
Quando e como tornar as séries estacionárias para modelagem de machine learning (parte 2)
Do diagnóstico à transformação: uma abordagem prática e automatizada para séries temporais econômicas

Conforme estabelecido na primeira parte desse artigo ¨Parte 1”, vamos falar sobre testes de estacionariedade e uma forma de automatizar transformações para estacionariedade quando temos muitas séries para tratar. Vamos sugerir uma maneira de abordar o problema e de automatizar o trabalho, embora haja várias outras possíveis.
Primeiramente, haverá uma explicação sobre os testes de estacionariedade e, em seguida, é explicado em detalhes o código que automatiza o trabalho referido, com alguns exemplos de séries do IBGE e que pode ser baixado de pq_sidra_stationary e executado em seu computador.
Vamos lá!
Testes de estacionariedade: ADF, KPSS e alternativas
Para verificar objetivamente se uma série é estacionária, estatísticos desenvolveram diversos testes. Dois dos mais utilizados e complementares entre si são o Teste ADF (Augmented Dickey-Fuller) e o Teste KPSS (Kwiatkowski-Phillips-Schmidt-Shin). Cada um adota uma hipótese nula diferente, por isso costumam ser aplicados em conjunto para fornecer evidências mais robustas:
Teste de Dickey-Fuller Aumentado (ADF): É um dos testes de raiz unitária mais populares. A hipótese nula H0 do ADF é de que a série possui uma raiz unitária, ou seja, não é estacionária (possui um componente de passeio aleatório). A hipótese alternativa H1 é que a série seja estacionária (estritamente, estacionária sem tendência) ou estacionária em torno de uma tendência determinística, dependendo da formulação do teste. Intuitivamente, o teste ADF verifica se um parâmetro φ em uma equação Yt = φ * Y{t-1} + … é igual a 1 (indicando passeio aleatório) ou menor que 1 em magnitude (indicando estacionariedade). Valores de teste ADF muito negativos sugerem rejeição de H0 de raiz unitária, apontando estacionariedade. Convencionalmente, se o p-valor do ADF < 0,05, rejeitamos a hipótese de raiz unitária e concluímos que a série é estacionária (em nível de confiança 95%). Caso contrário, não há evidência suficiente para rejeitar a não-estacionariedade.
Vantagens: O ADF é simples e amplamente disponível em softwares; ele considera possíveis lags autoregressivos adicionais (por isso "aumentado") para tornar os resíduos aproximadamente brancos.
Limitações: Tem potência estatística limitada em amostras pequenas – ou seja, pode falhar em detectar estacionariedade quando a série é apenas ligeiramente menor que 1 em φ. Além disso, o ADF assume forma funcional fixa (pode incluir ou não intercepto e termo de tendência na regressão de teste); incluir um termo de tendência muda a hipótese nula para “não estacionária com deriva” vs “estacionária em torno de uma tendência”. Se a série tiver quebras estruturais (mudanças de nível não tratadas), o ADF pode interpretar isso como evidência de não-estacionariedade mesmo que, por partes, a série seja estacionária. Em suma, um p-valor alto no ADF sugere que a série pode precisar de diferenciação, mas deve-se ter cuidado: pode ser necessário tentar diferentes configurações (com ou sem tendência no teste) e verificar complementos como KPSS antes de concluir.
Teste KPSS: Ao contrário do ADF, o teste KPSS formula a hipótese nula oposta. Em H0 assume-se que a série é estacionária (em torno de uma tendência determinística), e a alternativa H1 é de que a série possui uma raiz unitária (não estacionária). Essencialmente, KPSS verifica se a variância do passeio aleatório subjacente é zero (estacionariedade) ou positiva (não estacionária). O teste retorna uma estatística e compara com valores críticos; se o p-valor do KPSS < 0,05, rejeitamos H0 e concluímos que a série não é estacionária (ou seja, evidência de raiz unitária).
Vantagens: Útil para confirmar resultados do ADF – por exemplo, se o ADF não rejeita raiz unitária e o KPSS rejeita estacionariedade, ambos concordam que a série é não estacionária.
