos) sugere que os três métodos atingem ou superam o alvo de 90%. A coluna D10 da tabela mostra a outra história. No decil de maior volatilidade realizada (22 dias) durante o conjunto de teste, o paramétrico cai a 85,0%, o bootstrap em blocos a 83,9%, e CQR fica em 89,0%. As duas variantes de CQR são as únicas que se aproximam ou cruzam o alvo em D10, com 89,0% para a versão LightGBM e 91,2% para a versão linear, enquanto paramétrico e bootstrap em blocos perdem entre cinco e seis pontos percentuais para o alvo.
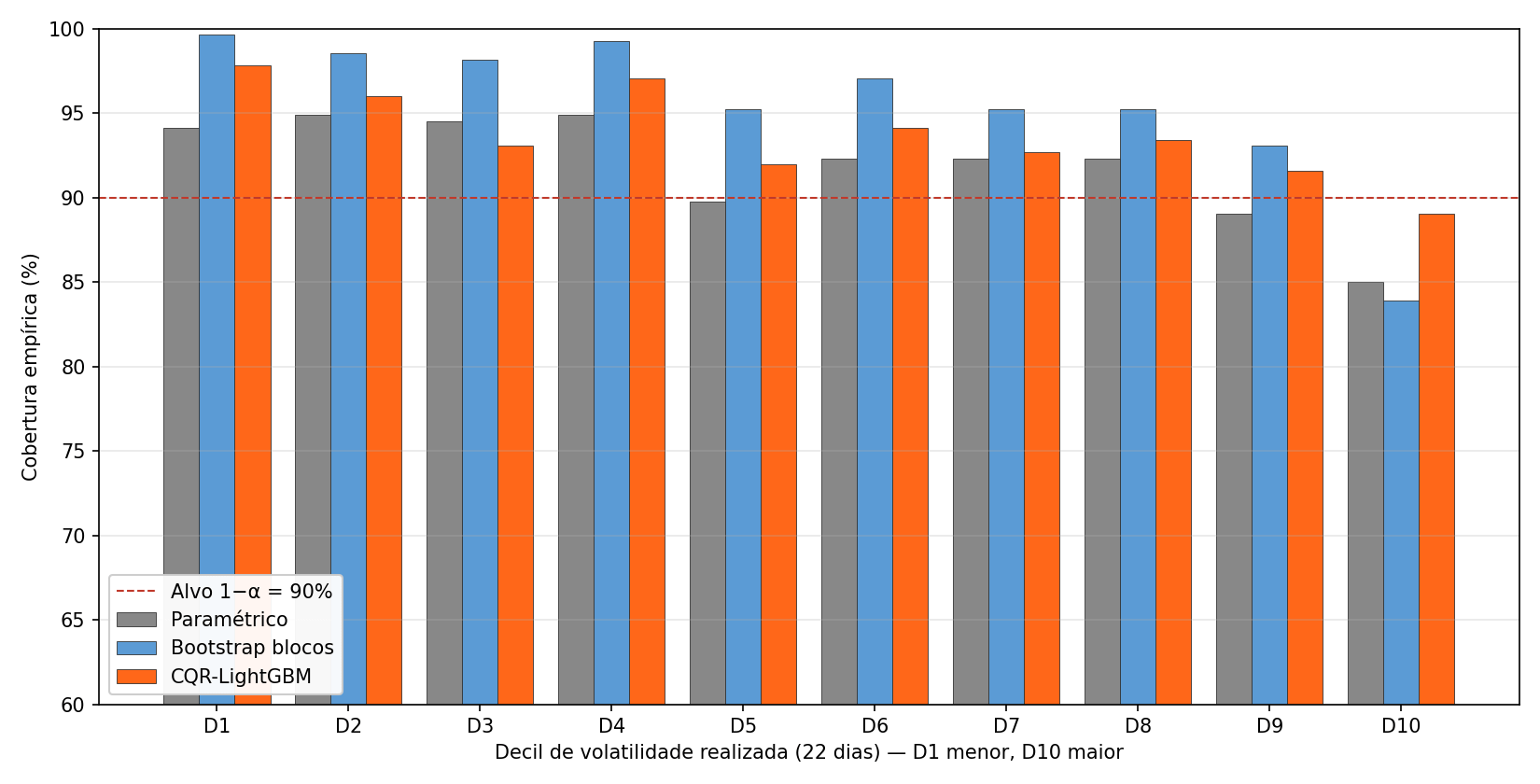
A cobertura marginal correta esconde, portanto, subcobertura sistemática nos dias que mais importam. O decil 10 contém a crise fiscal brasileira de 2015 a 2016, o Joesley Day em maio de 2017, a campanha eleitoral de 2018, a pandemia em março de 2020, e o ciclo de juros e disputa eleitoral em 2022, justamente onde uma garantia de cobertura é mais valiosa para alocação de risco.
A análise global mede a cobertura na média sobre regimes muito diferentes de volatilidade, sem identificar onde a aproximação falha. As duas variantes de CQR mantêm cobertura próxima ao alvo nominal nos regimes de alta volatilidade, ao custo de uma janela de calibração de 248 dias em 2014 que não contribui para a estimação dos quantis condicionais. A cobertura preservada em D10, onde paramétrico e bootstrap em blocos perdem cinco a seis pontos percentuais para o alvo, é o diferencial empírico mais consequente para alocação de capital.
Referências
BARBER, R. F.; CANDÈS, E. J.; RAMDAS, A.; TIBSHIRANI, R. J. Conformal prediction beyond exchangeability. The Annals of Statistics, v. 51, n. 2, p. 816-845, 2023.
EFRON, B. Bootstrap methods: another look at the jackknife. The Annals of Statistics, v. 7, n. 1, p. 1-26, 1979. DOI: 10.1214/aos/1176344552.
KE, G.; MENG, Q.; FINLEY, T.; WANG, T.; CHEN, W.; MA, W.; YE, Q.; LIU, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In: Advances in Neural Information Processing Systems 30 (NIPS 2017). 2017. p. 3146-3154.
KOENKER, R.; BASSETT, G. Regression Quantiles. Econometrica, v. 46, n. 1, p. 33-50, 1978. DOI: 10.2307/1913643.
KÜNSCH, H. R. The jackknife and the bootstrap for general stationary observations. The Annals of Statistics, v. 17, n. 3, p. 1217-1241, 1989. DOI: 10.1214/aos/1176347265.
LEI, J.; G’SELL, M.; RINALDO, A.; TIBSHIRANI, R. J.; WASSERMAN, L. Distribution-Free Predictive Inference for Regression. Journal of the American Statistical Association, v. 113, n. 523, p. 1094-1111, 2018. DOI: 10.1080/01621459.2017.1307116.
MEINSHAUSEN, N. Quantile Regression Forests. Journal of Machine Learning Research, v. 7, p. 983-999, 2006.
ROMANO, Y.; PATTERSON, E.; CANDÈS, E. J. Conformalized Quantile Regression. In: Advances in Neural Information Processing Systems 32 (NeurIPS 2019). 2019. p. 3543-3553.