Limitações: O KPSS tende a ser conservador (pode acusar não-estacionariedade facilmente, mesmo por pequenas violações), e pode superestimar ordem de integração em certos casos. Também requer escolher um parâmetro de truncamento (para estimar uma longa autocovariância) que pode afetar o resultado. Em séries muito curtas, o KPSS pode rejeitar a estacionariedade devido a ruído. Em geral, é usado como complemento: se ADF e KPSS conflitam, o caso é inconclusivo ou sugere que a série talvez seja estacionária em torno de uma tendência (situação onde ADF com tendência pode não detectar a raiz unitária mas KPSS detecta qualquer desvio da estacionariedade estrita). Por exemplo, um caso comum: ADF não rejeita H0 (p.ex. p = 0,2) e KPSS rejeita H0 (p < 0,01) – interpretação: há forte evidência de não-estacionariedade (raiz unitária presente). Por outro lado, se ADF rejeita e KPSS não rejeita, temos evidência consistente de estacionariedade. Se ambos não rejeitam seus respectivos H0, a situação é ambígua (pode indicar poucos dados ou processo quase integrado).
Outros testes e considerações: Existem outros testes de raiz unitária, como o Phillips-Perron (PP), que é parecido com ADF mas usa uma correção não-paramétrica para autocorrelação e heterocedasticidade nos resíduos (útil se os erros não são independentes e identicamente distribuídas - iid). O teste DF-GLS é uma variação do Dickey-Fuller com pré-estruturação via GLS que melhora a potência. Para sazonalidade, há testes de raiz unitária sazonais (Hegemony test, por ex.). Além disso, testes como Zivot-Andrews permitem uma quebra estrutural na tendência sob H1, tentando captar séries que são estacionárias com uma mudança de nível única. Nenhum teste isolado é perfeito – por isso analistas olham gráficos, ACF/PACF e aplicam múltiplos testes.
No que apresentaremos a seguir, o script usa o ADF como critério simples (nível de 5%) para decidir estacionariedade. Essa abordagem é prática, embora careça das sutilezas de considerar diferentes tipos de não-estacionariedade (por exemplo, o ADF pode deixar passar uma série estacionária em torno de tendência – que tecnicamente tem raiz unitária? – ou acusar não-estacionária uma série com break). Portanto, no uso manual, recomenda-se sempre complementar ADF com inspeção visual e eventualmente um KPSS: uma “regra geral” frequentemente citada é ADF e KPSS juntos para conclusão robusta. Lembrando: p-valor ADF baixo e KPSS alto = estacionária; ADF alto e KPSS baixo = não estacionária; demais combinações = inconclusivo ou requer análise de tendência determinística.
Em resumo, os testes estatísticos ajudam a decidir quantitativamente se já alcançamos estacionariedade após certas transformações. Entretanto, devemos entender suas hipóteses e limitações para interpretá-los corretamente. No processo de tornar a série estacionária, aplicamos transformações e então verificamos com ADF/KPSS: se ainda não satisfaz, iteramos (por exemplo, tomar segunda diferença se necessário). Mas cuidado para não “super-diferenciar”: uma vez estacionária, diferenças adicionais introduzem autocorrelação negativa e complexidade desnecessária.
Automatizando a estacionarização: script stationarity_processor.py
Para facilitar o trabalho de aplicar as transformações corretas em cada série, podemos automatizar o processo de detecção de não-estacionaridade e aplicação de transformadores. Todo o código aqui utilizado está disponívem no repositório: pq_sidra_stationary
O script python stationarity_processor.py implementa uma solução desse tipo, integrando com a biblioteca sktime (voltada a aprendizado de máquina em séries temporais) para criar um transformer customizado. A seguir, é explicado em detalhes o que o script faz, incluindo sua estrutura, funções auxiliares, lógica de seleção de transformações e como ele lida com múltiplas séries (multivariadas) evitando vazamento de informação.
Visão geral e estrutura do código
O stationary_processor.py define primeiramente funções auxiliares de verificação e fábricas de transformadores, depois a função principal de seleção e, por fim, uma classe StationarityTransfomer que reúne tudo isso. Assim, a estrutura lógica é:
Funções de verificação (diagnóstico):
check_stationarity(series): aplica o teste ADF na série e retorna True/False indicando se rejeitou a hipótese de raiz unitária. Essencialmente, check_stationarity = (ADF p-value < 0,05).
check_seasonality(series, seasonality=12): verifica se há sazonalidade significativa de período dado (padrão 12). Internamente, realiza uma decomposição STL (Seasonal and Trend decomposition using Loess) separando o componente sazonal, e então aplica um teste não-paramétrico de Kruskal-Wallis para ver se há diferença estatisticamente significativa entre as medianas dos subperíodos sazonais. Além disso, calcula a força da sazonalidade como a razão da variância do componente sazonal pela variância total da série. Se o padrão sazonal explica mais que ~10% da variância (limiar heurístico) e o teste Kruskal-Wallis indica diferenças significativas (p < 0.05) entre meses, conclui-se que a série tem sazonalidade presente. Essa combinação de critérios evita marcar como “sazonal” séries onde a sazonalidade é fraca ou os dados são insuficientes (note que o código retorna False se a série for muito curta, < 2 períodos).
check_proportional_variance (series): verifica indícios de heterocedasticidade multiplicativa, isto é, se as variações absolutas da série aumentam proporcionalmente ao nível. A implementação calcula |Yt - Y{t-1}| (módulo das primeiras diferenças) e faz uma regressão linear desses valores em função do nível médio (Yt - Y{t-1})/2 ou equivalente. Se a inclinação dessa regressão for positiva e estatisticamente significativa (teste t bicaudal p<0,05, considerando metade p/1 cauda), assume-se que a variância cresce com o nível da série – ou seja, seria benéfico um log ou transformação de potência. Em termos simples, essa função retorna True se detectar que a série possui variância não constante proporcional ao valor (por exemplo, série de vendas onde dias de vendas altas têm variação maior em valor absoluto do que dias de vendas baixas).
Essas funções de diagnóstico permitem ao código decidir quais transformações aplicar sem intervenção humana. Por exemplo, check_seasonality identifica sazonalidade anual, evitando diferenciar desnecessariamente séries que não a possuem; check_proportional_variance identifica a necessidade de estabilizar variância via log.
Fábricas de transformers: Para cada tipo de transformação potencial, o script define uma função que retorna um objeto transformador compatível com sktime:
passthrough_transformer(): simplesmente retorna um Transformer identidade (nenhuma transformação) – no caso, usa Id() de sktime.
delta_transformer(): retorna um Differencer(lags=1), que calcula a diferença de primeira ordem.
delta_delta_transformer(): retorna um Differencer(lags=[1,1]), efetivamente aplicando duas diferenças consecutivas (equivalente à segunda diferença).
delta_seasonal_transformer(seasonality=12): retorna um Differencer(lags=seasonality), ou seja, diferença sazonal de período 12 (padrão mensal).
delta_seasonal_delta_transformer(seasonality=12): retorna um Differencer(lags=[1,12]). Essa configuração fará primeiro uma diferença sazonal e depois uma diferença normal no resultado, combinando ambas (na prática é semelhante a aplicar Ds=1 e d=1 no contexto ARIMA.
ln_transformer(): retorna um LogTransformer() de sktime, que aplica ln(x) e é inversível (pois sktime guarda os valores transformados para permitir a inversa exatamente).
delta_ln_transformer(): combina log + diferença: é implementado como um TransformerPipeline contendo primeiro um log e depois um differencer de lag=1.
delta_delta_ln_transformer(): similar, mas após o log aplica duas diferenças sucessivas.
As fábricas acima servem para instanciar novos transformadores sob demanda. Isso é importante porque, ao testar múltiplas transformações, queremos instâncias separadas (por exemplo, aplicar duas vezes o mesmo Differencer pode ser problemático se ele mantém estado interno após um fit). No código, chamam-se essas funções para gerar transformers próprios para uso em pipeline cada vez em que for necessário testar uma transformação candidata.
Seleção do transformer adequado (select_transformer): Esta é a função-chave que decide qual transformação usar para uma dada série. Ela realiza os seguintes passos:
Limpeza básica: Converte a série para numérico ignorando erros e remove valores NaN ou infinitos. Se após limpeza a série estiver vazia, retorna imediatamente um passthrough.
Checagem inicial de estacionariedade: Aplica check_stationarity na série bruta. Se já for estacionária (p-valor ADF < 0,05), não há necessidade de transformação – retorna o transformador de identidade (passthrough). Dessa forma, evita transformar séries que já estão boas.
Construção da lista de candidatos: Inicialmente a lista é vazia. Depois, condicionalmente:
Se check_seasonality indicar sazonalidade, adiciona transformadores de diferença sazonal às opções. Primeiro adiciona ('ΔSazonal', delta_seasonal_transformer) e em seguida ('ΔSazonalΔ', delta_seasonal_delta_transformer) na lista. A presença de sazonalidade sugere fortemente que alguma diferenciação sazonal será necessária, por isso essas vêm com alta prioridade.
Em seguida, verifica heterocedasticidade: se check_proportional_variance for True, significa variância proporcional ao nível. Nesse caso, se todos os valores da série forem positivos (is_positive), adiciona transformações envolvendo log: ('ln(x)', ln_transformer), ('Δln(x)', delta_ln_transformer) e ('ΔΔln(x)', delta_delta_ln_transformer). Se a série não for positiva, o código apenas imprime um aviso e não adiciona transformações.
Independente dos casos anteriores, o código sempre adiciona algumas transformações genéricas de diferenciação no final: ('Δx', delta_transformer) e ('ΔΔx', delta_delta_transformer). Essas representam a diferença simples e dupla, que servem como “coringa” caso nenhuma das específicas tenha funcionado. Por fim, adiciona ('Passthrough', passthrough_transformer) como último recurso. Assim, mesmo que nada dê certo, o fallback é não transformar (embora isso signifique que a série permanecerá não estacionária).
Teste de cada candidato: Depois de montar a lista, a função itera na ordem sobre cada candidato. Para cada transformador candidato, aplica a função auxiliar transform_and_check(series, transformer). Esta função interna faz fit e transform na série, e depois roda check_stationarity no resultado. Ou seja, testa “se aplicarmos esta transformação, a série fica estacionária?”. Se sim, transform_and_check retorna True. O loop então seleciona essa transformação e o script imprime no console qual transformador está sendo testado e qual foi selecionado para transparência durante a execução.
Retorno do transformer selecionado: Ao encontrar o primeiro candidato satisfatório, a função select_transformer retorna uma nova instância do transformer correspondente (usando novamente a fábrica para evitar efeitos colaterais). A ordem de prioridade é importante: por exemplo, se sazonalidade for detectada, ΔSazonal será testado antes de um possível Δln. Isso reflete a heurística de aplicar diferenças sazonais antes de outras transformações, conforme discussão anterior. Caso nenhum candidato resulte em estacionariedade (situação rara se cobrimos as principais causas de não-estacionariedade), a função recorre ao passthrough.
Em resumo, select_transformer condensa a lógica de decisão: primeiro verifica se precisa de algo; se sazonal, tenta resolver por aí; se variância não constante, tenta log; sempre tenta diferenças simples e duplas; e escolhe a primeira transformação que “achata” a série (no sentido de estacionariedade em média).
Classe StationarityTransformer: Esta classe herda de sktime.transformations.base.BaseTransformer e encapsula o comportamento de aplicar select_transformer em cada coluna de um DataFrame. Vamos detalhar seus métodos principais:
__init__(self, seasonality=12): Inicializa o objeto transformador com um período sazonal padrão (12, mensal). Também prepara um dicionário columns_transformers_ para armazenar o transformador escolhido de cada coluna.
_fit(self, X): Durante o ajuste (fit) nos dados, o transformador percorre cada coluna de X. Para cada coluna, ele chama select_transformer na série univariada daquela coluna. O transformador retornado é então ajustado (fit) nessa série e guardado em columns_transformers_[col]. Ou seja, ao final do fit, temos para cada coluna uma transformação aprendida. Importante: antes do loop, o código remove colunas completamente vazias (NaN) para evitar problemas. Além disso, envolve o processo em um try/except – se por algum motivo o fit de um transformador falhar, ele registra um aviso e usa Passthrough naquela coluna. Na prática, isso garante robustez: mesmo se uma transformação exoticamente não funcionar nos dados (por exemplo, log de valores negativos inesperados), ele não quebra o pipeline inteiro.
_transform(self, X): Aplica as transformações nas séries conforme ajustado. Para cada coluna, pega o transformador em columns_transformers_ e executa transform naquela coluna. Se alguma transformação falhar aqui (pouco provável se já funcionou no fit), também há tratamento de exceção para retornar os dados originais daquela coluna e notificar. O resultado é um novo DataFrame com cada coluna transformada de forma a (esperançosamente) ser estacionária. Os índices de tempo são preservados.
Este método permite reverter as transformações aplicadas, recuperando aproximadamente o nível original das séries. Para cada coluna, verifica se o transformador armazenado possui o método inverse_transform (os Differencer e LogTransformer do sktime o possuem). Se sim, aplica-o; se não, simplesmente retorna os dados como estão, pois não é possível inverter (caso do Id ou outros sem inversa). Isso é importante para interpretar previsões: por exemplo, se um modelo previu valores transformados (diferenciados ou log-ados), podemos inverter essas transformações para obter previsões na unidade original. O StationarityTransformer cuida para armazenar tudo necessário (p.ex., o Differencer no sktime armazena internamente o último valor original para reverter a diferença). Assim, podemos integrar este transformer em um pipeline de forecast e, após prever na escala estacionária, aplicar .inverse_transform() para voltar à escala original dos dados.
A classe define também alguns tags internos do sktime para indicar que opera por série e que suporta inversa, etc., mas isso é detalhe de implementação.
Em resumo, a classe permite que passemos um DataFrame com várias colunas (potencialmente correspondendo a diferentes indicadores temporais), e ele automaticamente decide e aplica a melhor transformação em cada uma de forma independente. Essa independência por coluna é crucial para evitar vazamento de dados: cada série é transformada usando apenas informações dessa própria série. Não há mistura de informações entre colunas no ajuste das transformações. Por exemplo, se tivermos uma coluna de inflação e outra de produção industrial, o StationarityTransformer garantirá que a transformação escolhida para inflação dependa apenas do comportamento da inflação histórica – não “espiando” a produção – e vice-versa. Isso impede que características de uma série influenciem indevidamente a transformação de outra (o que seria um leak de informação se acontecesse). Além disso, em um cenário de modelagem preditiva, usar essa classe dentro de uma Pipeline de treinamento/teste assegura que as transformações de cada série sejam fitadas apenas nos dados de treino daquela série, e depois aplicadas nos dados de teste, mantendo o princípio de não olhar o futuro. O próprio design do fit/transform do sktime já segrega bem essas etapas.
Execução Principal: Na parte final do script (dentro do if __name__ == "__main__":), está um exemplo de uso em que são carregados dados do arquivo Excel sidra_data.xlsx (dados do IBGE), aplicado o StationarityTransformer e salvas as séries estacionárias resultantes em stationary_data.xlsx. Durante essa execução, o script imprime no console quais transformers foram selecionados para cada coluna, incluindo detalhes dos passos (por exemplo, se foi um Pipeline, lista o conteúdo: log -> diff, etc.; se foi um Differencer, informa o lag usado). Essa saída nos fornece exatamente quais transformações foram escolhidas para cada série real.
Exemplo: transformações selecionadas para séries do IBGE
Para ilustrar, aplicamos o script a séries extraídas da SIDRA/IBGE referentes à produção industrial, comércio e preços. A tabela abaixo apresenta as transformações selecionadas automaticamente pelo StationarityTransformer:
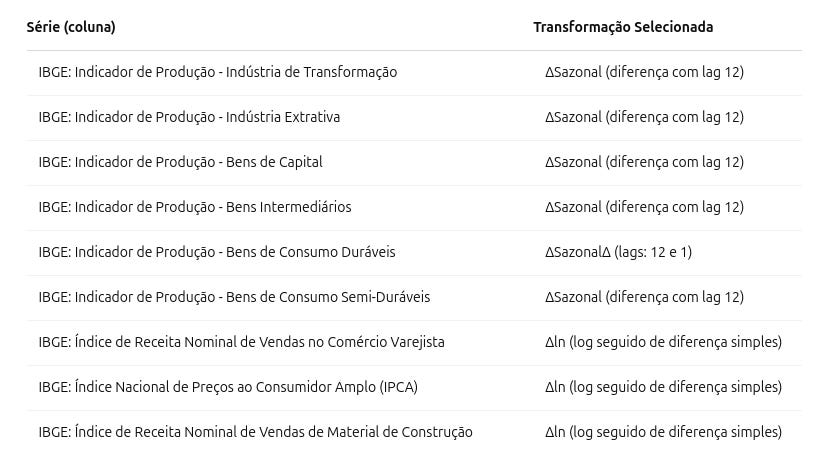
Tabela 1: Transformações selecionadas automaticamente pelo script. ΔSazonal indica uso de diferenciação com lag 12; ΔSazonalΔ aplica diferença com lag 12 e depois 1; Δln representa uma transformação composta de log e diferença.
Essas transformações refletem padrões típicos de séries econômicas mensais. Por exemplo, todas as séries de produção industrial exibiram forte sazonalidade, justificando o uso de diferença sazonal. A série de bens de consumo duráveis demandou uma diferenciação adicional após a sazonal, indicando presença de tendência residual. Já as séries nominais (comércio, IPCA e material de construção) apresentaram variância proporcional ao nível, o que motivou a transformação logarítmica, seguida de diferenciação para remover tendência.
Ao final do processo, obtêm-se séries com média e variância mais estáveis, facilitando a modelagem preditiva e a análise estatística. Como cada transformação é escolhida individualmente para cada coluna com base em testes (ADF, Kruskal-Wallis, regressão de variância), a abordagem se adapta automaticamente à natureza estatística de cada variável.
Impacto das transformações na estabilidade e modelagem
Após aplicarmos as transformações adequadas, obtemos séries estacionárias ou muito mais próximas disso. Quais os benefícios concretos?
Estabilidade da média e variância: As séries transformadas flutuam em torno de um nível aproximadamente constante, o que significa que quaisquer previsões produzidas por modelos treinados nesses dados não serão tendenciosamente baixas ou altas ao longo do tempo (como seriam se a série tivesse uma tendência ascendente, por exemplo). A variância constante facilita métodos que assumem homocedasticidade. Em modelos lineares, isso evita violações de pressupostos; em modelos de ML, evita que certas épocas dominem o erro quadrático apenas por estarem em um nível mais alto.
Melhor identificação de padrões autocorrelacionados: Com a série estacionária, padrões de autocorrelação ficam mais claros nas funções ACF/PACF, guiando a escolha de modelos ARIMA (identificação de ordens p, q) ou mesmo facilitando técnicas de feature engineering (lags relevantes) para modelos de machine learning. Componentes como tendências e sazonais, que podiam mascarar ou produzir autocorrelações espúrias, já foram removidos. Assim, o modelo pode se concentrar em relações mais sutis, como ciclos econômicos ou dependências de curto prazo.
Modelos lineares mais precisos: Modelos ARIMA e de regressão exigem estacionariedade para que os parâmetros estimados permaneçam válidos no futuro. Após as transformações, podemos ajustar um ARIMA ou um SARIMA apropriado e esperar resíduos não autocorrelacionados (um bom sinal). Do contrário, sem estacionarizar, um AR(1) em uma série com tendência provavelmente deixaria resíduos altamente estruturados e previsões sistematicamente desviadas. Em termos de validação, uma série estacionária tende a produzir intervalos de previsão confiáveis – por exemplo, o intervalo de confiança de 95% de um ARIMA permanece aproximadamente constante ao longo do horizonte quando a série é estacionária, enquanto se houvesse uma raiz unitária, a incerteza cresceria com o horizonte (o famoso leque que abre ao prever um passeio aleatório).
Facilidade de aprendizado para modelos de ML/DL: Embora algoritmos como redes neurais possam em teoria lidar com dados não estacionários, na prática a ausência de grandes tendências ou sazonalidades explícitas significa que eles podem focar em aprender as dinâmicas de curto prazo e as relações com variáveis exógenas, em vez de gastar capacidade de modelagem aprendendo a reproduzir um comportamento trivial (como “está subindo 100 unidades por período”). Isso pode melhorar a velocidade de convergência e a generalização. Além disso, remover tendências evita o problema de valores fora da faixa de treino: por exemplo, uma rede treinada em valores de uma série entre 100 e 500 pode ter dificuldade em extrapolar para 1000, mas se ela for treinada na série diferenciada, está sempre prevendo variações em torno de números menores e comparáveis (e depois, ao integrar as previsões, recupera-se o nível).
Comparabilidade de colunas e combinação de modelos: Numa tarefa multivariada, transformar todas as séries para estacionárias também coloca as variáveis em condições comparáveis. Por exemplo, se vamos treinar um modelo VAR (Vector Auto Regression) ou rede multivariada com várias séries econômicas, todas devem ser estacionárias para evitar instabilidade (no caso do VAR, a condição de estacionariedade garante que os coeficientes estimados caibam na definição de um processo estacionário). O StationarityTransformer trata cada coluna, garantindo essa propriedade globalmente.
Melhoria na performance de previsão: Em termos de métricas de erro, frequentemente observa-se melhora após estacionarizar adequadamente. Isso ocorre porque o modelo consegue capturar melhor a estrutura da série. Por exemplo, ao modelar a inflação (diferença do log do índice de preços), um modelo pode prever “próximo mês sobe +0.1%” com erro pequeno, enquanto modelar o índice de preços bruto implicaria prever “vai de 210,5 para 212,8”, carregando a tendência e acumulando erro. Claro, o passo de voltar à escala original (fazendo somas cumulativas das diferenças ou exponenciação dos logs) reintroduz a tendência na previsão final, mas agora baseada em previsões incrementais que tendem a acertar melhor a variação local.
É importante destacar que, depois de modelar e fazer previsões nas séries estacionárias, devemos inverter as transformações para interpretar os resultados no mundo real. O StationarityTransformer facilita isso via inverse_transform. Ao reverter, quaisquer erros do modelo em captar pequenas variações se acumulam; portanto, a qualidade do modelo estacionário se reflete na precisão após a inversão, mas de forma controlada. Modelos bem ajustados em diferenças resultam em previsões originais que seguem a tendência correta e capturam pontos de virada melhor do que modelos ajustados diretamente nos dados não estacionários.
Por fim, vale lembrar que nem sempre todas as transformações são necessárias – algumas séries podem já ser estacionárias ou quase (por exemplo, taxas de crescimento econômico ano a ano geralmente não têm raiz unitária). Nesses casos, aplicar transformações desnecessárias pode introduzir ruído. Por isso, o processo de estacionarização deve ser guiado por diagnóstico cuidadoso (como o realizado no script com testes estatísticos) e validar que a série resultante faz sentido. A abordagem automatizada aqui descrita (e implementada no StationarityProcessor) atua como um bom ponto de partida, aplicando sistematicamente as técnicas consagradas na literatura para tornar séries estacionárias.
Até a próxima!